
大規模言語モデル(LLM)の性能を向上させるための4つのデータクリーニングテクニック

RAG(retrieval-augmented generation)プロセスは、LLM(large language models)の理解を向上させ、コンテキストを提供し、ハルシネーション)を防ぐ潜在能力から人気を集めています。RAGプロセスには、ドキュメントをチャンク単位で取り込んでコンテキストを抽出し、そのコンテキストでLLMモデルをプロンプトするという複数のステップが含まれます。予測を大幅に改善することが知られている一方で、RAGは時折誤った結果をもたらすことがあります。ドキュメントの取り込み方がこのプロセスで重要な役割を果たします。たとえば、「コンテキストドキュメント」にLLMにとってのタイポや絵文字などの異例の文字が含まれていると、提供されたコンテキストのLLMの理解を混乱させる可能性があります。
この投稿では、LLMによるさらなる処理のためにテキストを取り込んでチャンクに変換する前に、4つの一般的なNLP(natural language processing)テクニックの使用方法を示します。また、これらのテクニックがモデルのプロンプトへの応答を大幅に向上させる方法を説明します。
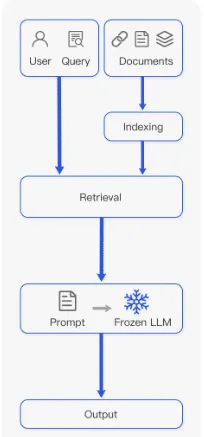
なぜ文書をきれいにすることが重要なのか?
どんな種類の機械学習アルゴリズムにデータを入力する前に、テキストをきれいにすることは標準的な手順です。教師あり学習や教師なし学習を使用しているか、または生成型AI(GAI)モデルの文脈を作成している場合でも、テキストを整えることは以下の点で役立ちます:
精度を確保する: 誤りを取り除き、すべてを一貫させることで、モデルを混乱させる可能性が低くなり、モデルのハルシネーションを引き起こすことも少なくなります。
品質を向上させる: よりきれいなデータは、信頼性のある一貫した情報でモデルが動作することを保証し、正確なデータから推論するのに役立ちます。
分析を容易にする: きれいなデータは解釈しやすく分析しやすいものです。たとえば、平文のテキストで訓練されたモデルは表形式データを理解するのに苦労するかもしれません。
データをきれいにすることにより、特に非構造化データを整えることで、信頼性のある関連する文脈をモデルに提供し、生成を改善し、ハルシネーションの発生確率を減らし、GAIの速度とパフォーマンスを向上させることができます。大量の情報は待ち時間を長くするため、情報量が多いほど待ち時間が長くなります。
データクリーニングをどのように実現するのか?
データクリーニングのツールボックスを構築するために、4つのNLP技術とそれらがモデルにどのように役立つかを探っていきます。
ステップ1:データクリーニングとノイズ削減
まず、スクレイピングの場合のHTMLタグ、XMLパーサ、JSON、絵文字、ハッシュタグなど、意味を持たない記号や文字を削除することから始めます。不要な文字はしばしばモデルを混乱させ、コンテキストトークンの数を増やし、それに伴って計算コストを増加させます。
一つの解決策がすべてに当てはまるわけではないことを認識し、共通のクリーニング技術を使用して異なる問題やテキストタイプに対応します。
トークン化: テキストを個々の単語やトークンに分割します。
ノイズの除去: 不要な記号、絵文字、ハッシュタグ、Unicode文字を排除します。
正規化: 一貫性を持たせるためにテキストを小文字に変換します。
ストップワードの削除: “a,” “in,” “of,” “the”などの一般的または繰り返される意味を持たない単語を破棄します。
・Lemmatizationまたはstemming: 単語を基本形や語幹形に縮約します。
例として、次のツイートを見てみましょう:
“I love coding! #PythonProgramming is fun! ✨ Let’s clean some text ”
この意味は私たちには明確ですが、Pythonで一般的な技術を適用することでモデルのために簡素化しましょう。この投稿内の以下のコードスニペットおよび他のすべてのコードはChatGPTの助けを借りて生成されました。
import re
import nltk
from nltk.tokenize import word_tokenize
from nltk.corpus import stopword
s
from nltk.stem import WordNetLemmatizer
# Sample text with emojis, hashtags, and other characters
text = “I love coding! #PythonProgramming is fun! ✨ Let’s clean some text ”
# Tokenization
tokens = word_tokenize(text)
# Remove Noise
cleaned_tokens = [re.sub(r’[^ws]’, ‘’, token) for token in tokens]
# Normalization (convert to lowercase)
cleaned_tokens = [token.lower() for token in cleaned_tokens]
# Remove Stopwords
stop_words = set(stopwords.words(‘english’))
cleaned_tokens = [token for token in cleaned_tokens if token not in stop_words]
# Lemmatization
lemmatizer = WordNetLemmatizer()
cleaned_tokens = [lemmatizer.lemmatize(token) for token in cleaned_tokens]
print(cleaned_tokens)
# output:
# [‘love’, ‘coding’, ‘pythonprogramming’, ‘fun’, ‘clean’, ‘text’]プロセスは不要な文字を削除し、クリーンで意味のあるテキストを残しました。これにより、モデルが理解できるようになりました:[‘love’, ‘coding’, ‘pythonprogramming’, ‘fun’, ‘clean’, ‘text’]。
ステップ2:テキストの標準化と正規化
次に、常にテキスト全体での一貫性と整合性を重視する必要があります。これは正確な検索と生成を保証するために重要です。次のPythonの例では、スペルミスやその他の不整合をスキャンして、不正確さやパフォーマンスの低下につながる可能性があるものをチェックします。
import re
# Sample text with spelling errors
text_with_errors = “””But ’s not oherence about more language oherence .
