0. 概念モデルとは

はじめに
この一連のマガジンは、現実世界の様々な、モノ・コト・役割等を、理解し、記述し、可視化するためのモデリング技法を解説しています。
”概念モデル”という言葉自体は、一般的な用語ですが、ここで解説するのは、単なる、現実世界の写しの図(絵)を描くだけでなく、記述したモデルから、最新の IT 技術を使って、実際に動く IT ソリューションを構築する事が可能な、実践的なモデリング技法体系です。IT ソリューションの実装に必要なソースコードや各種設定等、実際に動くために必要なソフトウエアの大部分の自動生成も可能です。
このマガジンの内容は、組込み制御ソフトウェア開発を手始めに、大規模組織による組込み制御ソフトウェア開発プロセス改善、マイクロソフトでの組込み機器、パソコン、スマートフォン、クラウド、AI に関する新規技術の継続的かつ迅速なキャッチアップと技術者への普及啓発、IoT や Digital Twins、AI 等の実案件支援など、30年以上の著者の活動から得た、知識と体験がベースになっています。
歴史的経緯
ここで解説する概念モデリングは、1990年近辺に、リアルタイム制御系ソフトウェア開発の方法論として提唱された、Shlaer-Mellor 法をベースにしています。Shlaer-Mellor 法は、UML(Unified Modeling Language)の標準化に伴い、現在は、xtUML(eXecutable and Translatable UML)と名称変更し、ワールドワイドのユーザー会が実践を継続している方法論です。
この方法論は、単なるモデルの作成にとどまらず、そのモデルを様々な実装プラットフォームで実際に動かすためのプログラムコードを手に入れるための、設計・実装方法も定義されています。
世界中で日々リリースされるソフトウェアの量は膨大なので、全体に比べればごく少数ではありますが、この方法論を使って分析・設計・開発されたソフトウェアも多数実際に稼働しています。私も90年代後半から2000年代初頭にかけて、この方法論を活用し、商品化され実際にユーザーに使われている製品の制御ソフトウェアを開発した経験を持っています。
この方法論は、大きく三つの柱から成り立っています。
ドメイン分割
概念モデリング
変換による実装
この方法論が提唱されたのは1990年代初頭、そして、私がこの方法論で実際の製品開発を通じて実践したのが2000年前後。あれから既に20年以上の月日が経過しました。組込み機器向けの HW、OS も様変わりし、サービス側も、メインフレーム、オンプレサーバー、クラウドと進化し、ミドルウェアやライブラリ群はそれに合わせて様変わりしました。ソフトウェアの開発環境も劇的に進化しています。その間、私はマイクロソフトのエバンジェリストとして日々リリースされる新しい技術・製品に対し、この方法論を応用して理解とキャッチアップを行い続け、2010年くらいからはお客様の IoT ソリューション導入時の技術支援でもこの方法論を暗に応用・活用し続けました。
それらを通じて、この方法論の有用性を常に感じ続けていましたが、残念ながら、ここ20年近く、xtUML に関する書籍も記事もほとんど新しく出現することはありませんでした。
振り返れば、90年代から2000年にかけては、”方法論戦争”と呼ばれた時代でした。当時は、オブジェクト指向設計開発方法論ということで、Shlaer-Mellor 法の他に、OMT、Booch、Coad Yourdon 等、多数の方法論が提唱され、記法も違えば、対象としている開発工程の範囲も異なるにも拘らず、どちらが優れているとか、そんなくだらない議論が巻き起こっていました。記法は UML に統一されましたが、”何を対象にどう描くか”は個人に任されていて、実際のソフトウェア開発においての実践的なガイドはいまだに存在しないのが現状です。
何故、今、”概念モデリング”か?
DX(Digital Transformation)というバズワードも一時流行っていました。これは、ビジネスに関わる様々なエンティティをデジタル化するのが前提なので、IoT や Digital Twins と同様、優位なソリューションを構築するには、ビジネス世界のモデル化(=概念モデルを作る事)が必要です。
リレーショナルデータベースを使ったビジネスシステムを考えてみましょう。データベースのスキーマ(テーブル)定義は、ビジネスが対象としている様々なエンティティ群が、現実世界の制約に基づいて格納できるようになっていなければなりません。スキーマの定義には、ビジネスにおける現実世界の理解が必須です。
組込み機器のリアルタイム制御ソフトウェアを考えてみましょう。正しい制御を行うには、その対象となる物理現象の特性や制約を理解していなければなりません。
日々の業務における経費精算や予算執行発注、顧客管理で使う社内システムを使いこなすためには、その背景となっている、法律や慣行の理解が必要です。
新しいプログラミング言語やライブラリー、フレームワーク、サービスのキャッチアップを考えてみましょう。キャッチアップの為には、それらが作られた背景、それらの構成要素と構成要素間の関係、及び、他の技術との関係性等、つまり、それらの対象世界を理解しなければなりません。
他にも多くの例を挙げることはできますが、要するに、ある目的をもって作業を進める際、その対象を理解し記述することは、大前提の必須の作業だという事です。
”概念モデリング”は、対象世界を”知識体系”として記述するための技法です。例に挙げたように、IoT や Digital Twins、リアルタイム制御等のソフトウェア開発に限らず、皆さんの日々の生活のありとあらゆる場面で活用できる技法であるといえます。
私がプロの技術者としてソフトウェア開発を始めた1990年ごろは、インターネット黎明期で、スマホやクラウド等、今や当たり前に使われている製品や技術・サービスは何もありませんでした。あれから三十有余年、ビジネス要件は複雑かつ多様になり、IT 技術も日進月歩で高度化してきました。
単純な世界を理解するには、一般的な国語力や数学力があれば十分ですが、複雑さや規模が大きくなった場合には、それに見合った適切な技法や論理体系が必要になります。
無手勝流でとりあえず作り始めて稼働したものの、規模や複雑度が増大して、機能の拡張や障害対応もままならず、かといって作り変えて最新技術に移行する事も出来ず、使いにくくて人的コストを食いつぶすだけのシステムを運用でカバーしながら使い続けている様な場面にも相当数出くわしてきました。
そんな風景を横目に見つつ、90年代に習得した Shlaer-Mellor 法ベースのモデリング体系を陰に日向に実践しながら、30年以上に渡って、最新技術のキャッチアップ、技術の普及啓発、実プロジェクトの支援に携わってきました。
そんな中、2020年にマイクロソフトが Azure Digital Twins という Digital Twins ソリューション用のサービスをリリースしました。このサービスを使うためのスキーマは DTDL という JSON 形式の言語で記述するのですが、これがほぼ、”概念情報モデル”に等しいことに衝撃を受けました。
”ようやく世界が俺に追い付いてきたか…”
そして、あらためてネットを見渡せば、発送電分離の電力システムや、Smart City 等、様々なプレーヤーが入り乱れてシステムが構築されていく業界では、既に、OWL をベースに RDF で記述された、概念モデルと同等なモデル群が、既に業界標準として公開されているのを発見し、 IT システムの開発が、概念モデルなしでは不可能なぐらい大規模化、複雑化したのだなと、実感しました。
しかし、残念ながら、それらのモデルがどのように作られたのか、そして、色んな人が独自のモデルを作りたい場合にはどうすればよいか、という疑問に答えてくれる情報はありませんでした。
前述の通り、DX(Digital Transformation)も、ビジネスに関わる様々なエンティティをデジタル化するのが前提なので、当然、ビジネス世界のモデル化は必須なはずです。
昨今流行りの生成系 AI の利用においても、前提となる背景野に関する理解がなければ、適切な質問をすることはできないし、得られた回答も正確には理解できません。この分野でも概念モデルは役立ちそうです。
日々ソフトウェア開発に携わる人々はもちろん、高度に複雑化した社会の状況を相手にしてビジネスに携わるインフォメーション ワーカーたちにとっても、業務の対象となる世界を体系的に可視化することができる”概念モデリング”という技術体系を、一般教養として必要とする時代がきたといえるでしょう。
しかし、現時点では、”概念モデリング”体系なるものは、明確に文書化されて存在していません。つまり、
”今こそ、明確な概念モデリングの技法体系が必要だ!”
