
Python、再び「座標取得とテキスト追加」試してみた。

pip install reportlabimport PyPDF2
from reportlab.lib.pagesizes import letter
from reportlab.pdfgen import canvas
import io
# 元のPDFファイルと新しいPDFファイルのパス
input_pdf_path = 'C:\\Users\\found.pdf'
output_pdf_path = 'C:\\Users\\found2.pdf'
# PDFファイルを開く
with open(input_pdf_path, 'rb') as file:
reader = PyPDF2.PdfReader(file)
writer = PyPDF2.PdfWriter()
# ページごとに処理
for page_num in range(len(reader.pages)):
page = reader.pages[page_num]
# 注釈を追加する位置と内容を指定
x = 551
y = 344
comment = "A-1"
# 注釈を追加する
packet = io.BytesIO()
c = canvas.Canvas(packet, pagesize=letter)
c.drawString(x, y, comment)
c.save()
packet.seek(0)
new_pdf = PyPDF2.PdfReader(packet)
page.merge_page(new_pdf.pages[0])
# 新しいページを書き出し
writer.add_page(page)
# 新しいPDFファイルを保存
with open(output_pdf_path, 'wb') as output_file:
writer.write(output_file)
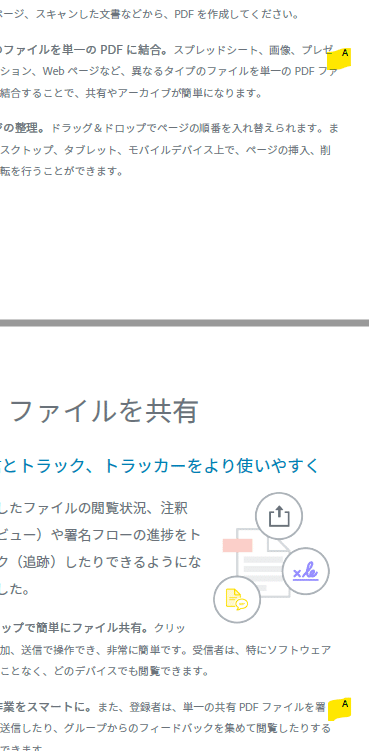
全ページに追加されちゃっています。

X0,X1,Y0,Y1は対角を表しているってこと?
import PyPDF2
from reportlab.lib.pagesizes import letter
from reportlab.pdfgen import canvas
import io
# 元のPDFファイルと新しいPDFファイルのパス
input_pdf_path = 'C:\\Users\\found.pdf'
output_pdf_path = 'C:\\Users\\found_済.pdf'
# 追加する注釈のページ番号
target_page_num = 1 # 2ページ目に注釈を追加する場合は 1 になります
# PDFファイルを開く
with open(input_pdf_path, 'rb') as file:
reader = PyPDF2.PdfReader(file)
writer = PyPDF2.PdfWriter()
# ページごとに処理
for page_num, page in enumerate(reader.pages):
if page_num == target_page_num:
