
シニアだけどStable Diffusion使えこなせそうかも

どうも、駆け出しシニアのHot3DegC(ホットサンド)です。
ChatGPTからDALL-E3を利用していたのですが、画像生成時のプロンプトを出来るだけ削減したいと思って、最近はStable Diffusionを勉強していることが多くなってきました。
少しづつプロンプトやパラメータを変えて結果を見るいわゆるトライアル&エラー方式で進めているため、あっという間に時間がたっており気づいたら深夜になってたりしてます。
今日は、これからStable Diffusionにチャレンジしてみようと考えている方に向けて、私が最初の頃に少し躓いてしまったことについて書いてみたいと思います。
◆◇◆◇◆◇◆◇◆◇◆◇◆◇◆◇◆◇◆◇◆◇◆◇◆◇◆◇◆◇◆◇◆◇
最初の過ち
ええ、ChatGptがあれだけ簡単に利用出来ているし、思い描いた結果が得られていたので、Stable Diffusionも簡単に使いこなせると思い込んでおりました。
そうです!呪文(プロンプトのこと)とネガティブプロンプトを入力するだけで、思いのままに絵心のない私にも素敵なイラストを生成出来ると思いこんでいた大バカやろうなシニアです。
Stable Diffusionをインストールして、初期パラメータのまま何も変更せずに呪文(プロンプト)欄に一言入力して生成をしてみて、無事に画像が生成されることを確認したら、「森にたたずむ冒険者っぽい可愛い少女のアニメイラスト」を生成して「シニアだけどファンタジー小説が好き」って記事のイメージにしよう……
プロンプトをアレコレ変更しては生成してを繰り返すこと2時間
いっこうに実写でリアルな外国のおねーさんしか生成されません!!

こ、これは、おかしい!!
何かが違っている……。
試しにChatGPTのDALL-E3に同じプロンプトでイラストを生成してもらうと

イメージしているとおりのイラストが生成してくれるのだけど、なんでこんなに違うの!?
その後も2時間ほどパラメータをイジってみたり、サンプリングメソッドをイジってみたりしてみたけど、いっこうにアニメ風のイラストになりません。
何かやらかしている気がする……
少し冷静になって振り返ってみようとChatGptにStable Diffusionのことを聞いてみました。

なになに、「Stable Diffusionは、テキストから画像を生成することができる拡散モデルベースの画像生成AIです。このモデルは...」
拡散モデル、拡散モデル、拡散?モデル?、Diffusionモデルだよね、Diffusionモデル、Diffusion、モデル…
ということは
そもそもアニメ系のテイストを得意とする学習済みモデルに切り替えれば早くない?課題解決するよね?
ってところで、現状でどのようなモデルが設定されているのか、アニメ系のテイストに強いモデルはどでなのかなどを調べていくこと小一時間。

