⑦OpenAI Whisperを利用した文字起こし>字幕作成コード。OpenAI API 1.0以降対応版。

openaiのAPI挙動が変わってしまい、自分用のツールで困っていたので書き直しました。まずはバージョン確認していきます。
pip show openai
上記のように記述がだいぶ変わってしまうのでバージョンを上げない選択肢もあると思います。その場合venvなどでご対応ください。
(2023/12/11編集)
バージョンを以前のものに戻したい場合は以下
pip uninstall openai
and then reinstall targeted to the pre-1.x release with:
pip install openai==0.28.1
前回作ったツールでおむすびころりんの動画をダウンロードしてきました。
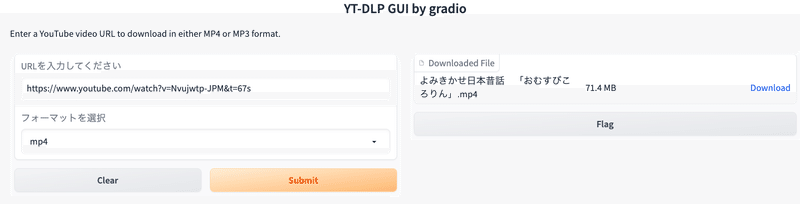
今回のコード
import gradio as gr
import os
from pydub import AudioSegment
from openai import OpenAI
# OpenAIのクライアントを初期化
client = OpenAI(api_key=os.environ['OPENAI_API_KEY'])
def clear_tmp_folder():
"""'tmp' フォルダの中身をクリアする"""
tmp_folder = "tmp"
os.makedirs(tmp_folder, exist_ok=True)
for file_name in os.listdir(tmp_folder):
file_path = os.path.join(tmp_folder, file_name)
if os.path.isfile(file_path):
os.unlink(file_path)
def get_duration(inputs, language):
"""音声ファイルを分割し、各チャンクを文字起こししてSRTファイルとトランスクリプトを生成する"""
audio = AudioSegment.from_file(inputs, format="m4a")
length = len(audio)
chunk_length = 1000000 # 1,000,000ミリ秒ごとに分割
overlap_length = 10000 # 10,000ミリ秒のオーバーラップ
chunks = []
# チャンクを生成する際にオーバーラップを考慮
for i in range(0, length, chunk_length - overlap_length):
end = min(i + chunk_length, length)
chunk = audio[i:end]
chunks.append((chunk, i, end)) # チャンクと実際の開始/終了時間を保存
