深層学習を使って動物の可愛さを評価する

AIスキルをつけるため、AIアカデミーのE資格取得のコースを受けました。
このページでは、そのコースを受けるとどんなことができるのか、書いてみたいと思います。
初めてのブログなので、わかりにくかったり、見にくかったりしたらごめんなさい
課題
写真とデータから動物がどれだけかわいいか数字で評価する。
動物がかわいいかどうかなんてかなり主観的で、うまく学習できるかわかりませんが、学んだことを生かしてやっていきます。
入力データはしばらく前までやっていたらしい、Kaggle dataにしました。
理由は、面白そうだったからです。
https://www.kaggle.com/competitions/petfinder-pawpularity-score/overview

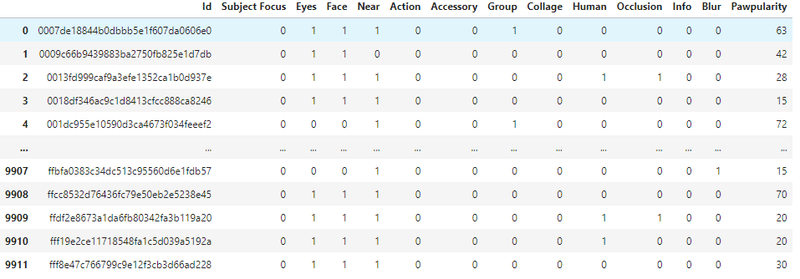
trainデータを8件みてみました。
タイトルが可愛さの数字です。例えば、左上の犬の可愛さは、63です。
右上の犬は可愛いと思うのですが、15というのは納得できないなあ。

trainデータは画像だけではなく、表形式のデータがついている。
例えば、eye(目)は、写真で目がちゃんと映っているか0,1で表現しているそうです。
EfficientNetB0-ns
写真だけでなく、この表がついているのが厄介です。
もう、このテーブルデータは無視して、画像認識の精度が高いEfficientNetを試しました。
EfficinetB0がなんとか動いたので、B0のコードを載せておきます。正確にいうとtf_efficientnet_b0_nsです。
MODEL_NAME = 'tf_efficientnet_b0_ns'
train_transform = A.Compose([
A.RandomResizedCrop(IMG_SIZE, IMG_SIZE, scale=(0.85, 1.1)),
A.RandomRotate90(),
A.Flip(),
A.Transpose(),
A.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225],
),
ToTensorV2(),
])
valid_transform = A.Compose([
A.Resize(IMG_SIZE, IMG_SIZE),
A.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225],
),
ToTensorV2(),
])
class PetDataset(Dataset):
def __init__(self, df, data_dir, transform=None, mode='train'):
self.df = df
self.data_dir = data_dir
self.transform = transform
self.mode = mode
def __len__(self):
return len(self.df)
def __getitem__(self, idx):
row = self.df.iloc[idx]
img_path = self.data_dir / f'{row[ID_COL]}.jpg'
img = np.array(Image.open(img_path).convert('RGB'))
if self.transform is not None:
img = self.transform(image=img)['image']
tgt = row[TARGET_COL] if self.mode == 'train' else 0
return img.float().to(device), torch.tensor(tgt).float().to(device)
class CustomModel(nn.Module):
def __init__(self, model_name=MODEL_NAME, pretrained=True):
super(CustomModel, self).__init__()
self.model = timm.create_model(model_name, pretrained=pretrained)
self.model.global_pool = nn.Identity()
self.model.classifier = nn.Identity()
self.head = create_head(self.model.num_features, 1)
self.act = nn.ReLU()
def forward(self, x):
x = self.model(x)
x = self.head(x)
x = self.act(x)
return x
kfold = KFold(n_splits=N_SPLITS, random_state=SEED, shuffle=True)
oof_pred = torch.zeros(len(train_df))
criterion = MSELossFlat()
for fold, (train_idx, valid_idx) in enumerate(kfold.split(train_df)):
print('='*5, f'Start Fold: {fold}', '='*5)
train_x, valid_x = train_df.loc[train_idx], train_df.loc[valid_idx]
train_ds, valid_ds = PetDataset(train_x, TRAIN_IMG_PATH, train_transform), PetDataset(valid_x, TRAIN_IMG_PATH, valid_transform)
train_dl = DataLoader(train_ds, batch_size=BATCH_SIZE, shuffle=True)
valid_dl = DataLoader(valid_ds, batch_size=BATCH_SIZE, shuffle=False)
dls = DataLoaders(train_dl, valid_dl)
model = CustomModel(MODEL_NAME).to(device)
learner = Learner(dls, model, loss_func=criterion, metrics=rmse)
learner.fine_tune(N_EPOCHS)
pred, tgt = learner.get_preds(dl=valid_dl)
oof_pred[valid_idx] = pred.detach().cpu().view(-1)
print(f'Fold: {fold}, RMSE: {mean_squared_error(tgt, pred, squared=False)}')
learner.save(f'learner_fold_{fold}')
torch.save(learner.model.state_dict(), f'./fold_{fold}.pth')
torch.cuda.empty_cache()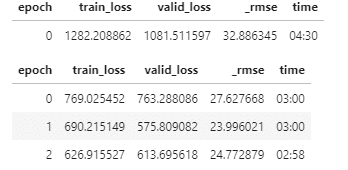
参考までに、B0-ns以外のモデルで動かすとどうしてもメモリ不足で動きませんでした。batch size=1にしてもダメ。GPUメモリ16Gもあるのに。
このエラーメッセージを何回みたことか。
/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py in convert(t)
608 if convert_to_format is not None and t.dim() == 4:
609 return t.to(device, dtype if t.is_floating_point() else None, non_blocking, memory_format=convert_to_format)
--> 610 return t.to(device, dtype if t.is_floating_point() else None, non_blocking)
611
612 return self._apply(convert)
RuntimeError: CUDA out of memory. Tried to allocate 2.00 MiB (GPU 0; 15.90 GiB total capacity; 14.92 GiB already allocated; 3.75 MiB free; 15.05 GiB reserved in total by PyTorch)とにかく学習にものすごく時間がかかる。ハイパーパラメタを変えながら試すが、rmseが23ぐらいが限界みたいです。
青色が正解、オレンジが予測結果です。
ものすごく外してます。特に0付近に予測が集中している。
この頑張った時間を返してほしい。