そんな考察を経て、私の30年来の経験を元に、xtUML の技法を整理・取捨・選択し、今風の進化した高度なソフトウェア実装技術、及び、ソフトウェア開発環境に合わせてリファインしたもを、「Art of Conceptual Modeling」にまとめた次第です。
公開した一連のドキュメントにおいては、Shlaer-Mellor 法や xtUML という言葉は使わず、敢えて、”概念モデリング(Conceptual Modeling)”という言葉に置き換えました。今や開発で使われているのは、オブジェクト指向を前提としたプログラミング言語であり、コンポーネントやフレームワークを前提としたミドルウェアやライブラリです。今さらオブジェクト指向や UML を前面に出す時代ではないでしょう。
ビジネスシステムの開発における概念モデリングは、そもそもが、”ビジネスの可視化”を目的とするものなので、それを実践するのは、ソフトウェア技術者ではなく、ビジネスパーソンのはずです。記法は UML を使っていますが、ビジネスパーソンにもこのモデリング技法に興味を持ってほしいという動機も、名前からソフトウェア臭のする言葉を置き換えた理由の一つになっています。
”概念モデリング!”という、お固い名称を振りかざすとビビってしまう方も大勢いそうですが、基本は義務教育で習う”集合論”であり、それほど難しいものではないのでご安心を。
「Art of Conceptual Modeling」で使っている用語は、Shlaer-Mellor 法(xtUML)の用語をベースにはしていますが、私のこれまでの体験を通じて独自に意味付けしたものが多数出てきます。一般用語の組合せが多く、ネットで検索すると、全く異なる意味付けが出てくることが多々あります。しかし、その辺はご容赦ください。それぞれの用語は、Shlaer-Mellor 法の特徴である、3つの柱全体においての意味付けが成されています。
”自動車”という一般名詞に該当する車種が星の数ほどあるように、また、数学の方程式に数多の種類があるように、このマガジンで解説する”概念モデリング技法”は、”概念モデリング”という一般名詞に分類されるもののうちの一つであるとご理解ください。
概念モデリング
”モデリング”とは、目的に応じた観点を元に物事や事象に関する情報を抽出し、組織化、体系化して模型、つまり、”モデル”を作る事です。
人間は、視覚や聴覚、触覚といった6つの感覚を通じて収集したデータを元に、脳味噌の中で現実世界のモデルを作成しながら、人生に訪れる様々な場面に対応しながら生きています。あるミッションを複数人で遂行する場合は、それぞれの脳内にあるモデルを共有しなければなりませんが、残念ながら、誰かの脳味噌の中を他人がのぞくことはできません。
それぞれの脳内でモデル化された知識体系を共有するには、データや情報をどのように体系化するかに関する決まり事と、テキストや図で表現するための書き方の決まり事に基づいて、一つのモデルを構築していく作業が必要です。
まとめると、モデリングには、
目的と観点から見た、モデル化対象の世界
主題領域(ドメイン)
データや情報の体系化に関する決まり事
モデリング体系
テキストや図で表現するための書き方の決まり事
記法
IoT は現実世界に存在する機器で収集する”データ”を扱います。Digital Twins は、現実世界のモノ・コト・役割を、デジタル空間上に”データ”を使って写し(現実世界とデジタル空間に同じ様相のエンティティが存在するので双子:Twin)を作って、そのデジタル空間上に保持された”データ”を活用します。
デジタルトランスフォーメーションは、現実世界のモノ・コト・役割がどんなふうになっているかを IT 技術をデジタル化、つまりはデータを活用する訳です。IoT にしろ Digital Twins にしろ DX にしろ、顧客に提供する価値を増やすためにビジネスにおいてやりたいことがあり、それを実現・支援するための仕組みです。このコンテキストにおいての現実世界とは、ビジネスで扱う対象の世界であり、そのビジネスを回していくのに考慮しなければならないモノ・コト・役割がデジタル化の対象になります。
見える化の基本
”ビジネスで扱う対象の世界”(以降、ビジネス以外の様々な目的や視点・観点から見た対象世界も含めモデル化対象の世界を”対象世界”と呼ぶことにします)を見える化するモデルを、以下の条件を満たすものとして定義します。
対象世界において、そのコンテキストに則った意味を持って存在する全ての”何か”に対して、対応する”言葉や記号による記述”が、作成されたモデルの中に存在し、一対一の対応付けが可能である
逆に、作成されたモデルの中の”言葉や記号による記述”は、対象世界のコンテキストに紐づいた”何か”の、どれか一つに一対一の対応付けが可能である
この二つの条件により、モデルの記述を通じて、対象世界を正しく把握する事が出来ます。
ここまでの説明、「なんのこっちゃ?」と思われている読者が大勢いそうです。”対象世界の何か”と言われても、「今晩の夕飯何が食べたい?」と聞かれて「何でもいいよ」と言われたぐらいな感覚でしょう。以降、いくつかの例を挙げながら、”対象世界の何か”に相当するものを説明していく事にします。
概念インスタンス
例として、商品販売のビジネスを考えてみます。この対象世界を頭に思い浮かべると、販売する”商品”やそれを”購入”する”顧客”、等々が思い浮かぶでしょう。例えば、”商品”は、”ノート”や”鉛筆”など、目に見える具体的でそれぞれを区別できるものとして現実の世界に存在します。”顧客”も同様で、”狡噛 慎也”さんや”征陸 智巳”さんなど、その人がいる場所に行けば目に見える具体的でそれぞれを区別できるものとして現実の世界に存在します。
このような、目に見えて具体的で、かつ、それぞれを区別できるものは、”対象世界の何か”に相当します。
では、次に、”購入”を考えてみます。”購入”は、商品や顧客とは異なり、目に見える具体的なものとして存在してはいませんが、’購入’という概念的な意味を伴った’行為’として、確かに現実の世界に存在するのは間違いありません。また、それぞれの”顧客が商品を購入する”というそれぞれの行為は区別する事が出来ます。この様な、目には見えないけれど、概念的な意味を伴って、それぞれを区別できるものも、”対象世界の何か”に相当します。
商品販売のビジネスを更に頭の中で思い浮かべると、顧客は必要な商品を指定して”注文”し、その注文に従って必要な数だけ商品を”在庫”から”引当て”て、商品を”配送”するといった事も思い浮かぶと思います。これらもまた、目に見えるか具体的か概念的かに関わらず、同様に、対象世界に存在し、それぞれを区別できるので、”対象世界の何か”に相当します。
”概念モデリング”では、「目に見えるか具体的か概念的かに関わらず対象世界に存在し、それぞれを区別できるもの」の事を、”概念インスタンス”と呼びます。
特徴値
次に、もう一度、”商品”について考えてみます。先ず頭に浮かぶのは、 ”色”や”価格”、などでしょう。他にも、商品販売のビジネスという観点からは、”商品名”や”商品コード”といった言葉を使って表されるものもありそうです。より具体的に見ていくと、これらの言葉で表されるものは、それぞれの商品ごとに具体的な”値”を持つことになります。例えば、ノートなら”色”は’ピンク’、”価格”は’98円’、”商品名”は’A4ノート’、”商品コード”は’BG-032-0074’、鉛筆なら”色”は’ワインレッド’、”価格”は’10円’、”商品名”は’HB Black’、”商品コード”は’BG-071-0118’といった具合です。
これら、”値”を持つ”言葉で表されたもの”も、”対象世界に存在する何か”に相当します。こちらは、”概念インスタンス”とは異なり、それぞれ単体で存在するものではなく、存在するどれか一つの概念インスタンスに紐づいて存在します。ノートや鉛筆の例で判るように、特定の一つの概念インスタンスに複数の値が紐づいて、その概念インスタンスの特徴を記述することになります。
