
【python初心者】chromebookで作る、Googleトレンドワードを元に、関連書籍を投稿するtwitter bot

2年前くらいから、ゆるゆるProgateとかで学習を始めては挫折し、2018年に入ってから、またAidemyやら、PyQでPythonを勉強していて、なにか動かせるものを作りたいと思っていた。
Dai氏のwebAPIの記事をさまざま見ていて、WEBサービスとしてデザインなどしっかり作り込まなくても、APIを活用したtwitterアプリならすぐ動かせるものが作れるし、UIも既存のものをつかえるので画面をデザインする必要もない。
ということに、目からウロコで早速取り掛かった。現在の私のプログラミングの学習状況は、ProgateのPythonは完了していて、Aidemyの中級くらいまでを一周、その後PyQで文法を学習している途中。(まだまだ初級)
実際に自分で作りたいものを考えて作ってみて、作ることの楽しさと、動かせたことに対する自信がもてた。初級程度のスキルでも、調べながら、読み解きながら、それだけでも便利なものが作れる気がする。この勘違いというか、作れるようになった自信、がなにより大きいと感じる。自分がほしいものを作っただけなので、「作れた」だけだが、最初はそれでいいと思う。
さて、色々と調べながら作っていき、いくつかハマった場所もあったので、下記に作ったものを記載していきたい。特に、プログラムを作ってから、実際に動かすところまで、が個人的には難易度高かったので、丁寧に記載したつもり。Python初学者の参考になれば幸い。ご指摘、お問い合わせなどは、ぜひ頂戴したい。スキルの追いつく限り、対応させて頂きたい。
【環境】
-chromebook (ASUS C101P がサイズ、価格ともにちょうどよかった)
-colaboratory >詳細はこちらがわかりよい > https://www.codexa.net/how-to-use-google-colaboratory/
基本的には、上記2つだけあれば、pythonを動かせる。本番用のファイルにするために、
-codenvy オンライン開発環境
-GitHub
-Heroku
を使った。
【作ったもの】
1,Googleのトレンドワードを取得して
2,Amazonの書籍検索に突っ込んで、返ってきた結果をソートして
3,twitterに自動的に1日2回、N件投稿するBOT

(画像をクリックすると作ったBOTにとびます)
今まさにトレンドの本を取得するものも作っていきたいと思ったが、アマゾンのランキングと変わらなそうだし、最初は取得しやすいワードから本のリストを取得して、投稿までを実装してみることを優先した。作った結果、アルゴリズム的にはもっと作り込む必要があると感じるので、そこはこれから育てていく。
では、ここから作り方を記載する。
-Google Colaboratoryにてパーツごとの機能の実装を進めていき、
-サーバーにアップするため、プログラムの形にまとめ、
-サーバーにて自動的に実行させる
の順序。
【準備①】APIを使うので、認証の準備が必要。今回使うのは、
Amazonとtwitter。
Amazonの取得方法はこちらを参照。
少し画面が異なる部分もあったが、必要な下記3点は取得できた。URLを登録する必要があるが、適当なブログや、twitter(作成から1ヶ月ほど経ったもの)があれば良いらしい。承認まではコードを書いて待とう。
# Amazon のAPIキーたち
AWS_ACCESS_KEY_ID = "XXXXXX"
AWS_SECRET_ACCESS_KEY = "XXXXXXX"
AWS_ASSOCIATE_TAG = "XXXXX"続いてtwitterの取得。
ここも同じく下記が取得できればOK。
# twitterのアクセストークン
CONSUMER_KEY = 'XXXXXXXXXX'
CONSUMER_SECRET_KEY = 'XXXXXXXXXXXXXXXX'
ACCESS_TOKEN = 'XXXXXXXXXXXXXXXX'
ACCESS_TOKEN_SECRET = 'XXXXXXXXXXXXXXX'2018年に開発者登録方法の変更があったようで、WEBで調べた画面と異なるところが多かった。
<twitter の認証コード取得方法>
https://apps.twitter.com/ このURLにアクセスする。
Apply for a developer account をクリック。