Fast AI
画像データ、テーブルデータともに扱えるモデルを探したところ、Fast AIというのが見つかりました。名前からして速そうです。
(fastaiは最も簡単に深層学習を行うことができるPythonのパッケージです)
EfficinetNetでは学習に相当時間がかかりまいっていたので、名前に飛びついてしまいました。
https://github.com/fastai/fastai
本を購入し、Fast AIでやってみることにしました。
このリンク先も参考になりました。
https://course.fast.ai/

可愛さの数字の分布
まず、100件ぐらいのデータをみてみた。
0-100点のスコアに分布していて、100点が3匹いるようだ。
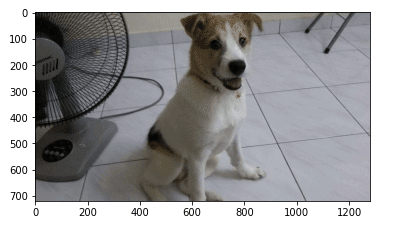
100点の動物をみたくなる。1個だけ見てみよう。
みよ、これが100点の可愛さだ
100点といえば100点だが、個人的には80点ぐらいかな。
そうすると、低い点数の動物も見たくなる。3点の動物がいた。
これだ。うーん、そうかな。そうかもな。微妙。
30点ぐらいあげてもいいじゃない?