Other important aspect is ensuring accurte retrievel by oherence product name spellings.
Additionally, refning descriptions oherenc the oherence of the contnt.”””
# Function to correct spelling errors
def correct_spelling_errors(text):
# Define dictionary of common spelling mistakes and their corrections
spelling_corrections = {
“ oherence ”: “everything”,
“ oherence ”: “refinement”,
“accurte”: “accurate”,
“retrievel”: “retrieval”,
“ oherence ”: “correcting”,
“refning”: “refining”,
“ oherenc”: “enhances”,
“ oherence”: “coherence”,
“contnt”: “content”,
}
# Iterate over each key-value pair in the dictionary and replace the
# misspelled words with their correct versions
for mistake, correction in spelling_corrections.items():
text = re.sub(mistake, correction, text)
return text
# Correct spelling errors in the sample text
cleaned_text = correct_spelling_errors(text_with_errors)
print(cleaned_text)
# output
# But it’s not everything about more language refinement.
# other important aspect is ensuring accurate retrieval by correcting product name spellings.
# Additionally, refining descriptions enhances the coherence of the content.一貫した、整合性のあるテキスト表現により、当社のモデルは正確で文脈に即した応答を生成できるようになりました。このプロセスにより、意味検索も可能となり、特にRAGの文脈において最適なコンテキストチャンクを抽出できます。
ステップ3: メタデータの取り扱い
重要なキーワードやエンティティの特定など、メタデータの収集により、テキスト内の要素を認識し、コンテンツ推奨システムなどの企業向けアプリケーションにおいて特に意味検索結果を改善するために活用できます。このプロセスにより、モデルに追加の文脈が提供され、RAGのパフォーマンスを向上させるためにしばしば必要とされます。このステップを別のPythonの例に適用してみましょう。
Import spacy
import json
# Load English language model
nlp = spacy.load(“en_core_web_sm”)
# Sample text with meta data candidates
text = “””In a blog post titled ‘The Top 10 Tech Trends of 2024,’
John Doe discusses the rise of artificial intelligence and machine learning
in various industries. The article mentions companies like Google and Microsoft
as pioneers in AI research. Additionally, it highlights emerging technologies
such as natural language processing and computer vision.”””
# Process the text with spaCy
doc = nlp(text)
# Extract named entities and their labels
meta_data = [{“text”: ent.text, “label”: ent.label_} for ent in doc.ents]
# Convert meta data to JSON format
meta_data_json = json.dumps(meta_data)
print(meta_data_json)
# output
“””
[
{“text”: “2024”, “label”: “DATE”},
{“text”: “John Doe”, “label”: “PERSON”},
{“text”: “Google”, “label”: “ORG”},
{“text”: “Microsoft”, “label”: “ORG”},
{“text”: “AI”, “label”: “ORG”},
{“text”: “natural language processing”, “label”: “ORG”},
{“text”: “computer vision”, “label”: “ORG”}
]
“””提供されたコードは、spaCyの 固有表現認識機能がテキスト内の日付、人物、組織、およびその他の重要な実体を認識する方法を示しています。これにより、RAGアプリケーションは文脈や単語間の関係をより良く理解することができます。
ステップ4: コンテキスト情報の取り扱い
LLMを扱う際には、さまざまな言語を扱ったり、多様なトピックに満ちた大量の文書を管理したりすることが一般的ですが、これはモデルが理解するのが難しいことがあります。データをより良く理解するための2つのテクニックを見てみましょう。
まずは言語の翻訳から始めましょう。Google翻訳APIを使用して、コードは元のテキスト「Hello, how are you?」を英語からスペイン語に翻訳します。
From googletrans import Translator
# Original text
text = “Hello, how are you?”
