
LlamaIndex と LLM オーケストレーションフレームワークの世界 - The New Stack - June 6, 2023

Clip source: LlamaIndex and the New World of LLM Orchestration Frameworks - The New Stack
この記事は、LlamaIndexという新しいLLM(Large Language Model)オーケストレーションフレームワークに焦点を当てています。LlamaIndexは、OpenAIのGPTなどのLLMと独自のデータをプログラム的に結合する能力を提供する新しいツールです。このフレームワークは、開発者がLLMをファインチューニングする必要をなくし、長いプロンプトも不要にします。
LlamaIndexは、Andreessen Horowitz(a16z)によって、LangChainと並ぶ新しいカテゴリー、すなわち「オーケストレーションフレームワーク」として位置づけられています。これらのフレームワークは、プロンプトの連鎖の多くの詳細を抽象化し、アプリケーションとLLM間でのデータのクエリと管理を容易にします。これには、外部APIとのインターフェース、ベクターデータベースからの文脈データの取得、複数のLLM呼び出しにわたるメモリの維持も含まれます。
LlamaIndexの主要な機能は、独自のカスタムデータとLLMを結合できる点です。これは「インコンテキスト学習」としても知られています。LlamaIndexは、Google Docs、SQLデータベース、PDFファイルなど、さまざまなデータソースをパースする「データローダー」を提供しています。このデータローダーは、LlamaHubというライブラリで管理され、LangChainとも互換性があります。
LlamaIndexのクエリプロセスは、Retrievers、Response Synthesizer、Query Engineの3つの主要なコンポーネントで構成されています。Retrieversは、クエリに基づいてインデックスからノードのセットを取得します。Response Synthesizerは、これらのノードを使用してクエリに対する応答を合成します。Query Engineは、クエリを受け取り、Responseオブジェクトを返します。これにより、LlamaIndexはLLMに関連する情報を効率的にフィードできます。
LlamaIndexはまた、LangChainと連携して「コンテキスト拡張型チャットボット」を構築する方法も提供しています。LangChainは基本的なエージェント/チャットボットの抽象化を担当し、LlamaIndexはデータの取得/検索/クエリを行います。
結論として、LlamaIndexはLangChainとは異なり、よりデータ管理に特化したフレームワークです。しかし、その美点はLangChainと互換性があり、競合ではなく補完関係にあるということです。
要点:
LlamaIndexは、LLMと独自のデータをプログラム的に結合する新しいフレームワーク。
ファインチューニングや長いプロンプトは不要。
Andreessen Horowitz(a16z)は、LlamaIndexとLangChainを「オーケストレーションフレームワーク」として位置づけ。
外部API、ベクターデータベースとのインターフェースも容易。
クエリプロセスは、Retrievers、Response Synthesizer、Query Engineの3つのコンポーネントで構成。
LangChainとの互換性もあり。
LlamaIndex and the New World of LLM Orchestration Frameworks
We take a look at LlamaIndex, which allows you to combine your own custom data with an LLM — without using fine-tuning or overly long prompts.
Jul 6th, 2023 6:47am by Richard MacManus