”概念モデリング”では、「値を持つ言葉で表されたもの」の事を、”特徴値(Property)”と呼び、それぞれの概念インスタンスの具体的な値のことを、”特徴値の値”と呼びます。
例に挙げた、”色”、”価格”、”商品名”、”商品コード”は、
”色”の値 - ”色彩の和名”で決められた文字列
”価格”の値 ‐ 円を単位とする自然数
”商品名”の値 ‐ 商品を表す適切な文字列
”商品コード”の値 ‐ ”BG-{3桁の数字:製造会社ID}‐{4桁の数字:商品番号}”で規定されたフォーマットに従う文字列
の様に、それぞれの値を規定する、対象世界のコンテキストに基づいた形式や単位を持っています。
顧客についても同様に考えると、”顧客名”、”連絡用メールアドレス”、”住所”、”電話番号”といった特徴値が、”顧客”のそれぞれの概念インスタンスに対して、それぞれのデータ型に則った値を持って紐づいている事になります。
このような、値の”形式や単位を規定”するもののことを、”データ型”と呼びます。この”データ型”も、”概念インスタンス”、”特徴値”と同様、”対象世界に存在する何か”に相当します。
”データ型”は、”購入”の時の説明と同様に、目に見える存在ではありませんが、”データ型”が無ければ、”特徴値の値”は意味をなしえません。”データ型”は、目に見える存在ではありませんが、それぞれの概念として明確に区別が可能であり、対象世界における必須の存在です。
それぞれの概念インスタンスは、それぞれが区別できるように、モデル化がなされなければなりません。そうでなければ、”対象世界に存在する何か”と”モデルに記述されたもの”を双方向で一対一対応をとる事が出来ないからです。そのため、それぞれの概念インスタンスは、それぞれを識別するための区別可能な値を持った特徴値が紐づけられていなければなりません。このような対象世界のコンテキストによって、唯一つの特徴値の場合もあり、複数の特徴値が組わさってその一意性を示す場合もあります。
※ 言い換えると、モデル作成者が対象世界をどう理解したかに関わっている
概念インスタンス間の意味的な紐づけ:リンク
ここまでで、”対象世界に存在する何か”に相当するものとして、
概念インスタンス
値を持った特徴値
特徴値の値を規定するデータ型
を挙げてきました。概念モデリングでは、これらに相当する”対象世界に存在する何か”を抽出し、名前と意味を言葉で記述していくのですが、この三種類だけでは、対象世界を記述するモデルにはなりません。
商品販売のビジネスの例で挙げた、”顧客”について考えてみます。これまで”顧客”という言葉を安易に使ってきましたが、より深く考えてみると、この言葉には、客として扱う主体が存在する事が示唆されていることに気がつきます。ここでは、その主体を”店舗”であるとしておきます。すると、”顧客”のそれぞれの概念インスタンスは、”店舗”のどれか一つの概念インスタンスと、対象世界のコンテキストにおける何らかの意味付けにおいてつながっているといえるでしょう。この意味的(概念的)なつながりの事を、”概念モデリング”では、”リンク”と呼ぶことにしています。
モデルにおいて、単に、”顧客”や”店舗”のそれぞれの概念インスタンスが、言葉や図で記述されているだけでは、その顧客の概念インスタンスが、どの店舗の概念インスタンスにとっての客なのか分からないのは自明でしょう。それぞれの顧客の概念インスタンスが、どの店舗の概念インスタンスに紐づいているかを表すには、その二つを紐づける”リンク”の記述がモデル上には必要になるわけです。加えて、それぞれの”リンク”は、顧客と店舗の概念インスタンスを一つづつ選ぶと、どの”リンク”なのか確定する事が出来ます。つまりはそれぞれの”リンク”は識別可能だという事になります。
よって、二つの概念インスタンスを紐づける”リンク”もまた、”対象世界に存在する何か”に相当することになります。
更に、”リンク”についても、それぞれの”概念インスタンス”の区別を可能にする識別子的な特徴値が必要だったのと同様に、モデル上でそれぞれのリンクを識別可能にする特徴値(参照特徴値)が、リンクの両端のどちらかの概念インスタンスに存在しなければなりません。
これで、”概念モデリング”に、”対象世界に存在する何か”に相当するものが一通り揃いました。
概念インスタンス
値を持った特徴値
特徴値の値を規定するデータ型
概念インスタンス間の意味的なつながり=リンク
本稿で解説している”概念モデリング”に限らず、データ駆動型開発や、オントロジーなど知識の構造をモデル化する技法においても、この四種類を基礎として記述するものがほとんどなので、ここでの解説は特殊な話ではないとおもってください。
一般的には、最初の3つがフォーカスされがちですが、現実の世界の知識の構造を記述する場合には、実は、4番目のリンクが一番の肝になるという事を覚えておいてくださいね。
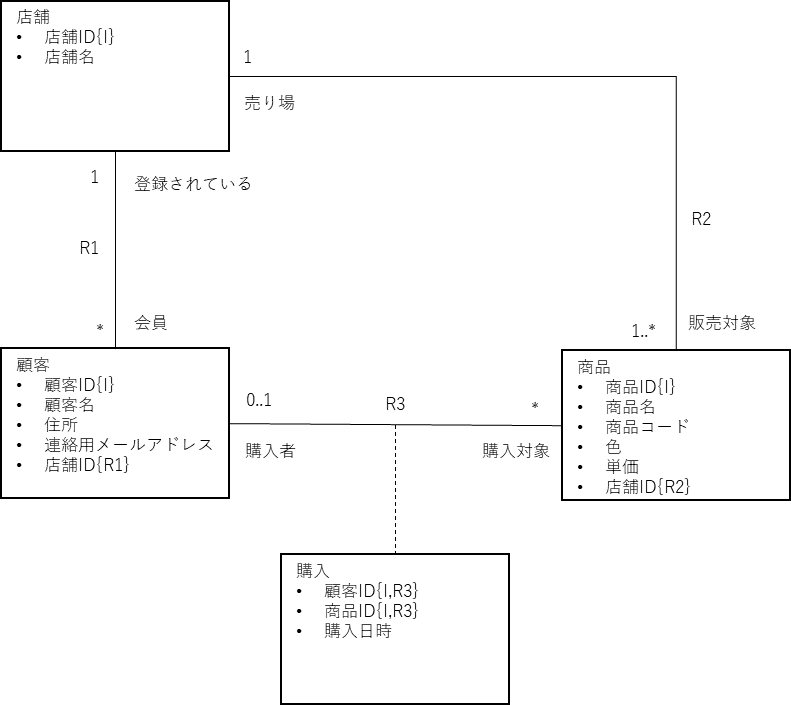
概念クラスと関係(Relationship)
概念モデリングにおけるモデル作成においては、これまで説明してきた、”対象世界に存在する何か”を、”概念インスタンス”、”値を持つ特徴値”、”データ型”、”リンク”の4種類のどれかとして抽出(発見・認識・定義)から始めることになります。
抽出した4種類を、以下の様式でテキスト記述と共に図示化する事を考えてみます。
概念インスタンス → 角が丸い四角で記述
値をもった特徴値 → 該当する四角の中に値と名前をリストで記述
データ型 → 名前と共にテキストで説明文を記載
リンク → 角が丸い四角を線でつなぎ、両端に、それぞれの意味をテキストで記述
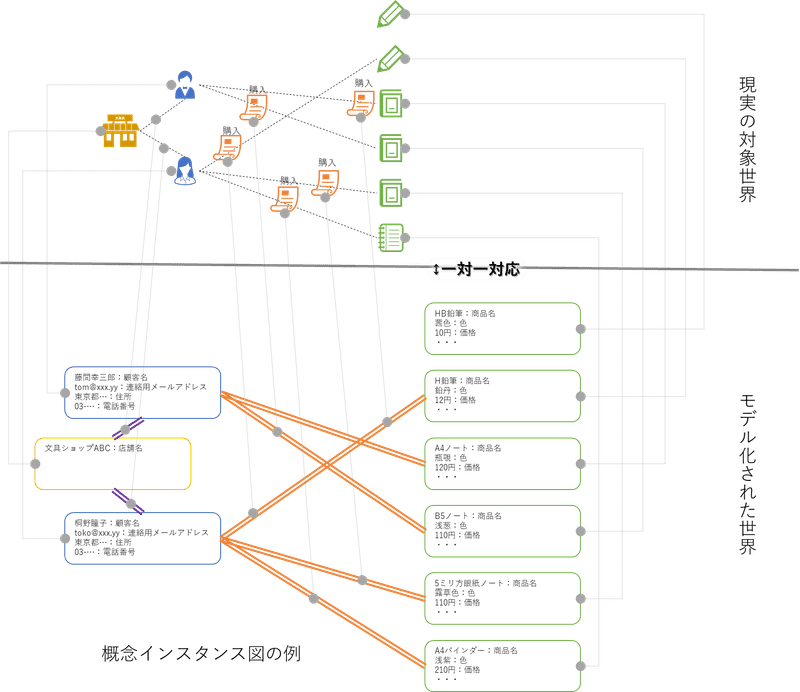
この様な図を、便宜的に”概念インスタンス図”と呼ぶことにします。
この図は、上下の項目が一対一対応しているので、その時々の顧客や商品、店舗ごとに特化した図であることは一目瞭然ですね。店舗が仕入れる商品を変えたり、顧客の登録変更など、何らかの変化が発生したら、モデル作成作業にどんな影響を与えるでしょう。
折角労力をかけて作成したモデル図は、対象世界と一致しなくなるので、変化が発生する度に、対象世界と一致するように書き換えなければなりません。
こんなモデリング体系を採用して始めたしまったら、モデルの修正だけで人生は終わってしまいます。
そんなつまらなくて価値のない一生を送らないように、”概念モデリング”では、もっと安定したモデルを相手にします。
先ず、概念インスタンス群を対象世界において、
同じ意味を持って存在する
同じ意味、データ型を持つ特徴値の組を持っている
という二つの基準で分類し、それぞれについて適切な名前を付与した、”概念クラス” を定義します。分類は英語で、Classify と言い、分類した結果なので、”概念+クラス”と呼ぶことにしています。
対象世界から抽出し定義される全ての概念インスタンスは、モデル上で定義された概念クラスのどれか一つを雛形とし、その概念クラスの定義に必ず従うものとします。
概念クラスは、名前と、元になっている概念インスタンスの特徴値の組として定義されます。逆に、ある概念クラスを雛形にして存在する概念インスタンスは、雛形になっている概念クラスで定義された特徴値全ての値を必ず持つことになります。
概念インスタンス図には、概念インスタンス群だけでなく、直線で表現されたリンクも複数記述されています。これらのリンク群は、それぞれのリンクが、対象世界において
リンクの両端のそれぞれの概念インスタンスが雛形とする概念クラスが同じである
リンクの両端がどちらも同じ意味で存在する
という二つの基準で分類し、”関係(Relationship)”として定義します。
※ ”関係”という用語が一般用語過ぎるので、Relationship と書くこと多々ありです