# Translate text
translator = Translator()
translated_text = translator.translate(text, src=’en’, dest=’es’).text
print(“Original Text:”, text)
print(“Translated Text:”, translated_text)トピックモデリングは、データのクラスタリングなどの技術を含み、散らかった部屋をきちんとしたカテゴリーに整理するようなものであり、モデルが文書のトピックを特定し、多くの情報を迅速に整理するのに役立ちます。潜在ディリクレ配分(Latent Dirichlet Allocation: LDA)は、トピックモデリングプロセスを自動化するための最も一般的な技術であり、単語のパターンを注意深く見ることでテキスト内の隠れたテーマを見つけるのに役立つ統計モデルです。
次の例では、sklearnを使用して一連の文書を処理し、主要なトピックを特定します。
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import LatentDirichletAllocation
# Sample documents
documents = [
"Machine learning is a subset of artificial intelligence.",
"Natural language processing involves analyzing and understanding human languages.",
"Deep learning algorithms mimic the structure and function of the human brain.",
"Sentiment analysis aims to determine the emotional tone of a text."
]
# Convert text into numerical feature vectors
vectorizer = CountVectorizer(stop_words='english')
X = vectorizer.fit_transform(documents)
# Apply Latent Dirichlet Allocation (LDA) for topic modeling
lda = LatentDirichletAllocation(n_components=2, random_state=42)
lda.fit(X)
# Display topics
for topic_idx, topic in enumerate(lda.components_):
print("Topic %d:" % (topic_idx + 1))
print(" ".join([vectorizer.get_feature_names()[i] for i in topic.argsort()[:-5 - 1:-1]]))
# output
# #Topic 1: #learning machine subset artificial intelligence #Topic 2: #processing natural language involves analyzing understandingもしトピックモデリングのテクニックをもっと探りたいのであれば、以下のものから始めることをお勧めします:
非負値行列因子分解(Non-negative Matrix Factorization: NMF) は、画像など負の値が意味をなさない場合に優れています。明確で理解しやすい要因が必要な場合に便利です。例えば、画像処理では、NMFは負の値の混乱なしに特徴を抽出するのに役立ちます。
潜在的意味解析(Latent Semantic Analysis: LSA) は、複数の文書にまたがる大量のテキストがあり、単語と文書の関連性を見つけたい場合に活躍します。LSAは、特異値分解(SVD)を使用して用語と文書の間の意味的関係を特定し、文書の類似性によるソートや盗作の検出などのタスクを効率化します。
階層ディリクレ過程(Hierarchical Dirichlet Process: HDP) は、膨大なデータを迅速に整理し、文書内のトピックを特定する際に役立ちます。LDAの拡張として、HDPは無限のトピックとモデリングの柔軟性を可能にします。学術論文やニュース記事のトピックの組織を理解するなどのタスクのために、テキストデータ内の階層構造を特定します。
確率的潜在意味解析(Probabilistic Latent Semantic Analysis: PLSA) は、過去の相互作用に基づいて個人に合わせた推薦を提供する推薦システムを構築する際に、文書が特定のトピックに関連している可能性をどの程度示しているかを把握するのに役立ちます。
デモ:GAIテキスト入力のクリーニング
例を挙げて全体像を見てみましょう。このデモでは、ChatGPTを使用して2人の技術者の間で会話を生成しました。この会話に基本的なクリーニング技術を適用して、これらの実践が信頼性のある一貫した結果をもたらす方法を示します。
synthetic_text = """
Sarah (S): Technology Enthusiast
Mark (M): AI Expert
S: Hey Mark! How's it going? Heard about the latest advancements in Generative AI (GA)?
M: Hey Sarah! Yes, I've been diving deep into the realm of GA lately. It's fascinating how it's shaping the future of technology!
S: Absolutely! I mean, GA has been making waves across various industries. What do you think is driving its significance?