all_segments = []
transcript_text = ""
for i, (chunk, start, end) in enumerate(chunks, start=1):
output_file = f"tmp/split{i}.mp3"
chunk.export(output_file, format="mp3")
with open(output_file, "rb") as audio_file:
transcript = client.audio.transcriptions.create(
file=audio_file, model="whisper-1", response_format="verbose_json", language=language)
for segment in transcript.segments:
segment['start'] += start / 1000 # チャンクの実際の開始時間を加算
segment['end'] += start / 1000 # チャンクの実際の終了時間を加算
all_segments.append(segment)
transcript_text += transcript.text + "\n"
srt_content = convert_to_srt(all_segments)
save_srt_file(srt_content, "tmp/output.srt")
save_srt_file(transcript_text, "tmp/full_transcript.txt")
return srt_content, transcript_text
def convert_to_srt(segments):
"""セグメントをSRTフォーマットに変換する"""
def format_time(time_in_seconds):
"""秒をHH:MM:SS,mmmフォーマットに変換する"""
hours, remainder = divmod(time_in_seconds, 3600)
minutes, seconds = divmod(remainder, 60)
milliseconds = int((seconds - int(seconds)) * 1000)
return f"{int(hours):02}:{int(minutes):02}:{int(seconds):02},{milliseconds:03}"
return "\n".join([
f"{index + 1}\n{format_time(segment['start'])} --> {format_time(segment['end'])}\n{segment['text']}\n"
for index, segment in enumerate(segments)
])