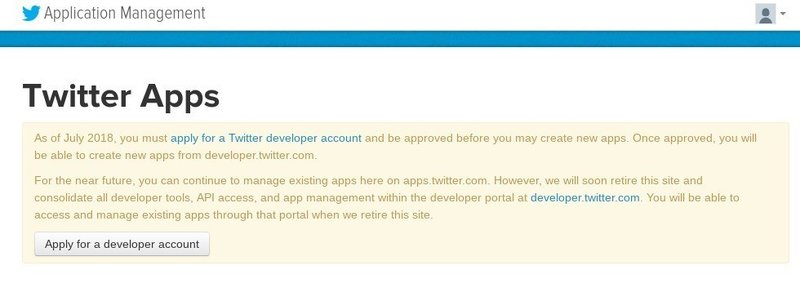
作りたいアプリについての説明を求められるので、各々埋めていく。
アプリの詳細な説明を300ワード以上で求められるので、適当に埋めていこう。。。
【作り方①】Googleのトレンドワードの取得
colabolatoryで、一つづつ動かしながら作って行ったので、その手順を踏襲する。最後に、本番環境用にまとめたコードも記載する。
<参考にさせていただいたリンク>
http://www.blue-weblog.com/entry/2018/01/07/170052
!pip install pytrends
!pip install git+https://github.com/GeneralMills/pytrends@master --upgrade
from pytrends.request import TrendReq
# pytrendでトレンドワードを取得する >trend_words
pytrend = TrendReq()
trending_searches_df = pytrend.trending_searches(pn='p4')
trend_words = trending_searches_df["title"]
print(trend_words)
Googleのトレンドワードは、pytrendを用いて取得できた。dataframeに格納されるので、"title"だけを出力すると、
0 明日の天気
1 King & Prince
2 塚田農場
3 椎名林檎 アダムとイヴの林檎
4 日大アメフト
5 ガスト カエル
6 ご当地ナンバープレート
7 倉科カナ
8 加計学園
9 新田真剣佑
10 小坂菜緒
11 南海トラフ
12 川口春奈
13 キラウエア火山
14 リリーフランキー
15 安達祐実
Name: title, dtype: objectトレンドワードが取得できた。
pn=p4 で日本を指定している。Herokuで動かすときに、ここがハマったので結局修正したが、colaboratoryではこれで動くので、その際に後述する。
【作り方②】AmazonのAPIに取得したトレンドワードをなげる
長くなってしまったので、処理を順番に解説する。
<参考にさせていただいたリンク>
https://qiita.com/maroemon58/items/6ce67863c813ae859e68
@retry :エラーが返ってくると1秒待って最大7回リトライをしてくれる処理。引数の部分で調整可能。アマゾンのAPIは、エラーも多いので、そのための処理。
search関数:アマゾンのアイテムサーチをしてくれる部分。レスポンスグループで、取得する情報群の大きさを設定している。参照>https://images-na.ssl-images-amazon.com/images/G/09/associates/paapi/dg/index.html
main関数:トレンドワードでアマゾン検索し、返ってきた書籍の必要な情報をpandasのデータフレームに格納していく部分。今回取得する情報は、columns=['title','image', 'url', 'rank','author','keyword','ad'] の通り。adはアダルトの判定。情報が入っていない商品もあるようなので、著者、商品画像の欠損がある場合は無視することにし、ランクの欠損はランク外と考えて99999で埋めた。
!pip install bottlenose
!pip install python-dotenv
!pip install retry
import os
import urllib
import re
import pandas as pd
from bottlenose import Amazon
from bs4 import BeautifulSoup
from retry import retry
# 必要なライブラリを準備
# エラーの場合、1秒待機しリトライ(最大7回)
# ResponseGroupについては、https://images-na.ssl-images-amazon.com/images/G/09/associates/paapi/dg/index.html 参照
@retry(urllib.error.HTTPError, tries=7, delay=1)
def search(amazon, k, i):
print('get products...')
