(10b程度の)大規模言語モデルが「種々のスキル」を身につけるために必要な要素や学習量を考えるメモ

はじめに
最近は、10bクラスの大規模言語モデル(LLM)が特定のスキルを身につけるのに必要な要素を解明するタスクに取り組んでいます。
このサイズのモデルは、思ったよりも「おバカ」なため、例えば選択肢問題をきちんと解けるようになるためだけに、数百件以上の訓練(ファインチューニング)が必要な事例も出てきました。
本記事では、LLMに身に着けさせる「タスク」の幅を、もう少し増やしながら、挙動を追っていきます。
背景: LLMの理解力はどの程度なのか?
努力 vs 頭の良さ
これまでの検討や経験を踏まえ、筆者は、大規模言語モデルの能力を以下のような図で位置付けています。*
*あくまで個人の見解です。異論は多々あるかと思います。
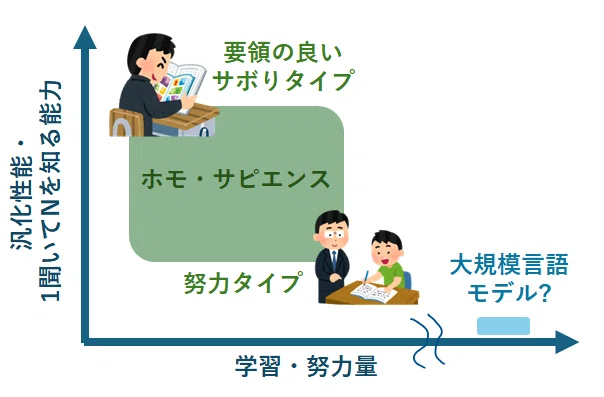
このグラフのy軸は、「頭の良さ」のようなパラメータを表します。
例えば、「1聞いてNを知る」(N>>10)ことができるタイプの学生は、とても頭が良いので、適当な学習教材を与え、少し勉強させるだけで、良い成績を収めることができます(いわゆる、サボり系の天才タイプです)。
それに対し、「あまり賢くない」学生は、テストで好成績を収めるために、綿密な勉強が求められます。学習量はもちろんのこと、テストなどに特化した教材を戦略的に選んで特訓を行うアプローチが有効とされています(≒塾・予備校・過去問・演習問題・…)。
大規模言語モデルの位置付け
筆者は、大規模言語モデルは、「尋常でない努力ができるが、極めて物覚えの悪いタイプ」ではないかと考えています。これを裏付ける事実の一つとして、LLMが圧倒的なデータ量で事前学習を行っている(超人的な努力ができる)ことは、周知の事実です。
LLMの理解力については諸説ありますが、例えば参考になりそうな値として、アルトマンは、「高校レベルの生物学を理解するのに教科書を2千冊も読む必要はない。1冊か3冊あればいいかもしれない」と発言しています。
発言時期を鑑みると、GPT-4は高校レベルの生物学を理解するのに、教科書を2千冊程度、読む必要があるかもしれない、ということを示唆しています*。
*この値は、筆者の肌感とも一致するところです。
普通の高校生は、生物学を理解するために、教科書・参考書・演習問題類などの数冊の書籍を必要とします。例えば5冊必要であるとすると、GPT-4の理解力は、ホモ・サピエンス(成人)の5/2000=1/400程度(!?)、というざっくりした試算ができます。*
*もっと高いかもしれませんし、低いかもしれません。また、理解力という概念を正確に定義するのは難しいという点にも留意が必要です。ただ、GPT-4の理解力が普通の人間の1/100~1/1000程度、という仮説は、あながち大外れしてるわけではないかも?というのが筆者の肌感です。
筆者が今回、検証の対象とするLLMは、ご家庭のGPUでも回せそうな、10bクラスのサイズです。GPT-4は2000b程度と噂されていますので、パラメータ数の違いを鑑みると、10b クラスのLLMの理解力は、ホモ・サピエンスの数千から数万分の1程度ではないかと推察します*。
*このクラスのLLMは、なんとなくの日本語は喋れるけど、指示を正確に理解しているようには思えません(1-2歳レベル?)。なので、肌感としても、妥当なラインであると考えています。
1を聞いてN (N<<1)を知るLLMに何を教えるべきか?