”関係(Relationship)”は、”概念クラス”が”概念インスタンス”の雛形であると同様、”リンク”の雛形であるといえます。”関係(Relationship)”は、”概念クラス”間に対して定義され、両端それぞれに”リンク”の両端で定義されていた、対象世界における”意味”がそのまま付与されて定義されます。加えて、モデルのレビューや管理で便利なように、モデル内の他の”関係(Relationship)”と異なるような名前を付与します。実際にモデルを作成してみればすぐわかるのですが、概念クラスへの名前の定義の時とは異なり、対象世界上でのコンテキストで名前を付けるのがとても難しいので、”R1” 等の形式的な名前付けで構いません。
また、”関係(Relationship)”の定義では、その両端それぞれに対して多重度を定義します。
前に例として挙げた”顧客”と”店舗”の概念インスタンス間に張られたリンクを考えてみます。
商品販売のビジネスを対象とする世界において、一人の顧客はひとつの店舗にのみ顧客登録が可能だとします。常識的に考えて一つの店舗では複数人の顧客が登録されていると考えるのは妥当であろうということで、それは良しとして、商品購入できるのは、ある店舗に顧客登録された人だけだという状況であると仮定します。その場合、モデル化された世界では、
’顧客’の概念インスタンスが一つ存在したら、その概念インスタンスは、’店舗’の概念インスタンスの一つに、’登録先’という意味において張られたリンクが唯一つ必ずある
ひとつの’店舗’インスタンスに対して、’登録された’という意味において、複数の’顧客’ の概念インスタンスと張られたリンクが複数存在する
のような定義になるはずです。’顧客'と’店舗’の概念インスタンスの間に張られたリンクの数を、それぞれの雛形の”顧客”と”店舗”のそれぞれの概念クラス側から見た場合、”顧客”と”店舗”という二つの概念クラスの間に定義された”関係(Relationship)”の多重度は、
”顧客”から”店舗”を見た場合は、リンクがただ一つだけ存在するので、’関係(Relationship)’の、”店舗”側の多重度は”1”
”店舗”から”顧客”を見た場合は、リンクが複数存在するので、’関係(Relationship)’の、”顧客”側の多重度は、”多”
と定義することになります。
本稿の”概念モデリング”においては、”関係(Relationship)”の多重度は、以下の、4つの多重度だけを使います。
1 - 必ず一つだけリンクがある
0..1 - リンクが無いか、あっても一つだけリンクがある
* - リンクが無いか、ある場合は複数リンクがある
1..* - 必ず一つ以上のリンクがある
経験上、この4つだけで十分です。概念モデリングにおいて、多重度の定義は非常に重要です。多重度がちょっと違うだけで、対象となる世界の様相は一変してしまうので注意が必要です。
概念クラス間で定義される”関係(Relationship)”については、他に、分類を細分化する”Super-Sub の関係”や、関係(Relationship)に一つの概念クラスが紐づいて定義される”関係クラス”もあるので、詳細は、”概念情報モデル”を参照してください。
概念インスタンスは、雛形の概念クラスに定義された全ての特徴値に対して値を持つだけでなく、雛形の概念クラスに対して定義されている”関係(Relationship)”で定義された意味や多重のの制約も、同時に満たさなければなりません。
ここで、ここまで説明してきたモデル上の”概念クラス”と”関係(Relationship)”と、”対象世界に存在する何か” の対応を整理しておきます。
前述の概念インスタンス図で記述した、概念インスタンス、値を持った特徴値、特徴値のデータ型、リンクの4項目に属するものは、全てが”対象世界に存在する何か”と双方向で一対一対応するものでした。
一方、”概念クラス”と”関係(Relationship)”は概念インスタンス図で記述される4項目に属するものの存在を規定するルールを記述するものです。その論理的帰結として、”概念クラス”と”関係(Relationship)”で記述されるモデルは、”対象世界に存在する何か”の構成を規定するルールを定義するものであるといえます。
”概念クラス”と”関係(Relationship)”で記述されるモデルの事を、概念モデリングでは、”概念情報モデル(Conceptual Information Model)”と呼び、図で表現したものを”概念情報モデル図(Conceptual Information Model Diagram)”と呼びます。
※ より詳細に言えば、”概念情報モデル”の構成要素は、”概念クラス”、”関係(Relationship)”だけでなく、”データ型”も含まれます。説明上煩雑なので省略しました
概念情報モデル
概念情報モデル図を、以下の形式で描くこととします。
データ型 ‐ 名前と共にテキストで説明文を記載
概念クラス ‐ 四角で表現、四角の上部に名前を記載し、特徴値をその下に列記
関係(Relationship) ‐ 概念クラスの間に直線を引き、中央に名前を付与、両端に、意味と多重度を記載
この図は、概念インスタンス図とは異なり、”対象世界に存在する何か”の構成を規定するルールを定義するものです。
概念モデリングでは、この”概念情報モデル”を作り出すことが最重要な作業です。”概念情報モデル”を作成する過程は、単なる四角と線を描くお絵描きではなく、”対象世界に存在する何か”の表層ではなく、それを背後で支える、ルールや構造(知識の構造とも言う)を抽出して理解し、記述する事、であるといえます。
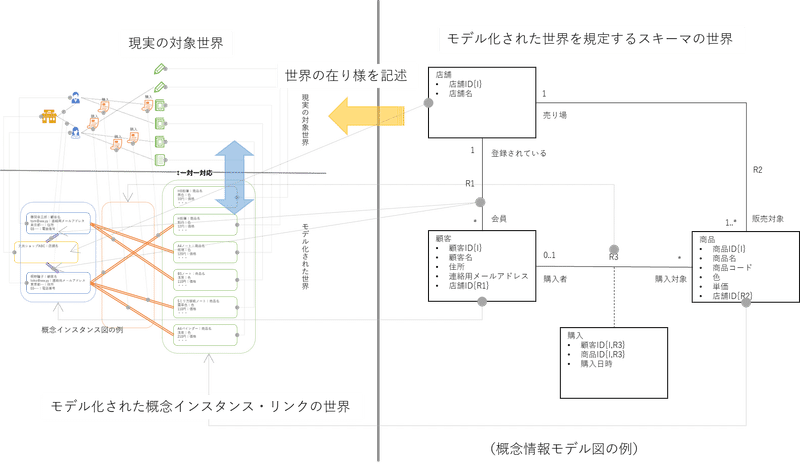
概念情報モデル図の描き方は、「概念情報モデル」で解説しています。
最初のうちは、「こんな線でつながった四角をたくさん描いて何の足しになるの?」という疑問が浮かぶと思うので、「概念情報モデルを使う」で使い方を学んでください。
概念モデリングでは、概念インスタンス図で描く世界と概念情報モデル図で描く世界を明確に区別する事と、常に、概念情報モデルの側で物事を考え、世界を観察していく事がとても重要です。
例に挙げた商品販売において、R1 の店舗側の多重度が ”1” になっていますが、これを試しに”0..1” に変えてみます。元の多重度の時は、顧客として存在する概念インスタンスの、例えば、”藤間 幸三郎”さんは、必ずどこかの店舗の会員でなければ、商品の購入はできないことになります。一方、”0..1”の場合は、会員登録がなくても商品購入ができるという事になります。前者は一見さんお断りのビジネスなのに対して、後者は一般的な店舗売りのビジネスであることになり、現実世界のビジネスモデルが全く違うものになります。概念モデリングにおいては、概念クラスの抽出はもちろん重要なのですが、それ以上に、概念クラス間の関係(Relationship)の抽出が重要であることを肝に銘じておいてください。
より深い考察を「”商品販売”を例にした、概念モデルチュートリアル」で紹介しています。前述の商品販売の例には多くの曖昧さを抱えています。概念情報モデルの作成過程でそれらが洗い出されていく過程も紹介しています。
スキーマ定義としての概念情報モデル
ここまでの説明は、IoT や Digital Twins、DX といった IT 技術によるビジネス ソリューション開発との関連は、敢えて薄めにしてきました。
概念モデルをIT ソリューションに変換していく方法は、”概念モデルを IT システムに組み込む”で詳細に説明しているので、そちらを見ていただきたいのですが、より具体的なイメージを持ってもらうために、概念情報モデルの活用について、簡単に紹介しておきます。
概念情報モデルは、これまで説明してきた通り、特徴値(の定義)の組が紐づけられた概念クラス群と関係(Relationship)群から構成されます。
ビジネスシステムを開発するという事は、”ビジネスを対象とする世界”に含まれる様々な事項をデータとして保持・更新・共有する仕組みを持つシステムを開発する事を意味します。
これまでの解説から、この、”様々な事項をデータとして保持”した状態が、概念インスタンス図で記述された内容と一致するという事は自明だと思います。IT システムにおいて、この様なデータ保持に使われる一般的な仕組みは、リレーショナルデータベースでしょう。リレーショナルデータベースでは、複数のテーブルが用意されていて、各データは、該当するテーブルにレコードとして保存され、テーブル間に定義されたリレーションシップによって、レコード間の参照関係が保たれているようになっています。