return amazon.ItemSearch(Keywords=k, SearchIndex=i, Sort="daterank", ResponseGroup="Medium")
def main():
amazon = Amazon(AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY, AWS_ASSOCIATE_TAG, Region='JP',
Parser=lambda text: BeautifulSoup(text, 'xml')
)
# 最終格納用のDF作成
data_frame = pd.DataFrame(index=[], columns=['title','image', 'url', 'rank','author','keyword','ad'])
# トレンドワードでアマゾン検索かける。本のジャンルだけ。
for keyword in trend_words:
response = search(amazon, keyword, "Books") #本だけじゃないときは"Books"を変える https://images-na.ssl-images-amazon.com/images/G/09/associates/paapi/dg/index.html
print(response) #特にprintする必要はない
# 検索によって返ってきた情報をデータフレームに格納していく
for item in response.find_all('Item'):
print(item.Title.string, item.LargeImage, item.DetailPageURL.string, item.SalesRank, item.IsAdultProduct, item) # ここも特にprintする必要はない
sr = item.SalesRank
li = item.LargeImage
au = item.Author
ad = item.IsAdultProduct
if sr and li and au : # Rank外じゃなく、表紙の画像があり、著者名がある場合
series = pd.Series([item.Title.string, li.URL.string, item.DetailPageURL.string, sr.string, au.string, keyword, ad], index=data_frame.columns)
data_frame = data_frame.append(series, ignore_index = True)
elif sr == None and li and au : # ランクがない場合は999999で埋める
series = pd.Series([item.Title.string, li.URL.string, item.DetailPageURL.string, "9999999", au.string, keyword, ad], index=data_frame.columns)
data_frame = data_frame.append(series, ignore_index = True)
else: # 他欠損があるデータはスキップする
continue
# 商品ランクでソートする
data_frame[["rank"]]=data_frame[["rank"]].astype(int)
tweet_df = data_frame.sort_values(by="rank")
return tweet_df
if __name__ == '__main__':
tweet_df = main()
print(tweet_df)ここまでで、データフレームにツイートに使いたい情報が格納されている状態になった。最後に商品ランクでソートしているのは、ツイートする書籍の優先順位を商品ランク順にしたいから。ワードの検索順で投稿してしまうと、似たような書籍が連続してしまう可能性を嫌った。
【作り方③】twitterに自動的に投稿を行う
tweet_dfというデータフレームに格納したツイート情報を、実際にツイートする形に変形し、リストに格納、投稿する部分。
tweets : 投稿するtweetを格納する為のリスト
データフレームを1行ごとfor文で回し、必要な情報を文字列につなげて投稿を作っている。本の画像つきの投稿をしたかったので、後半部で画像をアップロードして(というよりはtwitterに渡して)メディアIDを取得している。
sleepは投稿が連続してたくさんにならないように、時間をあけるためにいれている。テストは60秒だが、本番は120秒に変更した。何秒でも特に問題はないはず。loopCounterは、投稿の回数を制限するため、本番では調整する。
!pip install twitter
from twitter import *
from requests_oauthlib import OAuth1Session
import json
import datetime
from time import sleep
# twitterの各トークン
twitter = OAuth1Session(CONSUMER_KEY, CONSUMER_SECRET_KEY, ACCESS_TOKEN, ACCESS_TOKEN_SECRET)
url_media = "https://upload.twitter.com/1.1/media/upload.json"
url_text = "https://api.twitter.com/1.1/statuses/update.json"
# 投稿回数を制限する為のカウンター
loopCounter = 1
tweets = [] #ここにツイートする内容を入れる
# データフレームの1行ごとにツイートを作成していく。sleepでツイート毎の投稿間隔を調整。
for i,v in tweet_df.iterrows():
print(i,v["title"],v["author"],v["url"]) # dfの投稿する内容の確認
if v["ad"] != "<IsAdultProduct>1</IsAdultProduct>": # adultフラグがたってたら投稿しない
tweet =v["title"] +"\n"+ v["author"] + "\n" +"#"+ v["keyword"]+" #trendbooks" + "\n" + v["url"] # tweetの文面部
media_name = v["image"]
tweets.append(tweet)
else:
continue
# 画像の投稿は下記の処理が必要。一度アップロードしてメディアIDを取得する必要あり。
files = {"media" : urllib.request.urlopen(media_name).read()}
req_media = twitter.post(url_media, files = files)
media_id = json.loads(req_media.text)['media_id']
print("MEDIA ID: %d" % media_id)
# tweet,meddia_idをもとに投稿
params = {"status" : tweet, "media_ids" : [media_id]}
req = twitter.post("https://api.twitter.com/1.1/statuses/update.json", params = params)
sleep(60) #1分待つ
# ループカウンター 投稿回数を制限する
if loopCounter > 5:
break
loopCounter += 1
以上で、基本的な機能は実装できた。
トレンドワード取得 → アマゾンで検索 → ツイートに投稿
次に、これらを自動で動かすために、
4,プログラムファイルにまとめる
5,Githubにアップロードして、Herokuで自動的に駆動させる
を行う。
【作り方④】プログラムのファイルにまとめる