ここで申し上げたいのは、10bクラスのLLMの理解力は、とても低いということです。何かを覚えるためにも、相当数の訓練が必要な可能性があります。また、覚えた何かを、他の類似タスクに応用する能力も限定的(汎化性能が低い)可能性もあります。まさに、「1を聞いてN(N<<1)を知る」という状態です。
人間とのアナロジーで考えると、「おバカなLLM」に何かを身に着けさせるためには、「きちんとタスクを想定し、徹底した訓練を行う」必要があるかもしれない、という仮説が浮上します。
本記事では、「特定のタスク」*をこなすために、LLMがどの程度の学習データを必要とするのか、検証していきます。
*本記事で扱うのは、出力形式や回答が一意に定まるような、「きちっとしたタスク」です。文章生成のような、回答の多様性が重視されるタスクについては、全く異なる考え方が必要となる点に注意が必要です(例: LIMA論文, こちらの末尾なども参照)。
扱うタスク
タスク内容と論点
llm-jp-evalと呼ばれる評価セットを用います。こちらの評価セットは、本来、文章理解の能力を測るために作られたものです。しかし、この評価セットでは、「選択式問題に数値で答え、他には何も回答しない」、「単語を抜き出す」のような、出力形式が厳密なタスクが多く存在します。
例えば選択式問題に単語で答えてしまったら、不正解とります。そのため、実はllm-jp-evalセットで高得点を出すためには、
a)問題の意図を理解する
b)問題を解く
c)指定の出力形式で回答する
の3段階のタスクをこなす必要があります。
ここで、b)は、BERTなどのLLM以前のモデルでもそれなりの性能を出せることが分かっています。
であるとすると、実は、10bクラスのローカルLLMにとっての主要な関門は、「a)問題の意図を理解 + c)ルールを守って回答を行う」という「タスク」をこなせるかどうかではないか、という仮説が浮上します。
実際、4/1の検討において、事前学習のみを終えたllm-jp-13bモデルが、選択式問題を解けるようになるためだけに、数百件以上の専用の訓練を行わなければならなかった、という結果が得られました。*
*スコアを決める実質的な要素は、「選択肢問題の訓練数」で、他のタスクや指示データセット(Jaster全般、dolly, oasst, ichikara)を学習させても、能力向上を観測出来ませんでした。これは、当該LLMの汎化性能が、極めて限定的であることを示唆しています。
検討内容
事前学習のみを終えたllm-jp-13bモデルに対して、llm-jp-eval (jaster)データセットをランダムにN件、学習させ、スコアの推移を評価しました(学習率1e-5*、3 epoch、フルパラメーター)。
学習・評価結果
全体の傾向
訓練データの件数を100-50000で変えた際のスコアの平均は以下のようになりました。
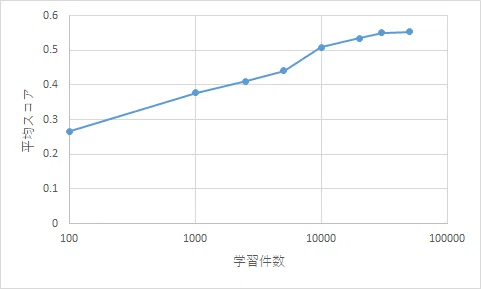
得られた最高スコアは0.55以上で、GPT3.5などを上回ります。
この事実は、10bクラスのモデルであっても、タスク特化をさせれば、商用モデルを上回る性能を発揮可能なことを示しています。
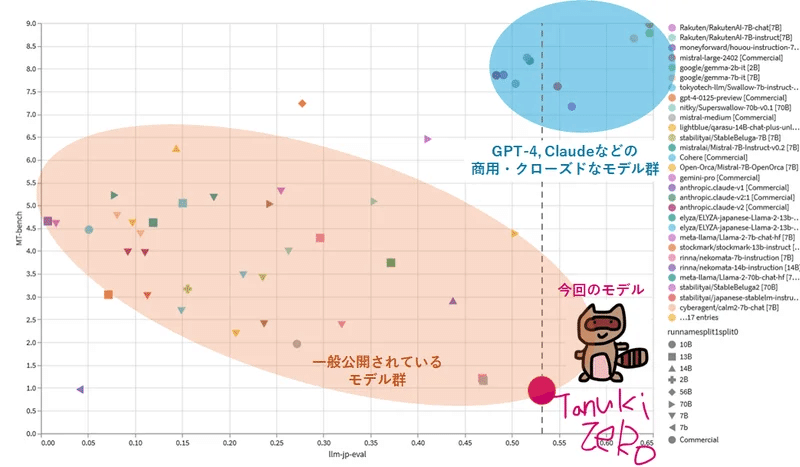
モデルデータはこちら
以下、llm-jp-evalに含まれる個別のベンチマークについて、細かく確認していきます。
JCommonSenseQAを詳しく調べる
評価結果
このベンチマークは、常識問題を選択肢の形で回答するものです。以下のような問題が100問、続きます。