早速Fast AIを実装しよう。
まずは、ImageDataLoaderを実装しよう。
画像のresizeはいくつがいいのかわからなかったが、試した結果224*224が一番いい結果となったので、そのコードを載せておきます。
from fastai.vision.all import *
from sklearn.model_selection import KFold
from sklearn.model_selection import StratifiedKFold
num_bins = int(np.floor(1+np.log2(len(train_df))))
train_df['bins'] = pd.cut(train_df['norm_score'], bins=num_bins, labels=False)
train_df['fold'] = -1
N_FOLDS = 10
strat_kfold = StratifiedKFold(n_splits=N_FOLDS, random_state=seed, shuffle=True)
for i, (_, train_index) in enumerate(strat_kfold.split(train_df.index, train_df['bins'])):
train_df.iloc[train_index, -1] = i
train_df['fold'] = train_df['fold'].astype('int')
def petfinder_rmse(input,target):
return 100*torch.sqrt(F.mse_loss(F.sigmoid(input.flatten()), target))
def get_data(fold):
# train_df_no_val = train_df.query(f'fold != {fold}')
# train_df_val = train_df.query(f'fold == {fold}')
# train_df_bal = pd.concat([train_df_no_val,train_df_val.sample(frac=1).reset_index(drop=True)])
train_df_f = train_df.copy()
# add is_valid for validation fold
train_df_f['is_valid'] = (train_df_f['fold'] == fold)
dls = ImageDataLoaders.from_df(train_df_f, #pass in train DataFrame
# valid_pct=0.2, #80-20 train-validation random split
valid_col='is_valid', #
seed=999, #seed
fn_col='path', #filename/path is in the second column of the DataFrame
label_col='norm_score', #label is in the first column of the DataFrame
y_block=RegressionBlock, #The type of target
bs=BATCH_SIZE, #pass in batch size
num_workers=8,
item_tfms=Resize(224,ResizeMethod.Pad), #@#pass in item_tfms
batch_tfms=setup_aug_tfms([Brightness(), Contrast(), Hue(), Saturation()])) #pass in batch_tfms
return dlsTimmを使ってモデルを作る
モデルを作ろう。timmのcreate_modelを使い実装する。Timmは便利なので好きです。
from timm import create_model
def get_learner(fold_num):
data = get_data(fold_num)
model = create_model('swin_large_patch4_window7_224', pretrained=True, num_classes=data.c)
learn = Learner(data, model, loss_func=BCEWithLogitsLossFlat(), metrics=petfinder_rmse).to_fp16()
return learnいい感じの学習率を探してみよう。グラフのオレンジのところが一番いい学習率だ。この学習率を使い学習させる。
get_learner(fold_num=0).lr_find(end_lr=3e-2)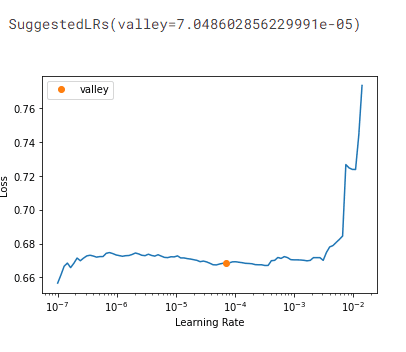
学習ロジック。
Kfoldを10にして学習させてみました。
def get_learner(fold_num):
data = get_data(fold_num)
model = create_model('swin_large_patch4_window7_224', pretrained=True, num_classes=data.c)
learn = Learner(data, model, loss_func=BCEWithLogitsLossFlat(), metrics=petfinder_rmse).to_fp16()
return learn推論ロジック
これが正しいのか確信はありませんが、本をよんで組んでみました。
感想としては、自動深層学習系はブラックボックスになっていて、非常にわかりにくいです。
all_preds = []
for i in range(N_FOLDS):
print(f'Fold {i} results')
learn = get_learner(fold_num=i)
learn.fit_one_cycle(5, 2e-5, cbs=[SaveModelCallback(), EarlyStoppingCallback(monitor='petfinder_rmse', comp=np.less, patience=2)])
learn.recorder.plot_loss()
#learn = learn.to_fp32()
#learn.export(f'model_fold_{i}.pkl')
#learn.save(f'model_fold_{i}.pkl')
dls = ImageDataLoaders.from_df(train_df, #pass in train DataFrame
valid_pct=0.2, #80-20 train-validation random split
seed=999, #seed
fn_col='path', #filename/path is in the second column of the DataFrame
label_col='norm_score', #label is in the first column of the DataFrame
y_block=RegressionBlock, #The type of target
bs=BATCH_SIZE, #pass in batch size
num_workers=8,結果です
Kfold 10回の中の1回目のキャプチャです。
EfficinetNetと異なりrmseが17まで下がりました。
処理が速いのが素晴らしい。
Better model found at epoch 0 with valid_loss value: 0.6451650261878967.
Better model found at epoch 1 with valid_loss value: 0.640606701374054.
Better model found at epoch 2 with valid_loss value: 0.6386224627494812.
Better model found at epoch 4 with valid_loss value: 0.6384101510047913.
Kfoldの10回目のキャプチャです。
Better model found at epoch 0 with valid_loss value: 0.6447761654853821.
Better model found at epoch 1 with valid_loss value: 0.6401539444923401.
Better model found at epoch 2 with valid_loss value: 0.6396892070770264.
Better model found at epoch 3 with valid_loss value: 0.6369615793228149.
Better model found at epoch 4 with valid_loss value: 0.6366721987724304.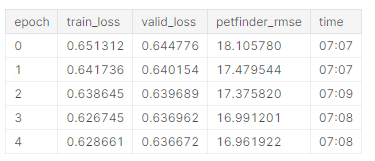
グラフにするとこんな感じ。Lossが減っていって、学習はできている。
Lossは62%あたりで止まってしまう。

結論。
人が考える動物の可愛さは人それぞれで違う。
いくら深層学習の先端技術をつかっても、人のもつ主観までは読み解けないと思った。
ただ、いろいろなモデルを使って学習と推論、評価を繰り返していくのはだいぶ慣れてきたので、いい勉強になりました。
FastAIというのも、難しかったけどうまく使えるようになりたい。
(FastAIは一番簡単な深層学習らしいですが、苦労しました。)

この記事が気に入ったらサポートをしてみませんか?