
PyTorch深層学習⑤データセット編

前回は、PyTorchでテンソルを使う練習をしました。今回は、データセットとデータローダーを扱います。
これらの仕組みを利用することで、画像データなどを簡単に訓練に利用することができます。
本シリーズの記事リスト
⑤データセット編
データセットとは学習などで使うためのデータをまとめてあるものです。画像や文章などいろいろなものがあります。最近では、Huggingfaceなどでたくさんのデータセットが提供されています。
今回は、PyTorchが提供しているコンピュータ・ビジョン系のデータセットであるTorchvision(トーチビジョン)について解説します。
また、データローダーはデータセットからデータをバッチごとに取り出す仕組みです。あとで詳細を解説します。
さっそく始めましょう。
Python環境の設定
Pythonの仮想環境を作ってPyTorchとJupyterなどをインストールします。
mkdir dataset_test
cd dataset_test
python3 -m venv venv
source venv/bin/activate
# pip をアップグレードしておく
pip install --upgrade pip
# 必要なライブラリをインストール
pip install torch torchvision matplotlib jupyterいつものようにJupyterノートブックを立ち上げてPython3のノートブックを作成してください。
MNIST
MNISTは Modified National Institute of Standards and Technology の略です。日本語読みするとエムニストという感じになります。もちろん最後のTは子音なので、英語読みで「ト」のようにはっきりと発音されることはないですが。
手書きの数字がたくさん集められたものです。
データセット
まずは Torchvision からデータセットのライブラリをインポートします。そしてMNISTの訓練用データセットのオブジェクトを作成します。
# Torchvision からデータセットのライブラリをインポート
from torchvision import datasets
# MNISTの訓練用データセットのオブジェクトを作成
training_data = datasets.MNIST(
root = "data",
train = True,
download = True
)train = True と指定することで訓練用のデータセットオブジェクトを作成します。
download = True としているので、初回はデータをダウンロードするため少し時間がかかります。この時、ダウンロードするのは訓練用のデータセットだけでなく、テストようのデータも一緒にダンロードされます。
また、root = "data" と指定しているのは、ダウンロードしたデータの格納場所です。
また、download = True となっていても、root で指定した場所にデータがある場合は、そちらからロードするので毎回ダウンロードすることはありません。
まずは、訓練用データにどれほどの画像があるのかをチェックしましょう。
len(training_data)これが60000と返すので、訓練用の画像は6万個あるのがわかります。
画像データ
次に1番目のデータを取り出してみます。
# 1番目のデータ
training_data[0](<PIL.Image.Image image mode=L size=28x28>, 5) と出力されます。
つまり、一つの画像に対して、数字の画像データとそのラベル(正解の数字)の二つの情報を返しています。よって、(画像データ、ラベル) というようにタプル(Tuple)になっています。
なので、画像とラベルを別々に取り出すには次のように行います。
# 画像とラベルを別々に取り出す
image, label = training_data[0]画像はPIL.Imageの画像オブジェクトであり、そのままJupyterノートブックのセルで実行すると画像が表示されます。
画像を表示
image
PIL .Imageオブジェクトから画像のサイズを取り出します。
image.size(28, 28) と返されるので画像のサイズが 28x28 ピクセルであることがわかります。
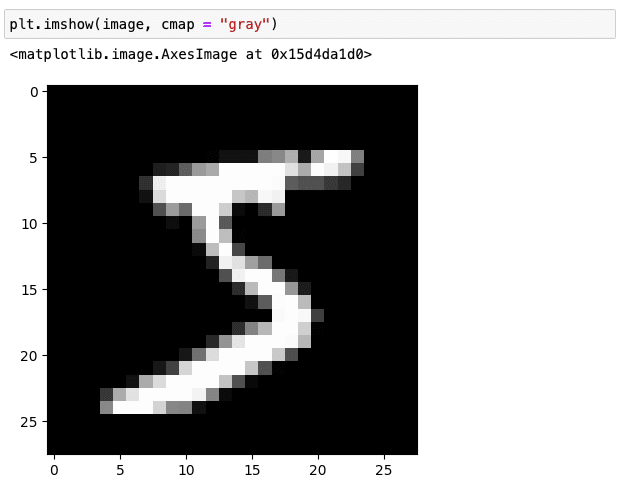
PIL.Imageオブジェクトを次のように matplotlib で表示することもできます。
plt.imshow(image, cmap = "gray")カラー画像ではないので、配色(cmap = color map)としてグレースケール(gray)を指定しています。