JCommonSenseQAの訓練数*をx軸、当該タスクのスコアをy軸としたグラフは以下のとおりです。この検証では、対照群として、JCommonSenseQAのみを学習させたモデルも構築・評価しました(詳細はこちらの記事を参照)。
*訓練データ全体に含まれるJCommonSenseQAセットの割合をもとに推定した値です。

どちらの条件において、学習データ数が100-200件程度では、スコアが0.2前後にとどまりました*。この値は、本タスクに対するモデルの回答性能が殆どゼロなことを示しています。
*このタスクは5択問題ですので、ランダムに回答した際の平均スコアは0.2程度となります。
学習件数が500を超える頃から、スコアの顕著な上昇が確認され、最終的に0.8程度に収束しました。
データセットとして、JCommonSenseQAのみを学習させた場合(橙)と、llm-jp-evalの訓練データ全体を学習させた場合(青)で、スコアに若干の違いが観測されました。これが有意差なのかどうかについては、細かな検証が必要です。
ここで注意が必要なのは、Dolly, Ichikara, Oasstのような一般的な指示データセットを学習させたのみでは、本モデルは当該タスクを解くことが出来なかったという事実です。選択肢問題に対する回答性能を上げるために実質的に有効だった唯一の手法は、当該データセットを学習させるというアプローチのみでした。

ところで、JCommonSenseQAは知識問題に対する回答能力を問うタスクです。そのため、「訓練データの数」と「問題を解く能力そのもの」の間には、直接的な相関はないはずです。
一連の事項を踏まえると、普通のinstructionデータセット(dollyやoasst)を学習したモデルでllm-jp-13bの予測性能が低かった(score≒0.2)理由は、
b)問題を解く能力(すなわち知識)はあったにもかかわらず、
a)選択肢問題の意図を理解し、c)指定の出力形式で回答する能力がなかったためである、と解釈できそうです。
✕ a)問題の意図を理解する
◯ b)問題を解く
✕ c)指定の出力形式で回答する
そのような観点に立つと、当該データセットで回答訓練を十分に行えなかったモデルにおいては、llm-jp-evalの評価形式では、モデルの知識を問うという、JCommonSenseQAの本来の目的を達成できなかった、と言えるかもしれません*。
*要するに、知識能力以前の問題として、選択肢問題というスキルの有無という「初歩的なポイント」で、モデルが躓いてしまったわけです。
他のモデルの挙動は?
4/3重要な修正
leaderboardにおいて、スコア等をソートした状態でCSV出力をすると、モデル名と評価結果が一致せず、めちゃくちゃになるというバグがあることに気づいたので、結果を一部修正しました。論旨に大きな変化はありません。

本記事ではllm-jp-13b以外の検証は行っていませんが、Nejumi LLMリーダーボードでは様々なモデルのスコアが公開されています。
2024/4/2時点では、50種弱のモデルの評価結果が報告されていました。
JCommonSenseQAのスコアに関するヒストグラムは、以下のとおりです。
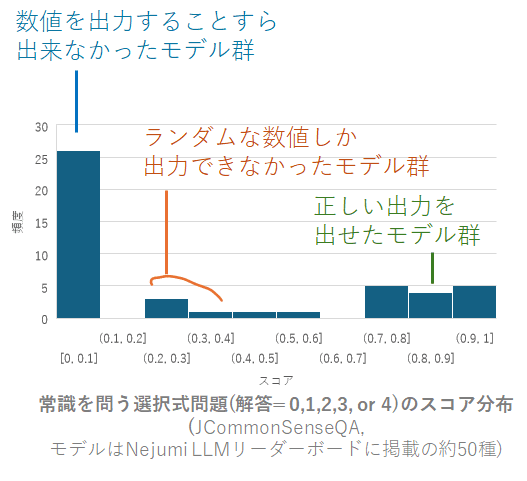
まず目につくのは、半数以上のモデル(>25種)が、ほぼゼロのスコアを示したという点です。これは、選択肢問題において、0-4の数値を出力する能力すら、有していなかったことを示します。*
*例: 数値ではなく単語を答えてしまう、など。
さらに興味深いのは、gpt-4を含む商用モデルですら、jcommonsenseのスコアがゼロになっているケースがあるということです*。