colaboratoryで一通り動くようにはなったが、毎回ポチしないと動かないので、サーバーにアップして自動的に動くようにしたい。そのために、プログラムを1つのファイルにまとめていく。
colaboratory上で整理していって、最終的に「ファイル」>「.pyでダウンロード」でも同様にいける。
今回はmain.pyというファイル名で下記のようにまとめた。
※pytrendがHerokuの実行環境で動かせなかった(upgradeしてくれなかった)ので、必要な関数部分を抜き出して、書き換えていった。コードの部分でいうと、下記の部分。この段階で理解する必要はないと思うので、コピペしていただきたい。
===ココカラ===
#pytrendのupgradeが効かないので関数を修正
class TrendReq(object):
・・・
# pytrendでトレンドワードを取得する >trend_words
def pytre():
pytrend = TrendReq()
trending_searches_df = pytrend.trending_searches()
trend_words = trending_searches_df["title"]
print(trend_words)
return(trend_words)
===ココマデ===
※pytrendの詳細はこちら
※アクセスキーについては、Heroku側で環境変数として設定するので、直接記入ではなく書き換えが必要。無料で運用する場合、Githubは置いたファイルがすべて公開されてしまうようなので、秘密情報は別途読み込むようにしよう。
# main.py
from pytrends.request import TrendReq
import requests
import os #herokuの環境変数利用のため
import urllib
import re
import pandas as pd
from bottlenose import Amazon
from bs4 import BeautifulSoup
from retry import retry
from twitter import *
from requests_oauthlib import OAuth1Session
import json
import random
import datetime
from time import sleep
#amazonのアクセスキー
AWS_ACCESS_KEY_ID = os.environ["AWS_ACCESS_KEY_ID"]
AWS_SECRET_ACCESS_KEY = os.environ["AWS_SECRET_ACCESS_KEY"]
AWS_ASSOCIATE_TAG = os.environ["AWS_ASSOCIATE_TAG"]
# twitterのアクセストークン
CONSUMER_KEY = os.environ["CONSUMER_KEY"]
CONSUMER_SECRET_KEY = os.environ["CONSUMER_SECRET_KEY"]
ACCESS_TOKEN = os.environ["ACCESS_TOKEN"]
ACCESS_TOKEN_SECRET = os.environ["ACCESS_TOKEN_SECRET"]
#pytrendのupgradeが効かないので関数を修正
class TrendReq(object):
GET_METHOD = 'get'
POST_METHOD = 'post'
GENERAL_URL = 'https://trends.google.com/trends/api/explore'
INTEREST_OVER_TIME_URL = 'https://trends.google.com/trends/api/widgetdata/multiline'
INTEREST_BY_REGION_URL = 'https://trends.google.com/trends/api/widgetdata/comparedgeo'
RELATED_QUERIES_URL = 'https://trends.google.com/trends/api/widgetdata/relatedsearches'
TRENDING_SEARCHES_URL = 'https://trends.google.com/trends/hottrends/hotItems'
TOP_CHARTS_URL = 'https://trends.google.com/trends/topcharts/chart'
SUGGESTIONS_URL = 'https://trends.google.com/trends/api/autocomplete/'
CATEGORIES_URL = 'https://trends.google.com/trends/api/explore/pickers/category'
def __init__(self, hl='en-US', tz=360, geo='', proxies=''):
"""
Initialize default values for params
"""
# google rate limit
self.google_rl = 'You have reached your quota limit. Please try again later.'
self.results = None
# set user defined options used globally
self.tz = tz
self.hl = hl
self.geo = geo
self.kw_list = list()
self.proxies = proxies #add a proxy option
#proxies format: {"http": "http://192.168.0.1:8888" , "https": "https://192.168.0.1:8888"}
# intialize widget payloads
self.token_payload = dict()
self.interest_over_time_widget = dict()
self.interest_by_region_widget = dict()
self.related_topics_widget_list = list()
self.related_queries_widget_list = list()
def _get_data(self, url, method=GET_METHOD, trim_chars=0, **kwargs):
"""Send a request to Google and return the JSON response as a Python object
:param url: the url to which the request will be sent
:param method: the HTTP method ('get' or 'post')
:param trim_chars: how many characters should be trimmed off the beginning of the content of the response
before this is passed to the JSON parser
:param kwargs: any extra key arguments passed to the request builder (usually query parameters or data)
:return:
"""
if method == TrendReq.POST_METHOD:
s = requests.session()
if self.proxies != '':
s.proxies.update(self.proxies)
response = s.post(url, **kwargs)
else:
s = requests.session()
if self.proxies != '':