# 注釈を追加する位置と内容を指定
x = 551
y = 344
comment = "A"
# 注釈を追加する
packet = io.BytesIO()
c = canvas.Canvas(packet, pagesize=letter)
c.drawString(x, y, comment)
c.save()
packet.seek(0)
new_pdf = PyPDF2.PdfReader(packet)
page.merge_page(new_pdf.pages[0])
# 新しいページを書き出し
writer.add_page(page)
# 新しいPDFファイルを保存
with open(output_pdf_path, 'wb') as output_file:
writer.write(output_file)

2ページ目にしたいなら、「1」とらしいです。
import PyPDF2
import openpyxl
from reportlab.lib.pagesizes import letter
from reportlab.pdfgen import canvas
# Excelファイルのパス
excel_file_path = 'C:\\Users\\座標2.xlsx'
# Excelファイルを開く
wb = openpyxl.load_workbook(excel_file_path)
sheet = wb.active
# PDFファイルのパス(元のPDFファイル)
input_pdf_path = 'C:\\Users\\found.pdf'
# PDFファイルのパス(コメントが追加された後のPDFファイル)
output_pdf_path = 'C:\\Users\\found_追加済.pdf'
# PDFファイルを開いて注釈を追加
with open(input_pdf_path, 'rb') as input_file:
reader = PyPDF2.PdfReader(input_file)
writer = PyPDF2.PdfWriter()
c = canvas.Canvas(output_pdf_path, pagesize=letter)
# Excelからページ番号、入力文字、X座標、Y座標を取得してPDFに注釈を追加
for row in sheet.iter_rows(min_row=2, values_only=True): # 2行目から読み込みます(1行目はヘッダーなのでスキップ)
page_number, input_text, x, y = row[1:5] # B列からE列までのデータを取得
if input_text is not None:
c.drawString(x, y, str(input_text)) # 注釈を追加。input_textがNoneでないことを確認し、str()関数で文字列に変換します。
c.save()
print("PDFファイルが作成されました。")
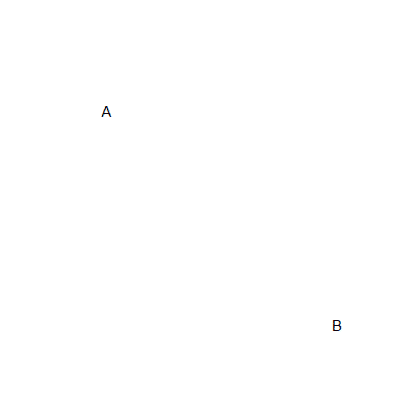
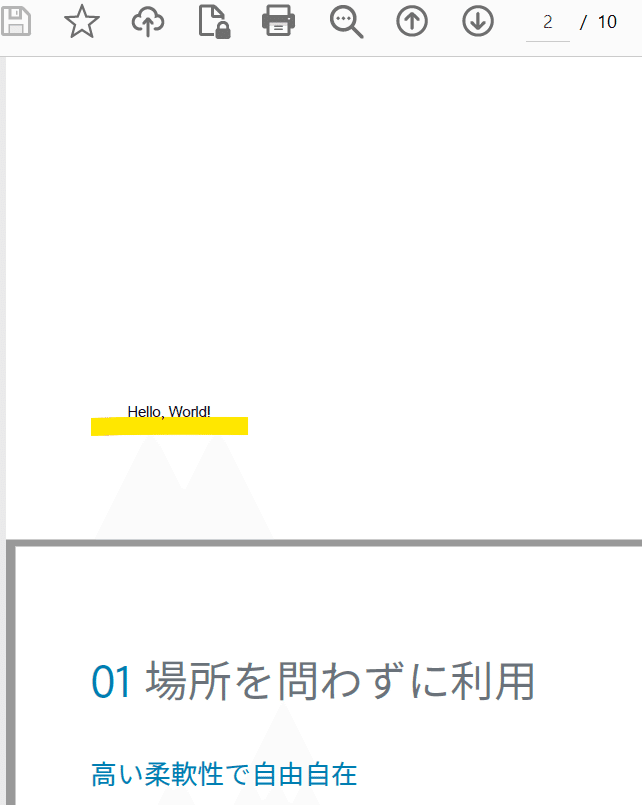
ベースのPDFの情報はどこに行ったんでしょうか?