*これは何らかの手違いなんでしょうか?? (gpt-4-0125-previewなどでは、高めの点数がついています)→4/3リーダーボードの出力バグが原因でした。

LLMの実力を評価する上で注意せねばならない点は、
世の中の大半(おそらくは半数以上の)モデルは、選択肢問題をまともに理解して*解くことが出来なそうだ、ということです。
*ここでは、0 shot predictionを指します。
更に興味深いのは、JCommonSenseQAのスコアとモデルサイズ*の間に、明確な相関関係を観測できなかったという点です(下図)。
*パラメータ数が判明しているローカルモデルでの比較です。
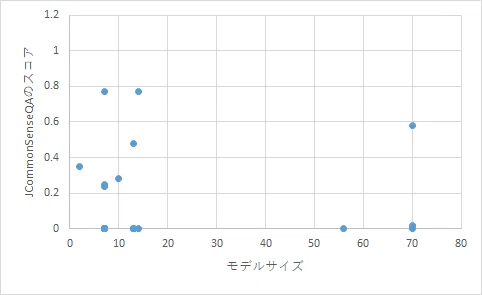
高いスコアを示したモデルは以下のとおりです。
商用モデルは、概ね、回答優れた回答能力を示します。

どういうモデルがJcommonSenseQAを解けるのか?
ローカルLLMにおいては。モデルサイズとJcommonSenseQAのスコアの間には、明確な相関関係がないということがわかりました。であるとすると、スコアに寄与する最大の要因は、おそらく、データセットです。
細かな訓練過程を十分には明示していないモデルが多いので、正確な考察をすることは、困難ですが、一部のモデルでは学習条件が明示されています。
例えばllm-jp-13b-instruct-*-jaster系は、llm-jp-eval系のデータセットでファインチューニングを行ったモデルです。当然(?)ながら、高いスコア(≒0.9)を示しました。
また、weblab-10b-instruction-sftについても、どのような指示データセットを用いたかについての記述がありました。
事後学習(ファインチューニング)には、Alpaca(英語)、Alpaca(日本語訳)、Flan 2021(英語)、Flan CoT(英語)、Flan Dialog(英語)の5つのデータセットを使用しました。
jaster系は学習していない、という点が興味深いです。
一方、詳しくは調査しきれてないのですが、例えばFlan系のデータセットに含まれるCommonsenseQAが5択問題であり、このような選択肢問題での訓練を通して、JCommonSenseQAへの回答能力を獲得したのではないか、という仮説は、一連の結果を踏まえると、合理的であるように筆者は思います。
また、最高スコアを獲得したrakuten系のモデルは、jquadなど、llm-jp-evalに含まれるベンチマークを学習したことがプレプリントで報告されています。
一旦まとめ
大半のLLM(半数以上?)は選択肢問題を解くことができない
選択肢問題への回答能力とモデルサイズの大小は相関しない
選択肢問題の事前対策(訓練)を行ったモデルのみが、解答能力を有している可能性がある
脱線話題
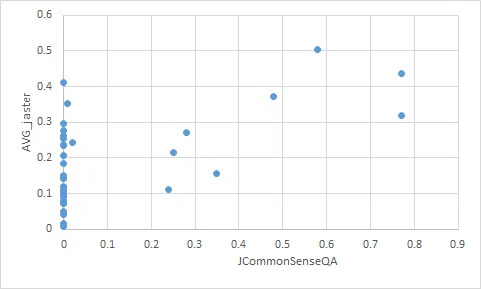
リーダーボードで報告されている一部のモデルでは、JCommonSenseQAとjaster全体のスコアの間に、相関関係がありました。
詳細は分析しきれていませんが、これまで考察してきたモデルの基礎性能を鑑みると、単にjasterに近いデータセットを学習したモデルが、jasterで高スコアを獲得しただけなのかもしれない、という可能性についても、ある程度は考慮する必要がありそうです。
他のベンチマークについて
(llm leaderboardの解析結果が思いのほか、興味深かったので)
かなり脱線してしまいましたが、本記事の趣旨は、「種々のスキル」を身につけるための条件検討でした。llm-jp-evalデータセットには、JCommonSenseQA以外にも、多くのベンチマークタスクが存在します。