s.proxies.update(self.proxies)
response = s.get(url,**kwargs)
# check if the response contains json and throw an exception otherwise
# Google mostly sends 'application/json' in the Content-Type header,
# but occasionally it sends 'application/javascript
# and sometimes even 'text/javascript
if 'application/json' in response.headers['Content-Type'] or \
'application/javascript' in response.headers['Content-Type'] or \
'text/javascript' in response.headers['Content-Type']:
# trim initial characters
# some responses start with garbage characters, like ")]}',"
# these have to be cleaned before being passed to the json parser
content = response.text[trim_chars:]
# parse json
return json.loads(content)
else:
# this is often the case when the amount of keywords in the payload for the IP
# is not allowed by Google
raise exceptions.ResponseError('The request failed: Google returned a '
'response with code {0}.'.format(response.status_code), response=response)
def build_payload(self, kw_list, cat=0, timeframe='today 5-y', geo='', gprop=''):
"""Create the payload for related queries, interest over time and interest by region"""
self.kw_list = kw_list
self.geo = geo
self.token_payload = {
'hl': self.hl,
'tz': self.tz,
'req': {'comparisonItem': [], 'category': cat, 'property': gprop}
}
# build out json for each keyword
for kw in self.kw_list:
keyword_payload = {'keyword': kw, 'time': timeframe, 'geo': self.geo}
self.token_payload['req']['comparisonItem'].append(keyword_payload)
# requests will mangle this if it is not a string
self.token_payload['req'] = json.dumps(self.token_payload['req'])
# get tokens
self._tokens()
return
def _tokens(self):
"""Makes request to Google to get API tokens for interest over time, interest by region and related queries"""
# make the request and parse the returned json
widget_dict = self._get_data(
url=TrendReq.GENERAL_URL,
method=TrendReq.GET_METHOD,
params=self.token_payload,
trim_chars=4,
)['widgets']
# order of the json matters...
first_region_token = True
# clear self.related_queries_widget_list and self.related_topics_widget_list
# of old keywords'widgets
self.related_queries_widget_list[:] = []
self.related_topics_widget_list[:] = []
# assign requests
for widget in widget_dict:
if widget['id'] == 'TIMESERIES':
self.interest_over_time_widget = widget
if widget['id'] == 'GEO_MAP' and first_region_token:
self.interest_by_region_widget = widget
first_region_token = False
# response for each term, put into a list
if 'RELATED_TOPICS' in widget['id']:
self.related_topics_widget_list.append(widget)
if 'RELATED_QUERIES' in widget['id']:
self.related_queries_widget_list.append(widget)
return
def trending_searches(self, pn='p1'):
# make the request
forms = {'ajax': 1, 'pn': 'p4', 'htd': '', 'htv': 'l'}
req_json = self._get_data(
url=TrendReq.TRENDING_SEARCHES_URL,
method=TrendReq.POST_METHOD,
data=forms,
)['trendsByDateList']
result_df = pd.DataFrame()
# parse the returned json
sub_df = pd.DataFrame()
for trenddate in req_json:
sub_df['date'] = trenddate['date']
for trend in trenddate['trendsList']:
sub_df = sub_df.append(trend, ignore_index=True)
result_df = pd.concat([result_df, sub_df])
return result_df
# pytrendでトレンドワードを取得する >trend_words
def pytre():
pytrend = TrendReq()
trending_searches_df = pytrend.trending_searches()
trend_words = trending_searches_df["title"]
print(trend_words)
return(trend_words)
#trend_wordsをアマゾンで検索、書籍のみ > tweet_dfにtitle/image/url/rank等を格納する
# エラーの場合、1秒待機しリトライ(最大7回)
@retry(urllib.error.HTTPError, tries=7, delay=1)
def search(amazon, k, i):
print('get products...')