What if you could combine your own private data store with a large language model (LLM) like OpenAI’s GPT, and query it programmatically? That’s the promise of LlamaIndex, a new framework that helps developers avoid fine-tuning and overly long prompts. It’s part of an emerging category of LLM application tools that some are calling “orchestration frameworks” — or even more simply, “programming frameworks” for LLMs.
In a recent blog post, the venture capital firm Andreessen Horowitz (a16z) makes the case that both LlamaIndex and LangChain are orchestration frameworks. a16z positions both projects firmly in the center of its “emerging LLM app stack”:
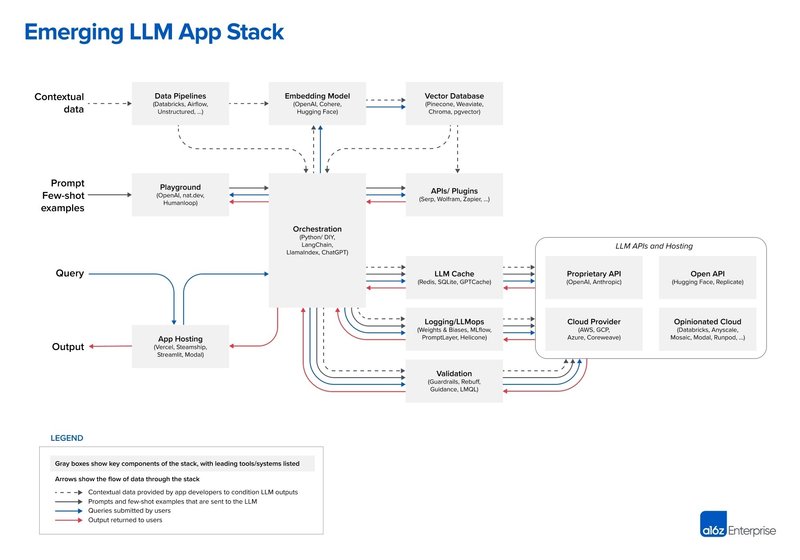
According to a16z, orchestration frameworks like LangChain and LlamaIndex “abstract away many of the details of prompt chaining,” which means querying and managing data between an application and the LLM(s). Included in this orchestration process is interfacing with external APIs, retrieving contextual data from vector databases, and maintaining memory across multiple LLM calls.
LangChain is the leader among orchestration frameworks, says a16z. So what does LlamaIndex offer? Let’s take a look.
How LlamaIndex Works
The key to LlamaIndex is that it allows you to combine your own custom data with an LLM, without using fine-tuning (training the LLM itself) or adding the custom data to your prompt (known as “in-context learning”).
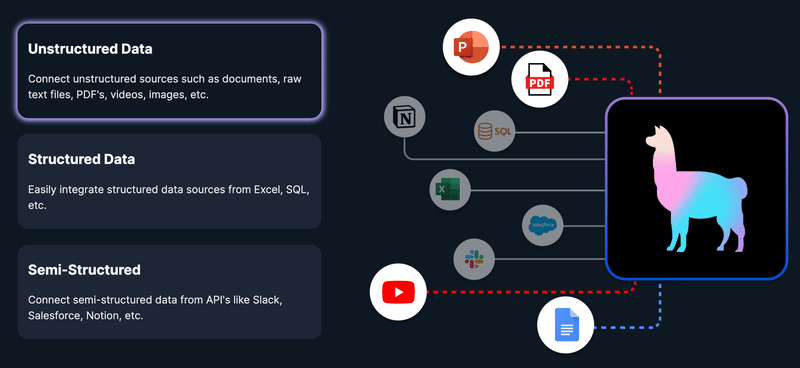
LlamaIndex refers to itself as a data framework. It’s a “simple, flexible data framework for connecting custom data sources to large language models.” It appears to cover just about any type of data too, according to this diagram on its homepage:
As with LangChain, LlamaIndex is still a new and not entirely finished framework. Just this week (on Independence Day, in fact), the project released its 0.7.0 version. According to LlamaIndex creator Jerry Liu, 0.7.0 “continues the theme of improving modularity/customizability at the lower level to enable bottoms-up development of LLM applications over your data.”
Like LangChain, LlamaIndex is almost shockingly new on the scene. It was launched by Liu as an open source project called GPT Index in November last year. Sometime this year, the project name changed to LlamaIndex. Then, again similar to LangChain, Jerry Liu spun the project into a venture-funded company (also named LlamaIndex). This happened just last month when Liu noted that it aimed to “offer a toolkit to help set up the data architecture for LLM apps.”
The key to getting started in LlamaIndex is LlamaHub, which is where data is ingested. Ravi Theja provided this useful diagram in a recent presentation:
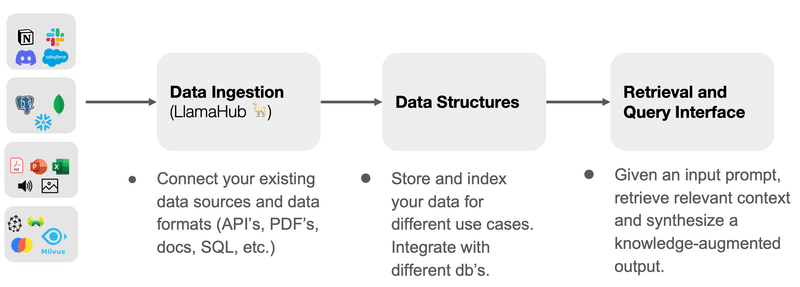
LlamaHub is a library of data loaders and readers. Interestingly, it’s not limited to use with LlamaIndex — it can also be used with LangChain. There are loaders “to parse Google Docs, SQL Databases, PDF files, PowerPoints, Notion, Slack, Obsidian, and many more.”
After the data ingestion stage, there is a typical workflow that users of LlamaIndex follow:
Parse the Documents into Nodes
Construct Index (from Nodes or Documents)
[Optional, Advanced] Building indices on top of other indices
Query the index
The querying part is done by an LLM. Or as the documentation puts it, “a ‘query’ is simply an input to an LLM.” This is where it can get complex, but here’s how the documentation outlines the “query” process:
Querying an index or a graph involves three main components:
Retrievers: A retriever class retrieves a set of Nodes from an index given a query.
Response Synthesizer: This class takes in a set of Nodes and synthesizes an answer given a query.
Query Engine: This class takes in a query and returns a Response object. It can make use of Retrievers and Response Synthesizer modules under the hood.

The simplest explanation I’ve found for the query process is by Owen Fraser-Green, who said that LlamaIndex basically allows you to “feed relevant information into the prompt of an LLM,” only instead of feeding the LLM all of your custom data, “you try to pick out the bits useful to each query.”
In terms of how to do this, there are multiple methods. You can use good old ChatGPT, as this tutorial demonstrates. But also you can use LangChain. LlamaIndex allows you to use any data loader as a LangChain Tool, as well as providing “Tool abstractions so that you can use a LlamaIndex query engine along with a Langchain agent.”
One of the tutorials offered by LlamaIndex shows how to build a “context-augmented chatbot” using both LangChain and LlamaIndex. “We use Langchain for the underlying Agent/Chatbot abstractions, and we use LlamaIndex for the data retrieval/lookup/querying,” the documentation explains.
Conclusion
It’s clear that LlamaIndex is more of a data management framework than the all-purpose framework that LangChain provides. But the beauty of LlamaIndex is that it can be used with LangChain. They’re compatible with each other, not competitive.
Whether or not a16z’s term of “orchestration framework” sticks, one thing is for sure: both LlamaIndex and LangChain are tools that developers should have in their back pocket when working with LLMs.
この記事が気に入ったらサポートをしてみませんか?