それらのスコアと学習件数の関係について、調べていきます。
x軸に、各タスクの訓練データの量*、y軸にスコアをプロットしました。
*JCommonSenseQAのときに説明した通り、換算値です。

(各タスクに関する細かな説明は本記事の最後に記載しています)
全体的な分析
ざっくり、以下のような感じとなりました。
比較的、人間にとっての難易度感と、一致しているように思います。
ただし、
人間が思ったより(?)も多くの訓練(数十~数百以上)が必要
タスク間の汎化性はおそらくなさそう*
な点については、注意が必要です。
*ここでは詳しく検証していませんが、上述のdolly, oasstなどの結果類をもろもろ統合すると、LLMにとって、各タスクはほぼ独立したものであり、タスク間の共通項を見出すことは難しいということが推察されます(つまり、教えていないタスクをこなすことはできない可能性が高いということです)。

ほぼ未学習 0-shotで解けそうなタスク
与えられた文章から単語を抜き出す(jsquad, score=0.8)
クイズへの解答(niilc, score=0.4)
数十程度の訓練で解けるようになってくるタスク
日本語をすべてひらがなに変換(wiki_reading)
クイズへの解答(jemhopqa)
文章の分析と単語(極性)の出力(chabsa)
数百件程度の訓練が必要そうなタスク
文章の分析と単語の出力(jsick系)
かかりうけ解析(wiki_dependency)
選択肢問題への解答(jcommonsense)
文章の類似度比較と数値の出力(jsts)
それ以上のデータが必要 / 学習不能なタスク
文章からの厳密なフレーズ抽出(wiki_coreference)
文章からの固有表現の抽出(wiki_ner)
文章間の整合性の確認(jsem)
文章の述語構造の解析(wiki_pas)
まとめ
以上の結果をまとめると、筆者の見解は以下のとおりとなります。
大半のLLMは、「おバカ」なので、教えていないタスクを解くことは基本的にできない
リーダーボードに掲載されているモデルの半数以上は、「選択肢問題」が与えられていることすら、理解できていない
LLMが異種タスク間の共通項を見出す能力も、極めて限定的である
「単語を答えるクイズ」の訓練をしても、「選択肢を答えるクイズ」に解答できるようにはならない
タスクを解けるようになるためには、意外と多くの訓練が必要である
LLMにとってのタスクの難易度感は、それなりに人間の感覚と一致する
しかし、各タスクごとに、数十ー数百件以上の訓練は必要である
今後にやりたいこと
厳密な解答は求めない、作文系のタスクに対する、LLMの能力評価
より実用的な、ルール遵守系タスクに対する、LLMの能力評価
json出力
カンマ区切り
…
タスク特化型モデルの構築
「おバカ」なLLMを実用で使うための、数少ない選択肢の一つは、きちんとタスク範囲を絞った上で、そのための丁寧なチューニングを行うということだと考えています。
雑多な感想
「万能」と思われるGPT-4系の商用モデルが、果たしてどの程度の訓練を行ったのか、知りたい
かなり大変だった、という噂は聞きますが、果たして、、
一連の能力を、事前学習の段階で自動的に獲得することはできないのか?
どうやら、非常に困難らしいという結果は、(上述の通り)出ている
LLMの能力制約に加えて、そもそも、そういうテキストが殆どない可能性もある
例: 「◯◯なデータをjsonに変換すると、◯◯になりました」というテキストを、webサイトや書籍で見かけることは、殆どない。
とすると、現実的には、頑張って指示データセットを作るしかない?