return amazon.ItemSearch(Keywords=k, SearchIndex=i, Sort="daterank", ResponseGroup="Medium")
def tweetdf():
amazon = Amazon(AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY, AWS_ASSOCIATE_TAG, Region='JP',
Parser=lambda text: BeautifulSoup(text, 'xml')
)
#最終格納用のDF作成
data_frame = pd.DataFrame(index=[], columns=['title','image', 'url', 'rank','author','keyword','ad'])
trend_words = pytre()
for keyword in trend_words:
response = search(amazon, keyword, "Books")
print(response)
for item in response.find_all('Item'):
print(item.Title.string, item.LargeImage, item.DetailPageURL.string, item.SalesRank, item.IsAdultProduct, item)
sr = item.SalesRank
li = item.LargeImage
au = item.Author
ad = item.IsAdultProduct
if sr and li and au :
series = pd.Series([item.Title.string, li.URL.string, item.DetailPageURL.string, sr.string, au.string, keyword, ad], index=data_frame.columns)
data_frame = data_frame.append(series, ignore_index = True)
elif sr == None and li and au :
series = pd.Series([item.Title.string, li.URL.string, item.DetailPageURL.string, "9999999", au.string, keyword, ad], index=data_frame.columns)
data_frame = data_frame.append(series, ignore_index = True)
else:
continue
data_frame[["rank"]]=data_frame[["rank"]].astype(int)
tweet_df = data_frame.sort_values(by="rank")
print(tweet_df)
return tweet_df
def tweet():
twitter = OAuth1Session(CONSUMER_KEY, CONSUMER_SECRET_KEY, ACCESS_TOKEN, ACCESS_TOKEN_SECRET)
url_media = "https://upload.twitter.com/1.1/media/upload.json"
url_text = "https://api.twitter.com/1.1/statuses/update.json"
loopCounter = 1
tweets = [] #ここにツイートする内容を入れる
tweet_df = tweetdf()
for i,v in tweet_df.iterrows():
print(i,v["title"],v["author"],v["url"])
if v["ad"] != "<IsAdultProduct>1</IsAdultProduct>":
tweet =v["title"] +"\n"+ v["author"] + "\n" +"#"+ v["keyword"]+" #trendbooks" + "\n" + v["url"]
media_name = v["image"]
tweets.append(tweet)
else:
continue