def save_srt_file(srt_content, file_name):
"""SRTコンテンツをファイルに保存する"""
with open(file_name, "w", encoding="utf-8") as file:
file.write(srt_content)
clear_tmp_folder()
# Gradioインターフェイスの設定
iface = gr.Interface(
fn=get_duration,
inputs=[gr.Audio(type="filepath", label="会議ファイルをアップロード"), gr.Dropdown(choices=["en", "ja"], label="言語選択")],
outputs=["text", "text"],
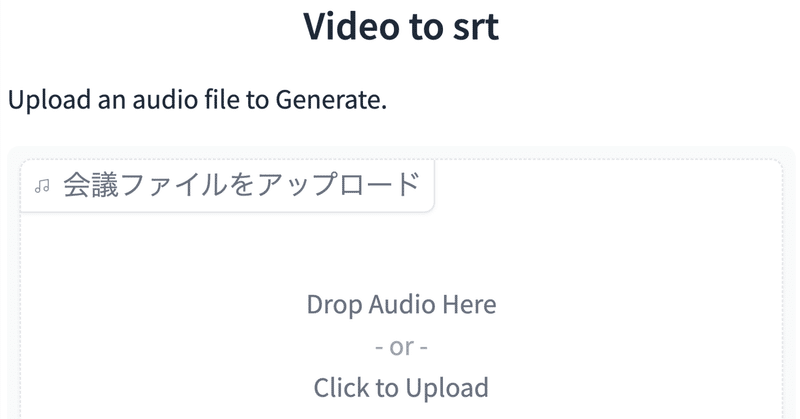
title="Video to srt",
description="Upload an audio file to Generate."
)
iface.launch(inbrowser=True)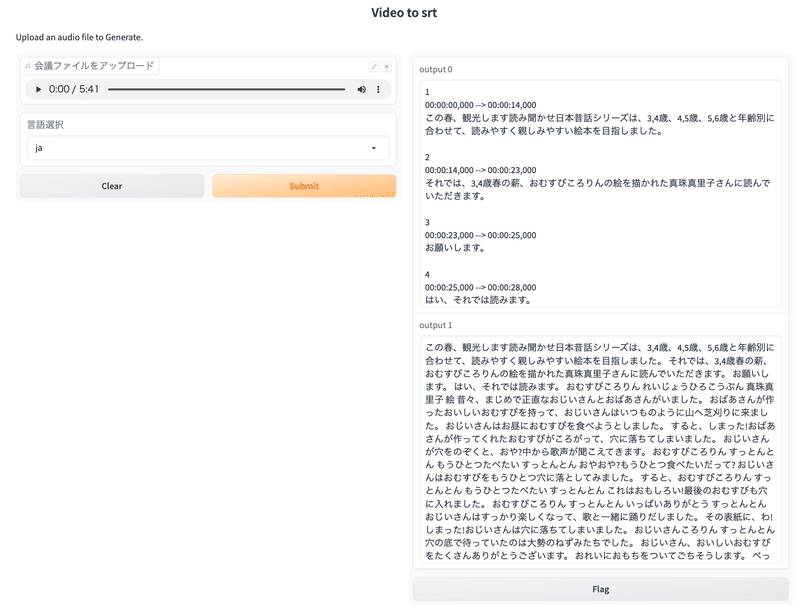
テンポラリフォルダにsrtファイルが生成されます

VLCプレーヤなどで再生すると字幕がつきます

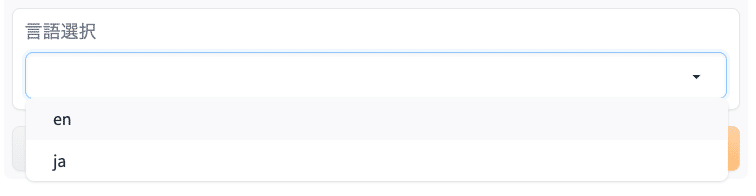
transcript = client.audio.transcriptions.create(
file=audio_file, model="whisper-1", response_format="verbose_json", language=language)client.audio.transcriptions.createの中にlanguageを入力できるので付けてみました。基本的には入力言語の設定ですので以下のようになってしまいますが、短い動画とかならば何故か英語変換もできる感じでしたので付けたままにしてあります。
client.audio.translations.create()に書き換えるとおそらくすべての言語を英語に翻訳して出力すると思います。
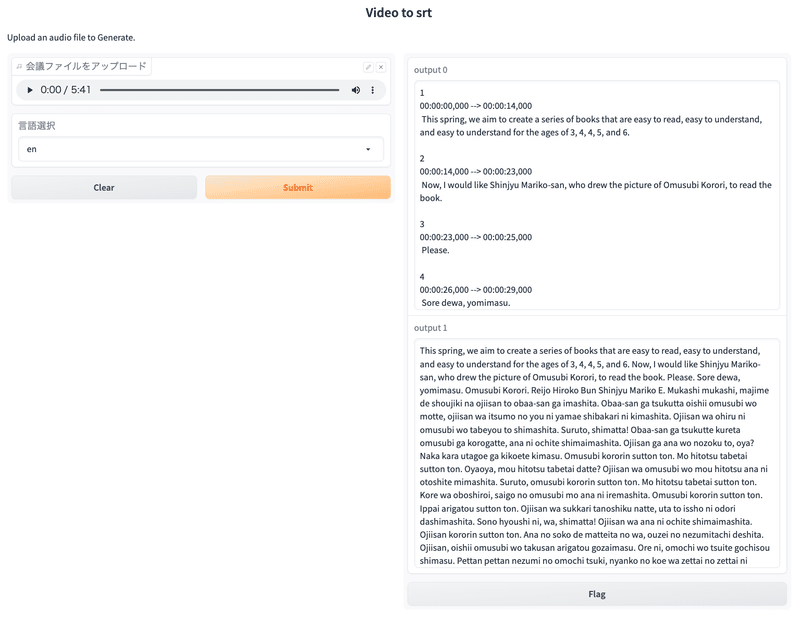
文字起こしできる言語は以下のようになっています。
https://platform.openai.com/docs/guides/speech-to-text/quickstart
「基礎となるモデルは 98 の言語でトレーニングされましたが、音声テキスト変換モデルの精度の業界標準ベンチマークである単語誤り率(WER)が 50% 未満を超えた言語のみをリストします。モデルは上記にリストされていない言語の結果を返しますが、品質は低くなります」
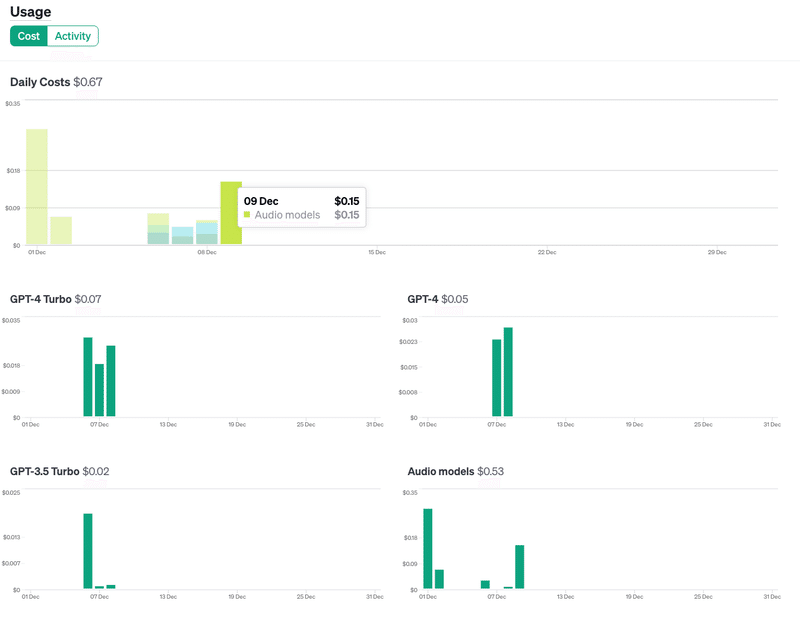
コスト