補足: 各タスクの分析
chabsa
以下のようなタスクです。
与えられた文章から固有表現で書かれたターゲットの名前を抽出し、それに対する極性をpositive、neutral、negativeの中から選択して下さい。固有表現で書かれたターゲットの名前と、それに対する極性(positive、neutral、negativeのいずれか)のペアをスペース( )で区切って出力し、それ以外には何も含めないことを厳守してください。答えが複数の場合、改行で繋げてください。ただし、ターゲットは固有表現である市場、市況、会社/法人、グループ、会社内の部門、事業部、事業領域、製品、サービスの名称などを指すこととします。文章:建設事業受注高は、前連結会計年度と同水準で推移し、前連結会計年度比3.8%減の1兆7,283億円(前連結会計年度は1兆7,958億円)となった建設事業受注高 negative
一般人にとっても意味不明なタスクです。
positive, neutral, negativeの三択問題なので、ベースラインは0.3付近になります。
スコアは訓練データ数のlogに概ね比例して増加しました。
モデルが、タスクの意味を学習しながら、性能を向上させている印象を受けます。
wiki_coreference
与えられたテキストから同一の対象を指し示すフレーズを全て抽出してください。回答は以下のような形式で答えてください。\nフレーズ1 フレーズ2 フレーズ3\nフレーズ4 フレーズ5ギタリストは、ギター演奏者の通称。ギタープレイヤーとも称される。ギタリスト ギター演奏者 通称 ギタープレイヤー\nギター ギター
フレーズを抜き出すタスクです
推論結果を実際に確認すると、「ギター ギター」のような出力は出ていました。
ただし、採点基準が完全一致なこともあり、スコアは一貫して、ほぼ零点でした
タスクそのものが、難し過ぎる可能性があります。
niilc
質問に対する答えを出力してください。答えが複数の場合、コンマ(,)で繋げてください。質問:日本の三大美林とは?青森ヒバ(青森県),秋田スギ(秋田県),木曽ヒノキ(長野県の木曾谷)
クイズですが、複数回答の場合は、カンマ区切りで出力する能力が求められます
訓練を積んでも、あまりスコアが上がりませんでした。
クイズそのものが難しい?ことに加えて、カンマ区切りの出力で躓いている印象です

jemhopqa
質問を入力とし、回答を出力してください。回答の他には何も含めないことを厳守してください。質問:『ダンガンロンパ 希望の学園と絶望の高校生』と『ファイナルファンタジーXIII』、発売日が早いのはどちらでしょう?ファイナルファンタジーXIII
こちらもクイズです。
100件程度の学習によってスコアが0.2 to 0.5程度まで上がりましたが、その後は頭打ちになりました。
採点アルゴリズムを精査出来てませんが、Noとnoの違いなどを、誤答としてしま可能性はあるかもしれません
wiki_reading
与えられたテキストを全てひらがなに変換してください。ギタリストは、ギター演奏者の通称。ギタープレイヤーとも称される。ぎたりすとは、ぎたーえんそうしゃのつうしょう。ぎたーぷれいやーともしょうされる。
ひらがなに変換するタスクです
10ー100件程度のデータを学習させるだけで、スコアが0.8を超えました。
このLLMにとっては、負荷の低いタスクのようです。
jsick, jnli, janli, jamp
前提と仮説の関係をentailment、contradiction、neutralの中から回答してください。それ以外には何も含めないことを厳守してください。\n\n制約:\n- 前提が真であるとき仮説が必ず真になる場合はentailmentと出力\n- 前提が真であるとき仮説が必ず偽になる場合はcontradictionと出力\n- そのいずれでもない場合はneutralと出力前提:戸外で遊んでいる男の子は一人もおらず、微笑んでいる男性は一人もいない\n仮説:子供たちのグループが庭で遊んでいて、後ろの方には年を取った男性が立っている
文法を理解し、neutral, entailment, contradictionを出力するタスクです
類似のタスク(jnli, janli, jamp)が沢山あるので、厳密なことは言えませんが、数十ー数百件程度の学習で、モデルの予測性能が0.8程度に上がるようです
jsquad
質問に対する回答を文章から一言で抽出してください。回答は名詞で答えてください。 それ以外には何も含めないことを厳守してください。文章:梅雨 [SEP] 梅雨(つゆ、ばいう)は、北海道と小笠原諸島を除く日本、朝鮮半島南部、中国の南部から長江流域にかけての沿海部、および台湾など、東アジアの広範囲においてみられる特有の気象現象で、5月から7月にかけて来る曇りや雨の多い期間のこと。雨季の一種である。\n質問:日本で梅雨がないのは北海道とどこか。小笠原諸島
