GASスクレイピングに必須! | Html parse ライブラリ

ライブラリの導入
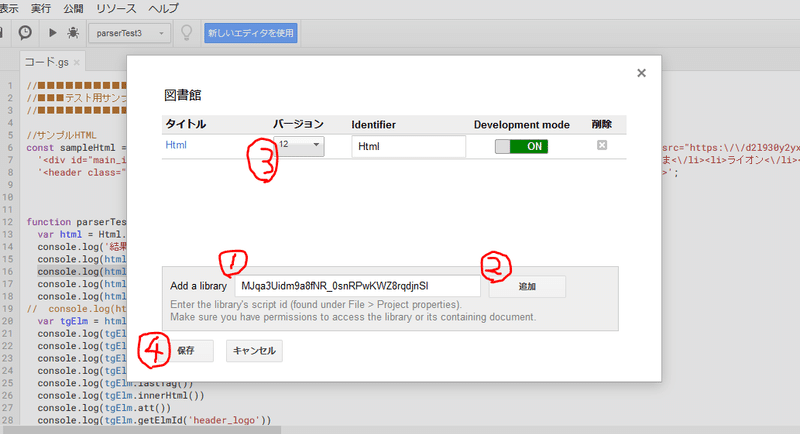
旧エディタの画面から、次のキーでライブラリを導入します。
MJqa3Uidm9a8fNR_0snRPwKWZ8rqdjnSl
※バージョンは12が最新
※ライブラリの導入手順はコチラ
使い方
①まず、UrlFetchApp や PhantomJsCloud などのツールを使って、目的のページのHTMLテキストを取得します。
②HTMLテキストを引数に用いて、Htmlクラスを作成します。
※tree() メソッドを用いれば、全体の構造や、各タグのXPathなどを一覧化したテキストを返してくれるので、③以降に必要な情報が得られます。
※XPathは、chromeブラウザのdeveloper機能でも取得できます。
var html = Html.parse({htmlText}); //Htmlクラスを作成
console.log(html.tree()); //Htmlの構造を調べたり、各タグ(Elementクラス)のXPathなどを調べられます。 ③Htmlクラスのメソッドを使って、目的のElementクラスを取得します。
XPath だけでなく、idやclass属性、タグ名、複数属性のオブジェクトを引数に指定したりして、合致するタグをElementクラスとして取得できます。
//いろんな方法でElementクラスを取得
var elm1 = html.getElmX({XPath}); //XPathから
var elm2 = html.getElmIds({idValue}); //id属性から
var elm3 = html.getElmClasses({clsValue}); //class属性から
var elm4 = html.getElmTags({tagName}); //タグ名から
var elm5 = html.getElmAtts({attObject}); //属性オブジェクトから④Elementクラスのメソッドを使って、そのElementの詳細を取得します。
//Elementクラスの詳細を取得
var tagName = elm1.tag(); //タグ名を取得
var attObj = elm1.att(); //属性をオブジェクトで取得
var innerText = elm1.innerText(); //インナーテキストを取得※各クラスのメソッドの詳細などは、こちらに詳しく紹介されています。
最後に
このライブラリは、HTMLテキストを文字列として操作・抽出するだけでなく、その構造を把握して表示してくれます。そのため全体の構成が把握しやすく、さまざまなアプローチで目的のコンテンツにたどり着けるので非常に使い易くて、おススメです!
この記事が気に入ったらサポートをしてみませんか?