解決しました!!
瞬殺でした。
呪文(プロンプト)そのままでイメージどおりの可愛いイラストが出来ました!!
ネガティブプロンプトとかにも色々と記述して改善されなかったのが、モデルを変更して呪文(プロンプト)だけで、簡単にイメージどうおりのイラストが生成されました。
で、このまま出解決しましたでは、あまりにもお粗末なので、モデルや同時に追加設定したVAEの設定について触れておこうと思います。
◆◇◆◇◆◇◆◇◆◇◆◇◆◇◆◇◆◇◆◇◆◇◆◇◆◇◆◇◆◇◆◇◆◇
アニメ系テイストに強いモデルの追加設定
モデルは、『HuggingFace』やモデルファイルを集めたサイト『civitai』からダウンロードしてきます。
私は、あまり画像生成系のモデルには詳しくはないので、視覚的にモデルを選択しやすい『civitai』から取得してきました。
こちらの紹介は、おいおい紹介出来ればと思いますが、今回は割愛させていただきます。
手に入れたのは、「Anything v5」というアニメ系美少女や風景イラストの生成に特化したモデルです。
モデルをダウンロードしたら、下記のフォルダに配置して、
C:\Users$username\AppData\Local\stable-diffusion-webui\models\Stable-diffusionStable Diffusionの画面左上からプルダウンでダウンロードしたモデルを選択します。
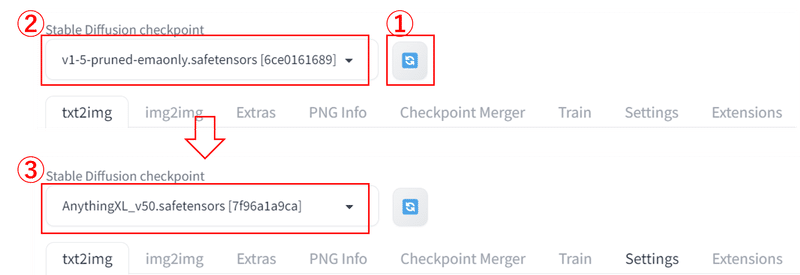
モデルの保存先さえ間違わなければ、迷うことはないと思います。
あとは、呪文(プロンプト)にイメージを入力して、生成ボタンを押すだけで、先程のようなイラストが生成されます。
◆◇◆◇◆◇◆◇◆◇◆◇◆◇◆◇◆◇◆◇◆◇◆◇◆◇◆◇◆◇◆◇◆◇
ついでにVAE (Variational Autoencoders)も追加設定
軽く調べてみた結果、VAE(Variational Autoencoders)は、エンコーダとデコーダの二つのコンポーネントを持っており、入力画像を潜在空間にエンコードした後、その潜在空間にエンコードした画像を再構成(デコード)するらしく……画像の潜在的な特徴を捉えることができて、この捉えた潜在的な特徴を用いて新しい画像を生成するらしいとのことで、何やら良いことづく目な気がするので、ついでに設定しちゃいました。
こちらは、設定がメイン画面では行えず、Settingsタブから行うようだったので、こちらも紹介しておきます。
あと、調べたらVAEも色々あって、それぞれに特徴があるみたいだったのですが、手っ取り早くや解決させたかったので、あるサイトでオススメされたいた「vae-ft-mse-840000-ema-pruned」というVAEモデル?をHuggingFaceからダウンロードシてきました。
ダウンロード後は、こちらもStable Diffusionの下記フォルダに配置して、Settingsタブからセッティングします。
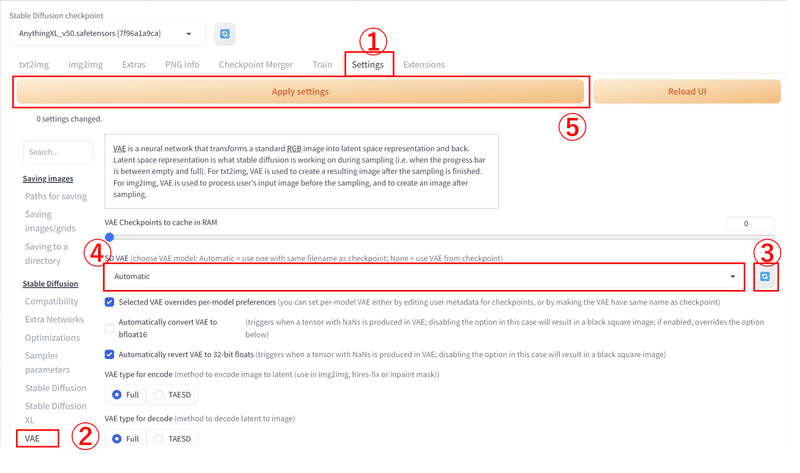
C:\Users\$username\AppData\Local\stable-diffusion-webui\models\VAE画像が小さくてわかりづらいかもしれませんが、『Setttings』タブを押したあと、左メニューから『VAE』を選択して、中央にある『SD VAE』項目の右端にある『SD VAE:refresh』ボタンをおして、ボタンの左隣のプルダウンメニューからダウンロードしたVAEモデル?を選択します。
最後に一番大事な画面上部にある『Apply setteings』ボタンを押して、設定内容を反映します。
このボタンを押さないと設定が反映されませんので、お気をつけ下さい。
◆◇◆◇◆◇◆◇◆◇◆◇◆◇◆◇◆◇◆◇◆◇◆◇◆◇◆◇◆◇◆◇◆◇
最後まで読んでいただき有難うございました。
この体験は、少し過去のことなのですが当時はまだnoteを始めてなくて、どんな記事を書こうかとアイデアを貯めていた時で、環境周りや設定値も当時と違っていて画像などを取り直したりしたので、若干おかしなことになっている部分もあるかもしれませんがお許しください。
この記事を書いているときに、職場で経験が未成熟な若手に業務を教えてる際に、常に「自力で進めて改善しない場合は、すぐに相談しに来てね」って言っていたのを思い出して、思い込みや慢心から力ずくで課題解決に向かって少々無駄な時間を費やしたと反省しております。
30分もしてダメなら現状分析なり調査に切り替える!!
皆さんも同じように足踏みする時があると思いますが、そんな時ほど冷静になって一息入れてネット検索なりChatGPTさんなりに相談してみることをオススメします。
案外、その方が早く課題解決に向かうものですよ。
では、本当に最後まで読んでいただき有難うございました。
まだまだ、記事にしようと思っていたネタがありますので、無理なく無駄なく発信出来るように取り組んでいきますので、引き続き応援のほど宜しくお願いします。
よろしければサポートお願いします!頂いたサポートは記事テーマのツールやアプリの購入費に使わせていただきます!レビュー希望のツールなどあればコメント頂けると嬉しいです。