M: Well, GA, especially Retrieval Augmented Generative (RAG), is revolutionizing content generation. It's not just about regurgitating information anymore; it's about creating contextually relevant and engaging content.
S: Right! And with Machine Learning (ML) becoming more sophisticated, the possibilities seem endless.
M: Exactly! With advancements in ML algorithms like GPT (Generative Pre-trained Transformer), we're seeing unprecedented levels of creativity in AI-generated content.
S: But what about concerns regarding bias and ethics in GA?
M: Ah, the age-old question! While it's true that GA can inadvertently perpetuate biases present in the training data, there are techniques like Adversarial Training (AT) that aim to mitigate such issues.
S: Interesting! So, where do you see GA headed in the next few years?
M: Well, I believe we'll witness a surge in applications leveraging GA for personalized experiences. From virtual assistants to content creation tools, GA will become ubiquitous in our daily lives.
S: That's exciting! Imagine AI-powered virtual companions tailored to our preferences.
M: Indeed! And with advancements in Natural Language Processing (NLP) and computer vision, these virtual companions will be more intuitive and lifelike than ever before.
S: I can't wait to see what the future holds!
M: Agreed! It's an exciting time to be in the field of AI.
S: Absolutely! Thanks for sharing your insights, Mark.
M: Anytime, Sarah. Let's keep pushing the boundaries of Generative AI together!
S: Definitely! Catch you later, Mark!
M: Take care, Sarah!
"""ステップ1:基本的なクリーンアップ
まず、会話から絵文字、ハッシュタグ、およびUnicode文字を削除しましょう。
# Sample text with emojis, hashtags, and unicode characters
# Tokenization
tokens = word_tokenize(synthetic_text)
# Remove Noise
cleaned_tokens = [re.sub(r'[^ws]', '', token) for token in tokens]
# Normalization (convert to lowercase)
cleaned_tokens = [token.lower() for token in cleaned_tokens]
# Remove Stopwords
stop_words = set(stopwords.words('english'))
cleaned_tokens = [token for token in cleaned_tokens if token not in stop_words]
# Lemmatization
lemmatizer = WordNetLemmatizer()
cleaned_tokens = [lemmatizer.lemmatize(token) for token in cleaned_tokens]
print(cleaned_tokens)ステップ2:プロンプトの準備
次に、私たちはプロンプトを作成し、モデルに合成会話から得た情報に基づいて、フレンドリーな顧客サービス担当者として応答するように求めます。
MESSAGE_SYSTEM_CONTENT = "You are a customer service agent that helps
a customer with answering questions. Please answer the question based on the
provided context below.
Make sure not to make any changes to the context if possible,
when prepare answers so as to provide accurate responses. If the answer
cannot be found in context, just politely say that you do not know,
do not try to make up an answer."ステップ3:インタラクションの準備
モデルとのインタラクションを準備しましょう。この例では、GPT-4を使用します。
def response_test(question:str, context:str, model:str = "gpt-4"):
response = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": MESSAGE_SYSTEM_CONTENT,
},
{"role": "user", "content": question},
{"role": "assistant", "content": context},
],
)
return response.choices[0].message.contentステップ4:質問の準備
最後に、モデルに質問をして、クリーニング前と後の結果を比較しましょう。
question1 = "What are some specific techniques in Adversarial Training (AT)
that can help mitigate biases in Generative AI models?"
クリーニング前に、当社のモデルはこの応答を生成します。
response = response_test(question1, synthetic_text)
print(response) #Output
# I'm sorry, but the context provided doesn't contain specific techniques in Adversarial Training (AT) that can help mitigate biases in Generative AI models.クリーニング後、モデルは以下の応答を生成します。基本的なクリーニング技術によって可能になる理解力の向上により、モデルはより詳細な回答を提供することができます。
AI生成結果の明るい未来
RAGモデルは、関連するコンテキストを提供することで、AI生成結果の信頼性と一貫性を向上させるという利点があります。この文脈付けにより、AI生成コンテンツの精度が大幅に向上します。
RAGモデルを最大限に活用するためには、文書の取り込み中に頑健なデータクリーニング技術が不可欠です。これらの技術は、テキストデータ内の相違点、不正確な用語、およびその他の潜在的なエラーに対処し、入力データの品質を大幅に向上させます。よりクリーンで信頼性の高いデータで操作すると、RAGモデルはより正確で意味のある結果を提供し、さまざまな領域で意思決定と問題解決能力を向上させるAIユースケースを実現します。
この記事が気に入ったらサポートをしてみませんか?