files = {"media" : urllib.request.urlopen(media_name).read()}
req_media = twitter.post(url_media, files = files)
media_id = json.loads(req_media.text)['media_id']
print("MEDIA ID: %d" % media_id)
params = {"status" : tweet, "media_ids" : [media_id]}
req = twitter.post("https://api.twitter.com/1.1/statuses/update.json", params = params)
sleep(120) #2分待つ
if loopCounter > 15:
break
loopCounter += 1
def main():
tweet()
if __name__ == '__main__':
main()
長くなったが、
-pip import 等、ライブラリの準備をまとめる
-アクセスキーなど定数を設定
-各関数を設定(colaboratoryの対話型の入力から機能ごとにまとめていく必要)
-実行用のmain()を設定し、実行させる
の順で作成している。
主要な機能はこちらで動くようになった。このあとは、githubにあげて、Herokuにアップすることで、自動で投稿するBOTにしていく。
【作り方⑤】Githubにアップし、Herokuと連携する
HerokuというPaasサービスに登録すると、自動でスケジューラーがプログラムを動かしてくれる。。!! ので、Herokuで動かすことにした。
<参考にさせていただいたリンク>
https://qiita.com/enomotok_/items/41275dd904c8aa774e72
リンク先の表示の通り、おまじないファイルを作成した。
# Procfile
web: python index.py# index.py
# -*- coding: utf-8 -*-
import os
from bottle import route, run
@route("/")
def hello_world():
return "" # ここで返す内容は何でもよい
run(host="0.0.0.0", port=int(os.environ.get("PORT", 5000)))# runtime.txt
python-3.6.5runtime.txt ファイルは、3.6.5にて行った。
# requirements.txt
autopep8==1.3.5
beautifulsoup4==4.6.0
bottlenose==1.1.8
certifi==2018.4.16
chardet==3.0.4
configparser==3.5.0
decorator==4.3.0
future==0.16.0
idna==2.6
jedi==0.12.0
json-rpc==1.11.0
lxml==4.2.1
mccabe==0.6.1
numpy==1.14.3
oauthlib==2.0.7
pandas==0.23.0
parso==0.2.0
pluggy==0.6.0
py==1.5.3
pycodestyle==2.4.0
pydocstyle==2.1.1
pyflakes==2.0.0
python-dateutil==2.7.3
python-dotenv==0.8.2
pytrends==4.3.0
pytz==2018.4
requests==2.18.4
requests-oauthlib==0.8.0
retry==0.9.2
rope==0.10.7
six==1.11.0
snowballstemmer==1.2.1
twitter==1.18.0
urllib3==1.22
virtualenv==16.0.0
yapf==0.22.0requirements.txt は上記の通り。(余計なものもあるかもしれない)
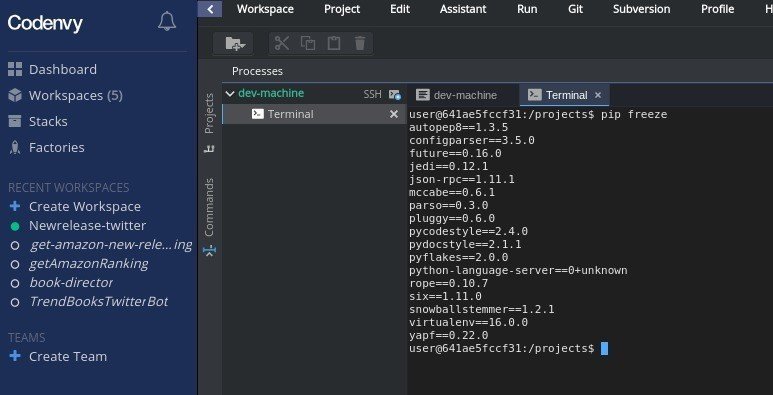
<補足>
ちなみにchromebookでローカルの開発環境を作らない場合、ブラウザで動く開発環境でpip freeze すると必要なライブラリをrequirements.txt の 形式で教えてくれる。