単語を抜き出すタスクです
10-100件程度の学習で、スコアが0.8を超えました。
LLMにとっては、負荷が低めの作業なのかもしれません。
mawps
与えられた計算問題に対する答えを整数または小数で出力してください。数値のみを出力し、それ以外には何も含めないことを厳守してください。問題:大山のバナナコレクションには36本のバナナがあります。バナナを9つのグループに分けると、それぞれのグループの大きさはどのくらいになりますか?4
算数を行うタスクです。
スコアはほぼゼロでした。
学習可能な件数が少なく(~0)、実質的には未学習のzero-shot preditionになってしまっているようです。
計算ミスが目立つことに加え、「数値だけを答える」という指示を守れていないようです。

jsts
日本語の文ペアの意味がどのくらい近いかを判定し、類似度を0.0〜5.0までの間の値で付与してください。0.0に近いほど文ペアの意味が異なり、5.0に近いほど文ペアの意味が似ていることを表しています。整数値のみを返し、それ以外には何も含めないことを厳守してください。文1:レンガの建物の前を、乳母車を押した女性が歩いています。\n文2:厩舎で馬と女性とが寄り添っています。0
文章の類似度を推定するタスクです
1000件程度までは、スコアが学習件数のlogに比例しました
類似度の基準というものを、llmが学習している感じでしょうか。
wiki_ner
与えられたテキストから固有表現(組織名、人名、地名、固有物名、日付表現、時刻表現、金額表現、割合表現)を全て抽出してください。回答には「固有表現1(種類1) 固有表現2(種類2)」のように固有表現の種類も含めてください。オーストラリア・ドル(英語: Australian Dollar)は、オーストラリア連邦で用いられる通貨の名称である。通貨コードはAUDであり、A$、豪ドルなどと称する。なお、オーストラリア領土以外では、ポリネシアのナウル・ツバル・キリバスでも用いられている。オーストラリア(地名) オーストラリア連邦(地名) 豪(地名) オーストラリア(地名) ナウル(地名) ツバル(地名) キリバス(地名)
固有表現を抜き出すタスクです。
完全一致が求められることもあり、このモデルでは100件程度の訓練では、十分な性能を出すことが出来ませんでした
wiki_dependency
与えられたテキストについて文節間の係り受け関係を列挙してください。回答は以下のような形式で答えてください。\n係り元文節1 -> 係り先文節1\n係り元文節2 -> 係り先文節2ギタリストは、ギター演奏者の通称。ギタープレイヤーとも称される。ギタリストは、 -> 通称。\nギター演奏者の -> 通称。\nギタープレイヤーとも -> 称される。
係り受けを解析するタスクです。
10-数百件程度までは、順調にスコアが上昇しています
1000件以上?学習すると、llmが1に近いスコアを出せるかもしれません。
わりと難しいタスクと言えそうです
jsem
前提と仮説の関係をyes、no、unknown、undefの中から回答してください。それ以外には何も含めないことを厳守してください。\n\n制約:\n- 前提が仮説を含意する場合はyesと出力\n- 前提が仮説の否定を含意する場合はnoと出力\n- 前提が仮説を含意せず、その否定も含意しない場合はunknownと出力\n- 与えられた情報のみからは判断ができない場合はundefと出力前提:あっちの学校は校則が厳しいことで有名で、こっちの学校は自由な校風を売りにしている。\n仮説:あっちの学校は校則が厳しいことで有名なので、こっちの学校は自由な校風を売りにしている。unknown
文章の関係性を答えるタスクです
学習件数によらず、スコアが一定でした
基本的には、yesと答えるだけで0.6を超えるスコアが出るようです
1000件以上の訓練を積んでも、このLLMは実質的な解答能力を持たなかった、と判断できそうです

wiki_pas
与えられたテキストから述語項構造を全て抽出してください。回答は以下のような形式で答えてください。\n述語1 ガ:項1 ヲ:項2 ニ:項3\n述語2 ガ:項4 ヲ:項5"ギタリストは、ギター演奏者の通称。ギタープレイヤーとも称される。通称 ガ:ギタリスト\n称される ガ:ギタリスト ト:ギタープレイヤー
文法理解の問題のようです。
筆者には理解不能のタスクでした。
LLMにも理解が難しかったようで、少なくとも数百件程度の学習では、殆どスコアが出ませんでした。
この記事が気に入ったらサポートをしてみませんか?