つまりは、
テーブル群に保持されたレコード = 概念インスタンス図
テーブル群の定義 = 概念情報モデル
という関係になります。実際、作成した概念情報モデルから、リレーショナルデータベースのテーブル群とテーブル間のリレーションシップ群を構築する SQL 文を作り出すのは、非常に簡単です。
テーブル群の定義の事を”スキーマ”と呼びます。この呼び方に従えば、
概念情報モデルは概念インスタンス図のスキーマ定義である
と言ってよいでしょう。
また、データの保持を Azure Digital Twins で行う場合は、現実の世界の状況を保持するのは Twin Graph で、そのスキーマは Twin Model と呼ばれています。概念モデリングとの対応付けは、
Twin Graph = 概念インスタンス図
Twin Model = 概念情報モデル
になります。こちらも、概念情報モデルを、Twin Model を定義する為の DTDL に変換は容易にできます。
ちなみに、NoSQL を使う場合、明示的なスキーマは定義しない事にはなっていますが、各レコードを得手勝手なフォーマットでデータを格納してしまうと後で収集がつかなくなるので、それぞれのレコードのフォーマットにはある程度の規定が必要で、これらがNoSQL の場合のスキーマになると考えられます。このスキーマ定義でも、概念情報モデルが有効活用できることは言うまでもありません。
”ビジネスの見える化”の第一歩は、ビジネスで実現したいことを支えるデータ群の定義と整理という構造化を行う事です。
概念モデリングでは、それを、概念インスタンス、概念クラス、Relationship の発見・抽出を通じて行っていくのですが、最終的には、概念クラスと Relationship のみに着目した”概念情報モデル”を作成することにより、データ構造を定義します。
例に挙げた”商品販売”を考えてみてください。その時々の存在する概念インスタンスの状況は様々です。顧客や商品は増減するでしょうし、注文は生まれては消えていきます。工場の生産設備管理については、複数の工場をかんりするのであれば、工場ごとのフロアーの数、フロアーごとのラインの設備状況、製造装置の構成はバラバラで多彩です。
このため、概念インスタンスをモデル化対象としてしまうと、星の数ほどのモデルを描かなければならなくなります。例え、数枚のモデル図が定義できたとしても、カバーできるのは極わずかなので、そんな多様なモデルを元に開発したシステムは、ちょっと現実世界に変わっただけで作り直しになってしまいます。
安定したデータ構造
作業を安定させるには安定した土台を元に作業を進めるのが鉄則です。
概念モデリングでは、個々の存在を表す概念インスタンスではなく、その分類の”概念クラス”と”Relationship”に着目してモデルを定義します。
考えてみてください、個々の顧客や商品がどれだけ変わっても、その時々の注文がいくつあっても、それぞれの注文には、発注元の顧客が居て、注文対象の商品があるという、情報の構造が変わることはまずないでしょう。生産設備管理についても、どんな構成であろうと、フロアーはどこかの工場にある、ラインはどこかのフロアーに敷設されている、製造装置はどこかのラインに設置されている、という情報の構造は、こちらも変わり難いものです。
ビジネスで扱う諸概念について、概念情報モデルの作成を通じて、この変わり難い構造を抽出していく事、そしてその変わり難い情報の構造をベースに作業を進める、これが概念モデリングの基本です。
例に挙げた、”商品”、”顧客”、”工場”、”製品装置”、…は一般名詞です。ビジネスの内容は言葉を使って記述していくのは明らかですが、一般名詞のみの羅列では、書き手が頭に思い描いている実体を、3か月後の書き手自身も含め、読み手が思い浮かてくれることは期待できないのは容易に想像がつくでしょう。概念情報モデルでは、ビジネスにおける主体や対象を概念クラスに分類・抽出し、定義します。”概念クラス”は”名前”だけでなく、それを特徴づける”複数”の”命名された特徴値”を持ちます。概念モデリングの過程で、抽出したそれぞれの”概念クラス”と”特徴値”が、現実世界の何に相当するのかを理解を助ける簡潔な説明文を付与します。これらは、関係者間のコミュニケーションで生まれる誤解を最小限にとどめる手助けになります。加えて、”概念クラス”間に張られた”Relationship”は現実世界の実体がどういう関係にあるかの意味付けを明確にしてくれるので、更にコミュニケーションにおける相互理解を深めることになります。
概念モデリングを習得する上で、一番重要なのでここでも敢えて説明を繰り返しますが、現実の世界にあるモノ・コト・役割といった諸実体に対応するのは、概念クラスではなく、概念クラスを雛形にした概念インスタンスであることを忘れないでください。ある概念クラスを雛形にした全ての概念インスタンスは、概念クラスに定義された全ての特徴値に現実世界を反映する確定した値を持っていることも忘れないでください。
また、コミュニケーションの過程では、話者が頭に描いているビジネス上の懸念点を記述するデータに相当する”概念クラス”、あるいは、”特徴値”、あるいは、”Relationship”が無いという、概念情報モデルに捕捉しきれていなかったビジネス上の概念や実体が見つかる事があります。この場合は、書けていると思われるモノ・コト・役割が、モデル化対象と同じ土俵の問題(ドメイン)かどうかを話し合い、同じであれば、概念情報モデルに、その足りない観点を追加して概念情報モデルを成長させていく事になります。
ドメイン
一般的なソフトウェア開発技法の紹介では、”ドメイン駆動型開発”が有名です。ドメイン駆動型開発の”ドメイン”は、主に、システム開発時のアプリケーション要件の範囲を意味する言葉として使われています。
概念モデリングでは、一般的に使われているドメインという言葉が指す意味内容より、もっと広い意味で使っています。
概念モデリングでは、アプリケーション要件の範囲を”アプリケーションドメイン”として扱うだけでなく、システム開発で使用する、サブシステムやミドルウェア、プログラミング言語、実装プラットフォームなどを、それぞれ独立したドメインとして扱います。そして、実装作業は、複数のドメインを組み合わせていく作業であると考えます。
そもそも、何故、様々な業態のビジネスシステムを、C# や Java、Python 等共通のプログラミング言語や、Windows や Linux の OS 上で構築できるのでしょう?それは、プログラミング言語や OS がアプリケーション要件を一切含まないからです。逆に、アプリケーション要件も、本来的にビジネスとして何をやりたいのかという観点においては、ビジネスで扱うデータやデータの流れ、プロセスを考えれば、プログラミング言語や OS は無関係です。
無関係なものは、それぞれ異なる独立した問題領域:ドメインとしてあつかいましょう、という事です。もっと簡単に言えば、異なる問題は、別々に扱いましょうという事ですね。
独立している状況を、Shlaer-Mellor 法のコミュニティでは、”直交している”という言葉を使って表したりもします。
ドメインを適切に分割することは、概念モデリングを上手く進める肝の一つでもあります。特に概念情報モデルを作成している過程では、概念クラスや特徴値の候補としてピックアップしたものが、モデル化対象ドメインとしてふさわしいかどうかの判断を頻繁に迫られます。
この辺りの判断基準は、概念情報モデルを作って実際に動くシステムを構築するというプロセスを何回か経験すると自然に身につくので、四の五の言わずに実践してみるというのが習得の早道です。
世に優秀と言われている人たちが沢山いますが、その人たちの多くは生まれながらにドメイン分割の判断基準を体得しているように思えてなりません。
”ドメイン”に関する詳細は、”ドメインと IT システム構築”と、”概念モデリングに関する圏論的考察”で解説しています。
