Gymで強化学習②基本的な枠組み

今記事では強化学習の基本的な枠組みを解説します。
前回はGymnasium(Gym)で強化学習を行う環境を準備しました。
その際に以下の用語が登場しました。
エージェント(agent)
環境(env)
観測値(observation)
行動(action)
報酬(reward)
これらの用語を使って強化学習エージェントがどのように学習を行うのかを議論します。
さっそく始めましょう。
エージェントと環境のやり取り
強化学習ではエージェントが環境から学ぶことで最適な行動を決めれるようになることを目指します。つまり、エージェントは環境に作用し、その結果を環境から観測します。
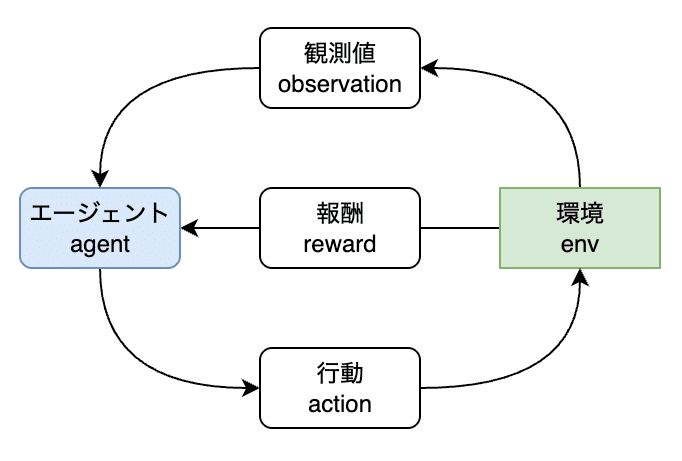
ただし、環境で起きていることをすべて観測できる場合とそうでない場合があります。また、最適な行動とは何かという疑問もわきます。そこでは環境から得られる報酬が関係してきます。
以下では、Gymの環境でも見られた環境の初期化から始めてエージェントと環境の相互作用を通して様々な疑問に答えていきます。
この記事が気に入ったらサポートをしてみませんか?