-Codenvyでワークスペースを作って、pyファイルをアップロード
-pyファイルのうち、pip をターミナルで実行していく(--user をつける必要あり)
-一通りインストールして、Run でのエラーがでなくなったら、pip freeze
-python-language~~ など一部不要なものが混ざり、Herokuでエラーが起こるので、都度消す。
で作れるので、オリジナルで作るとき参考になれば。
index.py
main.py
requirements.txt
runtime.txt
Procfile上記のファイル5つで動いている。Herokuで動かすには、githubにアップする必要があるようなので、アカウントを作成して、ファイルをアップしていく。※無料のプランで大丈夫 ※アカウントの作り方は割愛、WEBに大量に情報あり
<参考にさせていただいたリンク>
https://qiita.com/nnahito/items/565f8755e70c51532459
chromebookで開発していて、特にgithub関連でインストールなどもしていないが、上記にて作成したファイルを、ブラウザ上で同じレポジトリに一つづつアップロードしていけば、格納されていくし、そのままブラウザ上で編集も可能。
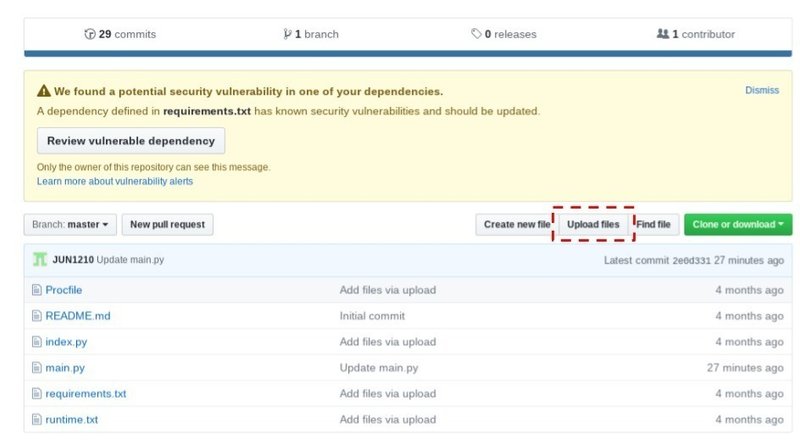
ここまでで、↑このようになっていると思う。
次にherokuとのコネクトを行う。
アカウントの作り方などは、こちらを参照のこと。コマンドラインツールは入れていない。

Newより、Create New appを選択。適当なapp nameを入力し、regionは変わらずUSでよい。appができると設定画面に遷移するので、設定を行う。
-Deploy
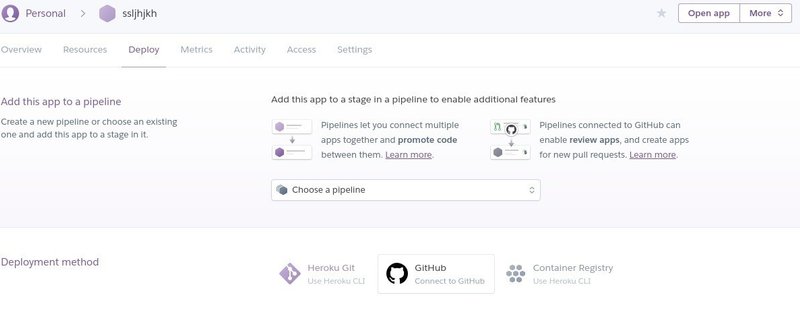
Deployment method を、上記の通りGitHubに設定する。

初回はアカウントから設定する必要があるが、該当するレポジトリを選択する。

レポジトリを選択すると、デプロイ(GitHubのコードを適用すること)の方法を設定できる。上のAutoで設定しておくと、GitHubでコミットすると自動的にデプロイしてくれるので楽。最初の1回はマニュアルでポチっておく。
-Settings
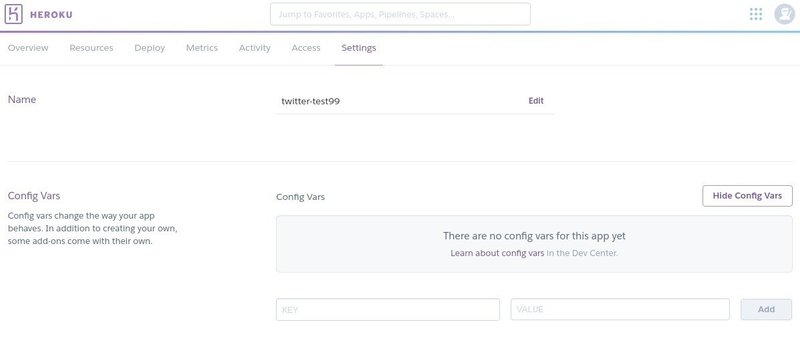
次に環境変数をセットしていく。上記のConfig Varsに設定。
AWS_ACCESS_KEY_ID を左に、 XXX取得したキーXXX を右に。””などで囲む必要はない。
今回はAmazonの4つと、Twitterの3つを設定しよう。
-実行テスト Run Console
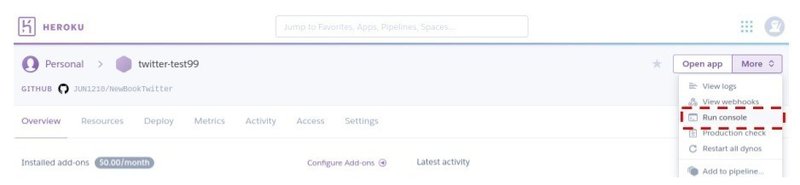
ここまでで実行できる準備はできているので、コンソールで実行をテストする。More > Run console で立ち上がるので、python main.pyで実行する。
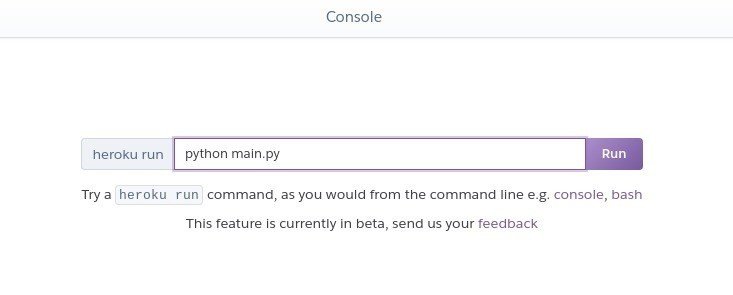
エラーが吐き出されたら、GitHub側で編集、コミットすると自動的に修正される。
-Overview > Add-ons > heroku scheduler (時間を決めて自動的に実行する)
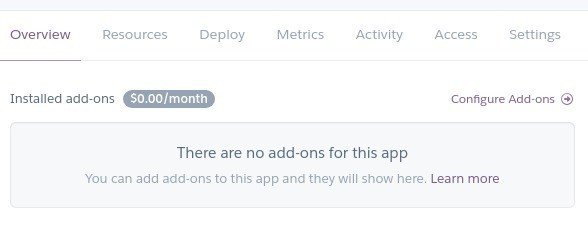
Configure Add-ons から、Heroku scheduler を選択する。Freeのプランで問題ない。
Add new jobから、実行する処理、頻度、時刻を設定する。時刻がUTC設定なので、日本時間ではない点に注意。SAVEで設定した時間通りに処理が実行される。一日に複数回設定したいときは、jobを増やすと良い。
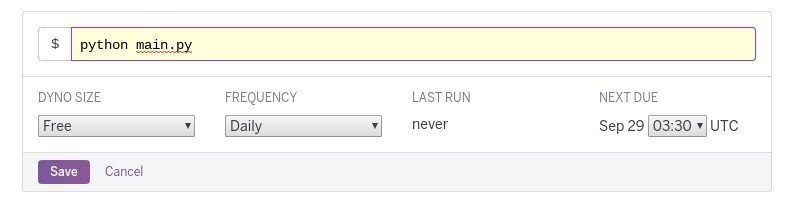
以上までで、プログラムを作成し、自動的に実行するところまでの実装が完了した。
お読み頂きありがとうございました。ご質問やお問合わせ、ご要望、ご質問などは是非twitterにお寄せください。
スタートアップ支援と、社内スタートアップをしながら、実務未経験から独学でプログラミング勉強中。主にpython。スクレイピング、機械学習から始めて、最近はDjangoを学習し、WEBサービス作成中。独学されている初心者の方向けに、技術の記事を中心に書いていきます。