データ構造を基にしたダイナミズム
現実の世界は、時間の経過とともに刻一刻と変化を続けます。ビジネスの見える化であれば、このダイナミズムの側面も見える化が必要なのは言うまでもありません。一般的に、ビジネスの内容は、簡単な図を伴う自然言語によるシナリオで語られていく事が多いかと思います。ビジネスのダイナミズムも何らかの形式に従って文章や図で記述する必要があります。
昔々にはやった”ユースケース駆動”という開発技法では、ビジネスシナリオを一定の形式に基づいて切り出し文書化しながらシナリオ群を抽出していました。当然のことながら、これらの文章には、その流れにおける”主体”や影響を受ける”対象”が含まれています。ある文章で使われている”主体”を表す単語は、別の文章でもその単語が”主体”として使われている場合もあれば、同じ単語が”対象”として使われている場合もあるでしょう。ビジネスを記述する文章群が全体として整合がとれているためには、前述の考察と同様、複数の文章にばらまかれている一つの単語が全ての場所において同じ意味であることが保証されていなければなりません。
文章で使われているビジネス上重要な”主体”や”対象”を示す単語の意味が曖昧ならば、曖昧な文章群を起点にしたすべての活動は曖昧なものになってしまい、それを読んだ各作業者の主観が入り込んだ不統一なバラバラなシステムが出来上がってしまうでしょう。
概念モデリングでは、ダイナミズムの記述のベースとして、概念情報モデルを使います。逆に言えば、シナリオ等を記述する際には、概念情報モデルで定義された、概念クラス、特徴値、Relationship しか使わないという事です。前のセクションで解説した通り、この様なスタイルでは曖昧さはかなりの程度で排除され、複数の読者の正しい理解を助けることになります。
商品販売においては、”注文”は任意の時点で様々な”顧客”から独立に発注が行われ、それぞれの購買処理が行われていきます。”商品”の仕入れについても、仕入れが行われた時点から仕入れに関する一連の処理が行われていくでしょう。また、工場の生産設備管理においては、”製造装置”の温度や振動などの値が計測された時点で、その値、または変化のトレンドが異常ならば、それに対応した一連のワークロードが進んでいく事でしょう。
概念モデリングでは、これら、”注文の発生”、”仕入れ”、”センサー等の計測によるデータ確定”、…全てを”事象(Event)”として捉え、”事象”をトリガーにして一連の処理が行われていくという”事象駆動(Event Driven)”な世界観で、現実のビジネスのダイナミズムを認識し定義していきます。発生した事象に対する処理の主体は、”概念インスタンス”に紐づけられます。
ここで、読者の皆さん自身が日頃業務を遂行しているときの様を想像してみてください。日々、会社の業務計画や自身の目的に従って、必要な様々な情報を参照しながら作業を行っていくでしょう。作業中に、メールやチャット、電話等からメッセージや依頼を受けた(事象が発生した)時、その時々の状況によって、依頼をこなす作業に切り替えたり、その時点でやっていた作業を継続し、切りのいいところまで先延ばしにするでしょう。また、工場のラインに一列に設置された製造装置群において、ある装置のプロセスが完了(事象発生)して、後続のステップの製造装置に仕掛り品を渡したいとき、構造の装置が準備ができている状態であれば、直ぐにその仕掛り品に対するプロセスを開始できますが、まだ前の仕掛り品のプロセスが終わっていなければ、そのプロセスが完了するまで仕掛り品を渡すことはできないでしょう。つまりは、事象が発生した時、それを受け取る概念インスタンスの状態によって処理の流れが変わるのが、現実の世界の常であると言えるでしょう。この様な描像をモデル化するには、”状態モデル”が適しています。
概念インスタンスは、その雛形である概念クラスで定義された全ての特徴値の値を持つように、概念モデリングでは、”状態モデル”は、概念クラスで定義され、その概念クラスを雛形とする概念インスタンスは、その”状態モデル”に従って振舞うと定義します。存在する概念インスタンスは、その概念クラスで定義された”状態モデル”を雛形にした”状態機械”を持つことになります。
説明がちょっと小難しくなってしまいました。ポイントだけまとめておくのでそこだけは頭に入れておいてください。
ビジネスのダイナミクスを表現する”振舞”の説明では、”概念情報モデル”で定義された語彙を使う
ビジネスシナリオのトリガーを全て事象として捉える
概念インスタンスが、事象発生を受けて、それぞれの状態に応じた処理を行う
各処理に必要な情報は、概念情報モデルの定義に従って取り出す
概念インスタンスの状態は、概念クラスで定義された状態モデルに従う
概念モデリングでは、”状態モデル”、”状態での処理(アクション)”、そして、”概念情報モデル”に従った、概念インスタンスの生成・削除、特徴値の更新・参照、Relationship の切り貼り”を、”概念振舞モデル”と総称しています。詳しくは、「概念振舞モデル」を読んでください。
語彙だけでなくダイナミズムもモデル化によって見える化するので、概念モデルを読み解くスキルがあれば、関係者間でコミュニケーションにおける誤解が発生する余地は更に減るでしょう。
私の経験上、適切な詳細度で記述された概念情報モデルにおける、各概念クラスの状態モデルはシンプルであることが判っています。複雑な現実のビジネスのダイナミクスをシンプルなモデルで記述できると、作成した概念モデルが正しく現実のビジネスを見える化できているか、逆に、当初漠然と頭に描いていたビジネスプロセスの不備や間違いが無いかの検証が容易になります。
概念モデリングに限らず、モデル化という行為おいては、シンプルさがとても重要です。
以上、概念モデリングの概要を、現実のビジネスのデータの観点、ダイナミクスの観点から解説してきました。
ビジネスで扱う様々な概念をデータの観点からモデル化する、”概念情報モデル”
概念情報モデルを基盤とした、ビジネスのダイナミズムを記述する”概念振舞モデル”
これらのモデルは、ITソリューション開発の基盤作業だけでなく、ビジネス戦略の策定や、新規技術やサービスの理解・キャッチアップ促進、複数ベンダーが提供するサービスの機能比較においても威力を発揮します。
概念モデリングにおいては、当然のことながらモデル図を描いていく事になりますが、モデル図は、その時々の目的に応じて、
紙 ‐ 個人でのモデリング検討
ホワイトボード ‐ チームによる正式なモデリングミーティング
PowerPoint や UML描画ツール ‐ 関係者間での共有用、または、公式文書として
概念モデリング専用ツール ‐ 実践的な
等を使う事になります。達人プログラマー数人によるソフトウェアの設計・実装の時とは異なり、現実のビジネスをモデル化する概念モデリングのモデル図はかなりの規模に結果的になってしまうので、紙ナプキンの逸話のようにはいかないのが現実です。ツールを使う場合には、最低限 PowerPoint や Visio でもよいですが、効率の観点から、なるべくなら専用のツールを採用することをお勧めします。
Shlaer-Mellor 法との対応
Shlaer-Mellor 法経験者向けに、参考までに、私の解説しているところの”概念モデリング”と、そのベースとなっている Shlaer-Mellor 法の関係を説明しておきます。
Shlaer-Mellor 法のモデリング体系における用語では、
オブジェクト情報モデル
状態モデル
データフローによるアクション記述
で、モノ・コト・役割、及び、その振舞を記述します。
この3つは、どれも UML の記法に従って記述しますが、使用するモデリング要素は実用上必要十分、かつ、最小限なものに絞られていて、記述したモデルが意味する事を厳格に規定しているので、モデル作成者がモデル作成時にどのように図を描いたら良いか迷うことがなく、また、作成者以外の第三者が見た時も、定義されたモデルの意図を誤解することを最小限にとどめます。