改善が必要です。
import PyPDF2
from reportlab.lib.pagesizes import letter
from reportlab.pdfgen import canvas
import io
# 元のPDFファイルのパス
input_pdf_path = 'C:\\Users\\found.pdf'
# 注釈が追加されたPDFファイルのパス
output_pdf_path = 'C:\\Users\\found_追加.pdf'
# PDFファイルを開いて注釈を追加
with open(input_pdf_path, 'rb') as input_file:
reader = PyPDF2.PdfReader(input_file)
writer = PyPDF2.PdfWriter()
# 元のPDFのページごとに注釈を追加
for page_number in range(len(reader.pages)):
page = reader.pages[page_number]
writer.add_page(page) # 元のPDFのページをそのまま追加
# 注釈を追加
page_x_size, page_y_size = letter
packet = io.BytesIO()
can = canvas.Canvas(packet, pagesize=(page_x_size, page_y_size))
can.drawString(100, 100, "Hello, World!") # 注釈の追加例
can.save()
# バッファーからPDFページを取得して追加
packet.seek(0)
overlay = PyPDF2.PdfReader(packet)
print("Overlay pages:", len(overlay.pages)) # overlay.pagesの長さを出力
for i, overlay_page in enumerate(overlay.pages):
writer.add_page(overlay_page)
# 新しいPDFを保存
with open(output_pdf_path, 'wb') as output_file:
writer.write(output_file)
print("PDFファイルが作成されました。")
思っていたのとは違うけど、元のPDFに追加されました。
import openpyxl
import PyPDF2
from reportlab.lib.pagesizes import letter
from reportlab.pdfgen import canvas
import io
# 元のPDFファイルと新しいPDFファイルのパス
input_pdf_path = 'C:\\Users\\found.pdf'
output_pdf_path = 'C:\\Users\\found_済.pdf'
# Excelファイルのパス
excel_file_path = 'C:\\Users\\座標3.xlsx'
# Excelファイルから注釈の情報を取得する
workbook = openpyxl.load_workbook(excel_file_path)
sheet = workbook.active
# PDFファイルを開く
with open(input_pdf_path, 'rb') as file:
reader = PyPDF2.PdfReader(file)
writer = PyPDF2.PdfWriter()
# ページごとに処理
for page_num, page in enumerate(reader.pages):
# 注釈情報をExcelから取得
x = float(sheet.cell(row=page_num + 2, column=1).value) # 行番号を1増やして1行目を無視
y = float(sheet.cell(row=page_num + 2, column=2).value) # 行番号を1増やして1行目を無視
comment = sheet.cell(row=page_num + 2, column=3).value # 行番号を1増やして1行目を無視
if x is not None and y is not None and comment is not None:
# 注釈を追加する
packet = io.BytesIO()
c = canvas.Canvas(packet, pagesize=letter)
c.drawString(x, y, comment)
c.save()
packet.seek(0)
new_pdf = PyPDF2.PdfReader(packet)
page.merge_page(new_pdf.pages[0])
# 新しいページを書き出し
writer.add_page(page)
# 新しいPDFファイルを保存
with open(output_pdf_path, 'wb') as output_file:
writer.write(output_file)
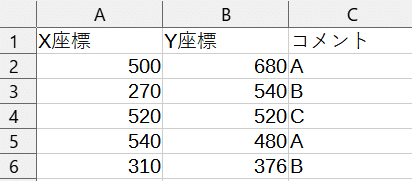

ページを指定して追加できるようになるか試してみます。
import openpyxl
import PyPDF2
from reportlab.lib.pagesizes import letter
from reportlab.pdfgen import canvas
import io
# 元のPDFファイルと新しいPDFファイルのパス
input_pdf_path = 'C:\\Users\\found.pdf'
output_pdf_path = 'C:\\Users\\found_済.pdf'
# Excelファイルのパス
excel_file_path = 'C:\\Users\\座標3.xlsx'
# Excelファイルから注釈の情報を取得する
workbook = openpyxl.load_workbook(excel_file_path)