加えて、状態遷移やアクションがどのように実行するのかを規定する実行セマンティクスが明確に定義されているので、記述したモデルを使えば、モデル化した現実の事象を、モデルを動かすことにより動作検証が行えます。xtUML では、方法論で規定されたモデリングを作成・検証可能な BridgePoint というツールをオープンソースで公開しているので、追加投資無く、xtUML のモデルの作成が可能です。
「Art of Conceptual Modeling」では、最初の、”オブジェクト情報モデル” を”概念情報モデル”とし、残りの二つをまとめて、”概念振舞モデル”と命名しています。この二つと”ドメイン分割”を合わせて、”概念モデル”と命名、そして、”ドメイン分割”、”概念情報モデル”、”概念振舞モデル”の3つを行う事を、”概念モデリング”と命名している事を覚えてください。Shlaer-Mellor 法においても、作成する3種類のモデルは、ドメイン分割を前提としたモデルなので、齟齬はありません。ドメイン分割については、「ドメインとITシステム構築」の解説を読んでください。
変換による実装
Shlaer-Mellor 法 では、”変換による実装”によって、定義し、検証したモデルを元に、様々な実装プラットフォーム上で動作するプログラムコードの自動生成が可能です。この過程を今風の技術を使って実現する方法は、「Techunique of Transformation」で詳しく解説しているのでそちらを読んでみてください。
私のこれまでの経験上、正しい記法に基づいて定義されていて、かつ、検証されたものであれば、自動生成できない概念モデルは皆無です。折角汗水たらして脳味噌ひねくらかして概念モデルを作成したのなら、そのまま自動生成でソースコード一式を作ってしまうのが楽なのですが、自動生成環境を設計・開発するのにも手間がかかるのも事実です。ちなみにですが、概念モデルから Azure IoT Hub や Azure Functions、Azure Digital Twins と連動するソースコード生成環境一式を「チュートリアル~モデル化したビジネスを Azure Digital Twinsを活用したソリューションに変換する」で紹介していますが、この自動生成環境は、C# コード生成のコアの部分で約3か月、Azure Digital Twins との連携の部分で2か月ほどかかりました。
ソフトウェア開発で重要なのは、やはりトータルコストでしょう。一部の工程にのみ着目して局所的に改善しても大抵の場合全体効率は向上しないですし、そもそも、”ビジネスをきちんと見える化”した結果としての”コード自動生成”であって、”コード自動生成”が目的ではないので、コード自動生成をするかしないかは、それぞれのプロジェクトでそれぞれの状況に応じて合理的に判断し選択すればよいことです。
扱うドメインによっては、手書きによるコーディングで十分だったり、使用する実装プラットフォームがノーコードでコーディングそのものが必要ない場合もあります。ドメインによっては概念情報モデルすら作る必要が無いものもあります。この辺りは、「概念情報モデルをITシステムに組み込む」に詳しいのでそちらを読んでください。
ただ、アプリケーションドメインについては、私の長年の経験によれば、”ビジネスをきちんと見える化”するためという本来の目的を上手に行うモデリングテクニックというものが存在していて、そのモデリングテクニックに従って定義された概念モデルは自動生成しやすいんですね。「Art of Conceptual Modeling」では、本来の目的に沿って、かつ、今風の実装プラットフォームに適合したプログラムコードを生成しやすくなるモデリングテクニックも含めた上での解説を行っています。
また、「Techunique of Transformation」と、ソフトウェア設計の基本を解説した、「Essense of Software Design」を合わせて読めば、”変換による実装”は、本来のソフトウェア設計・開発・実装の工程でやるべき事を、概念モデル化し、定型化できる部分をソフトウェアで自動化しているだけであることが理解できるでしょう。
考えてみれば、ビジネスを支援する IT システムを構築する為の設計・開発・実装の過程も当然ビジネスなので、それを自動化できるのは当たり前の話ですね。
概念モデルは本当に何でも可視化できるのか?
旧稿 ‐ IT ソリューション開発を前提にした考察
答えは、Yes であり No でもあります。
”どんなものでも可視化できるのか?”を証明するには、ありとあらゆるモデル化対象にチャンレジして成功しなければ証明したことにはなりません。ということで、証明はできないという事で”No”になります。
しかし、”IoT や Digital Twins、Digital Transformation で実現したい何か”に対象を絞れば、これらは、そもそも、現実の世界のビジネスにおける管理したい情報をデータ化・デジタル化する事が前提となっているので、情報のデータ化・デジタル化ができないようなものは対象外のはずです。
一方で、概念モデルは、情報のデータ化の為のデータ基盤を構築するものなので、データ化できる対象であれば、モデルの作成は可能であるといえます。これらを総合すれば、”IoT や Digital Twins、Digital Transformation で実現したい何か”に対しては、なんでも、その何かに対する概念モデルが作成できるということで、”Yes”であるといってよいでしょう。
「データを扱う」と言った時、データ項目とその値は区別して考えなければなりません。データ項目の値は、それぞれ、現実世界のモノやコトに付随する値です。現実世界のモノやコトのそれぞれを、デジタル空間上で区別するには、それらを識別する時間が経過しても不変な値を持つデータ項目(識別子)が必ず必要です。更に識別された個々のモノやコトは、その時々に応じてその特性を表現する変化するかもしれない値を保持するデータ項目が紐づいているのが一般的です。概念クラスは現実世界のモノやコトの分類であり、対応するモノやコトを識別する為のデータ項目と紐づけられたデータ項目は、概念クラスの特徴値(プロパティ)というデータ項目として定義します。現実世界のモノやコトは、それぞれ、それ単体で存在しているのではなく、ビジネスのコンテキストに基づいて、他のモノやコトと関係を持って初めて意味を持ち得ます。逆に言えば、ビジネスのコンテキストに内在する関係を制約として満たさない概念インスタンスは存在できません。概念クラスの特徴値(プロパティ)には、どのモノやコトと関係付いているのかを示すデータ項目(特徴値)も必要であるという事を意味します。
以上のことから、
概念インスタンスは、現実世界のモノ・コトに対応する
現実世界のモノ・コトに紐づくデータの値は、概念インスタンスの特徴値(プロパティ)に格納されている
概念インスタンスが持つべき特徴値(プロパティ)のセットは、概念インスタンスの雛形である概念クラスが規定する
結果として、概念クラスは現実の世界のモノ・コトに紐づいたデータの値をデジタル空間上で保持する為の、箱の定義である
と言えます。この様に考えれば、概念情報モデルの作成は、現実の世界をデジタル空間上でデータとして扱うための、基本的な作業であると言えるのではないでしょうか。
「概念モデルは本当に何でも可視化できるのか?」という問いは、「チューリングマシンが ITシステム構築に必要なロジックの実行を全て実現できるか?」という問いに近いかもしれませんね。
新稿 ‐ 現象学、圏論からの考察
旧稿での説明は、ソフトウェア開発における概念モデリングの役割としては十分だと思っています。ソフトウェア化できる対象であれば、概念モデルによる記述は可能だという結論に変わりはありません。
新稿では、玉石混交マガジンの、
の二つの記事を書いたときの考察を元に、簡単に、概念モデルの記述の可能性について紹介しておきます。詳しくは記事を読んでみてください。
「概念モデルは本当に何でも可視化できるのか?」という問いは、
可視化できるとした場合、それが、対象世界を正しく反映したものなのか?
という問いを含んでいます。この問いに答えるためには、
対象世界を正しく記述した何らかのモデルがア・プリオリに存在する
というプラトンのイデア的な前提が必要です。フッサールの現象学的な見方では、そもそも、そんなアプリオリに存在するモデルはなく、目的達成に関与する人達が合意したモデルが正しいモデルであると考えます。この考え方を進めていけば、どんなモデリング体系でも、作成して関与する人達が合意すれば、それが、対象世界を正しく記述したモデルであることになります。
結局のところ、概念モデリングの体系だけに対する「概念モデルは本当に何でも可視化できるのか?」という問い自体、無意味な問いであるということです。
元々の問い自体は無意味ですが、現象学における認識に関する議論の中では、
ある背景野(世界観)の元、ものごとを区別し、それぞれの状態と関係を記述していく
という手段を用いており、背景野(世界観)を”ドメイン”、物事の区別を”概念クラス”の抽出、状態は”特徴値”、関係はそのまま”関係(Relationship)”、と、概念情報モデルの道具立てとそのまま一致します。
モデリング技法に関する正しさの問いは無意味ですが、世界を認識する手段としては、概念モデリングの技法は正当であるといってよいでしょう。
また、数学の基礎付けでも活用されている圏論においても、公理の構成で使っている基本的な道具立ては、
区別可能なものと、ものとものをつなぐ合成可能な射で構成される圏
であり、概念情報モデルの構成要素と同じです。数学的に公理を論理的に積み上げていくための道具をそのまま土台にしているので、数学的な観点からも、概念モデリングの技法は妥当であると考えて良いでしょう。更には、圏論の範疇で明らかにされている様々な定理や特徴、証明などを、概念モデルや、変換による実装を含む概念モデリングの作業内容にそのまま適用できるので、その論理的な正しさを担保することができます。
以上の考察を踏まえれば、工学的かつ実用上のレベルでは、「概念モデルは本当に何でも可視化できるのか?」に対する答えは、Yes と言ってよいでしょう。更には、数学的に証明された記法を元に記述された概念モデルは、デジタル化もしやすく、作業の進行において、 IT 技術の恩恵を享受できるともいえるでしょう。
実務上の問題点
以上の説明から、概念モデリングの優位性を感じていただけたのではないかと思っています。
しかし、実際にやってみようとすると、途端に高い壁が立ちふさがります。そう、”概念モデリング体系の理解と実際に使い物になるレベルの概念モデルを作れるスキルの獲得”という、学習コストの壁です。
本稿の半分までいかずに、「なんのこっちゃ?」と読むのを放棄した読者は非常に多いのではないでしょうか。
とにかく理屈が多い。。。
学習コストの壁の問題は、著者の30年来の悩みの種です。著者自身も、Shlaer-Mellor 法に出会ってから、その技法体系をきちんと理解するまでに3~4年かかり、実際に使い物になるモデルの作成や変換による実装を実践できるようになるまで、更に3年近くかかっています。
学習コスト問題の解決には、簡単に使えて高性能な概念モデリング用の専用ツールや、高度化した生成 AI 系を活用した、技法の学習支援環境、モデル作成支援の仕組みが必要でしょう。この辺りは、関連諸氏の協力も得ながら、地道に一歩一歩進めていこうと思っています。
まぁ、それ以前に、概念モデリング技法の普及にも、もっと力を入れなければならないのですが。。。
概念モデリングのコツ
私が Shlaer-Mellor 法の習得にいそしんでいた 1990 年代には、DX(Digital Transformation)なんて用語は世の中には存在していませんでした。しかし、コンピュータテクノロジーの利用の本質の一つは定式化出来るところは全部自動化してしまうという点は昔から変わっていないでしょう。
案外、この点が、概念モデリングを使いこなすためのコツなのではないかと思っています。「Art of Conceptual Modeling」の一連の記事では、PowerPoint を使ってモデル図を描いていているのですが、それはあくまでも解説する為の便宜であって、概念モデリングを行う時に、PowerPoint を使ってモデル図を描けと推奨しているというわけではありません。Excel で書けという事でもないです。
想像してみてください。実際のソフトウェア開発で相手にするのは複雑怪奇な現代の問題群です。必然的に、概念モデルは、巨大で見た目に複雑なモデルになってしまいます。そんなモデルの絵を PowerPoint で書いた後に、そのモデルを元にコードを書くという行為が、果たして現実的か?
私は否だと昔から考えています。そんな厳密なモデルを描いたなら、それも、コンピュータを使って描いていて、描いた内容が電子的に読み取れるなら、そこから、コード生成できるものならソフトウェアの実行に必要な最終成果物一式を全部生成できなければ、モデル図を描く意義なんかない!というのが私の意見です。
そして、実際、「Technique of Transformation」で解説している様に、例えば、Shlaer-Mellor 法(eXecutable & Translatable UML)専用ツールである BridgePoint を使って概念モデルを描けば、最終成果物の自動生成が可能なので、BridgePoint を使わない手はないだろうと。
私の概念モデリングの習得の過程を振り返ってみると、”概念モデルからの変換による実装”の原理が腑に落ちた時点で、概念モデリングに対する一種の割切りが出来るようになったのが、概念モデリングを行う最終目的である、”効率よくソフトウェアを開発する” にかなう概念モデルが作成できるようになったエポックでした。概念モデリングを含むモデル図を使ってソフトウェアを開発する場合、モデル至上主義に走りがちです。しかしそんな状況は深く広く広がっているモデル沼にずぶずぶと沈んでいくだけ。
概念モデリングを上手くやるコツは、自動生成を前提にした開発プロセスを採用する事につきます。
しかし、勘違いしないでください。紙やホワイトボード、PowerPoint での概念モデルの各種図の描画に価値は無いと言っているわけではありません。特に概念情報モデルは、個人や数人によるインフォーマルなコミュニケーションにおいて物事を構成する概念を明確化するのに非常に有効なのでどんどん書いてみてください。その際、モデル図をどの程度の詳細度で記述するべきか、その匙加減が必要ですが、その程度を決めるのに、自動生成の仕組みを理解した上でのモデリングに対する割切りは非常に役立ちます。
最後に
以上を踏まえて、先ずは、「概念情報モデル」から順番に読み進めてみてください。
概念モデリングは習得してしまえば、非常に威力を発揮できるものなのですが、特に、”概念情報モデル”の作成スキルの習得は結構難しいです。
「概念モデリングチュートリアル集」や、「概念モデリング~虎の巻」がスキルアップの一助になれば幸いです。
Let’s Happy Modeling!
この記事が気に入ったらサポートをしてみませんか?