sheet = workbook.active
# PDFファイルを開く
with open(input_pdf_path, 'rb') as file:
reader = PyPDF2.PdfReader(file)
writer = PyPDF2.PdfWriter()
# ページごとに処理
for row in sheet.iter_rows(min_row=2, max_row=sheet.max_row, values_only=True):
# 注釈情報をExcelから取得
x, y, comment, page_num = row[0], row[1], row[2], row[3]
# ページ番号がNoneでないことを確認
if page_num is not None:
page_num = int(page_num) # ページ番号を整数型に変換
# 対応するページのみ処理する
if 1 <= page_num <= len(reader.pages):
page = reader.pages[page_num - 1] # ページ番号は0からではなく1から始まるため、-1する
if x is not None and y is not None and comment is not None:
# 注釈を追加する
packet = io.BytesIO()
c = canvas.Canvas(packet, pagesize=letter)
c.drawString(x, y, comment)
c.save()
packet.seek(0)
new_pdf = PyPDF2.PdfReader(packet)
page.merge_page(new_pdf.pages[0])
# 新しいページを書き出し
writer.add_page(page)
# 新しいPDFファイルを保存
with open(output_pdf_path, 'wb') as output_file:
writer.write(output_file)

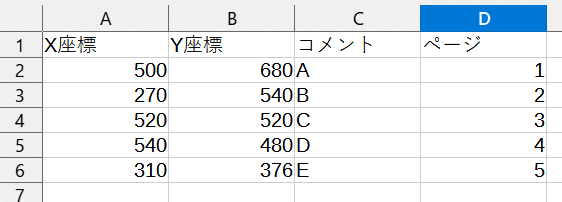
かなり良くなってきました。
import openpyxl
import PyPDF2
from reportlab.lib.pagesizes import letter
from reportlab.lib import colors
from reportlab.pdfgen import canvas
from reportlab.lib.units import inch
from reportlab.lib.colors import Color
import io
# 元のPDFファイルと新しいPDFファイルのパス
input_pdf_path = 'C:\\Users\\found.pdf'
output_pdf_path = 'C:\\Users\\found_済.pdf'
# Excelファイルのパス
excel_file_path = 'C:\\Users\\座標3.xlsx'
# Excelファイルから注釈の情報を取得する
workbook = openpyxl.load_workbook(excel_file_path)
sheet = workbook.active
# PDFファイルを開く
with open(input_pdf_path, 'rb') as file:
reader = PyPDF2.PdfReader(file)
writer = PyPDF2.PdfWriter()
# ページごとに処理
for row in sheet.iter_rows(min_row=2, max_row=sheet.max_row, values_only=True):
# 注釈情報をExcelから取得
x, y, comment, page_num = row[0], row[1], row[2], row[3]
# ページ番号がNoneでないことを確認
if page_num is not None:
page_num = int(page_num) # ページ番号を整数型に変換
# 対応するページのみ処理する
if 1 <= page_num <= len(reader.pages):
page = reader.pages[page_num - 1] # ページ番号は0からではなく1から始まるため、-1する
if x is not None and y is not None and comment is not None:
# 注釈を追加する
packet = io.BytesIO()
c = canvas.Canvas(packet, pagesize=letter)
# 四角を描画(文字の後ろ)
c.setStrokeColor(colors.red) # 枠の色を赤に設定
c.setFillColor(colors.yellow) # 塗りつぶしの色を黄色に設定
c.rect(x - 0.1*inch, y - 0.1*inch, 1*inch, 0.4*inch, fill=True) # 四角を描画
# 文字を描画(四角の上に)
c.setFillColor(colors.red) # 文字の色を赤に設定
c.drawString(x, y, comment)
c.save()
packet.seek(0)
new_pdf = PyPDF2.PdfReader(packet)
page.merge_page(new_pdf.pages[0])
# 新しいページを書き出し
writer.add_page(page)
# 新しいPDFファイルを保存
with open(output_pdf_path, 'wb') as output_file:
writer.write(output_file)
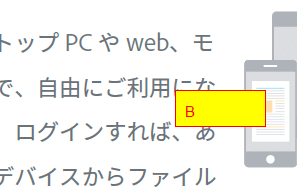
このコードをベースに色々アレンジできそうです。

この記事が気に入ったらサポートをしてみませんか?