NumPyに変換
また、PIL.ImageオブジェクトをNumPyに変換することができます。
image_np = np.array(image)NumPyの機能を使って幾つかの情報を取り出してみましょう。
print("Image Shape:", image_np.shape)
print("Data Type :", image_np.dtype)
print("Min and max:", image_np.min(), image_np.max())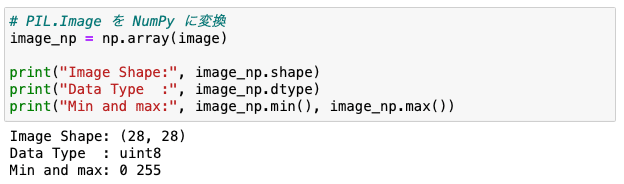
uint8 は8ビットの符号なし整数型です。つまり、負の値を取らないので値の範囲は最小0から最大255になります。よって266個の値を使って色の濃さ(
強度)を表現していることになります。
強度を見るには次のようにピクセルの位置を指定します。
image_np[6, 10]ここでは、縦横の順で7行目11列にあるピクセルを指定しました。

テンソルの解説を思い出した方もいると思いますが、これは2次元テンソルです。
Tensorに変換
NumPyは次のようにPyTorchのTensorへと変換できます。
image_tensor = torch.from_numpy(image_np)
matplotlib では Tensor をそのまま表示することができます。
plt.imshow(image_tensor, cmap = "gray")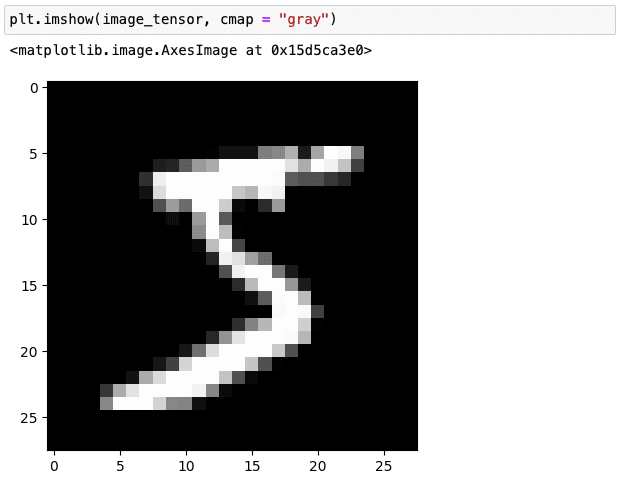
注意点としては、Tensor が CPU にあることが条件です。今のところGPUについては話していないので扱っているTensorは全てCPU上で処理されており問題ありません。
トランスフォーム
画像データを一つ一つTensorに変換するのも面倒です。データセットのオブジェクトを作る際に、初めからTensorとして扱えた方が便利でしょう。
幸い Torchvision には transforms があり、それを使うことでデータをあらかじめTensorへと変換しておくことができます。
# トランスフォームをインポート
from torchvision import transforms
# MNIST の訓練用データセットのオブジェクトを作成
training_data = datasets.MNIST(
root = "data",
train = True,
download = True,
transform = transforms.ToTensor() # Tensorに変換
)前回との違いは、transform = transforms.ToTensor() とTensorに変換するために呼び出し可能なオブジェクトを指定していることです。このオブジェクトはファンクションのように呼び出すことが可能になっており、データセット内のデータをTensorに変換するために使われます。
では1番目の画像とラベルを取り出します。
# 1番目の画像とラベル
image, label = training_data[0]
print("Image Type :", type(image))
print("Image Shape:", image.shape)
print("Data Type :", image.dtype)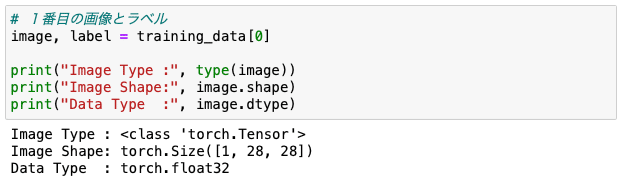
画像のデータタイプがTensorになっているのがわかります。また、画像データはチャンネル・ファーストの3次元テンソルになっています。
MNISTの場合はチャンネルは一つしかありませんが、それでもチャンネルがあるのはディープラーニングで画像を取り扱う際に(特に畳み込みなどでは)チャンネルが必要となります。これについては後々に解説します。
なお、3次元テンソルについては、以前の記事で詳しく解説してあります。
もう一つ重要な点は、データ型が float32 (32ビットの浮動小数点型)になっていることです。PyTorchではデフォルトで float32 を取り扱います。自分でNumPyのデータをTensorに変換するときは注意が必要です。NumPyではデフォルトで float64 を扱いからです。
また、Tensorのデータ型については、こちらの記事で解説しています。
もともとは uint8 のデータ型だったものを float32 のデータ型にしていることになります。色の強度が0から255の整数だったものが、0から1の浮動小数点型に変換されています。
image[0, 6, 10]
単純に、整数型の値を255で割っただけです。以前に取り出したNumPyのデータを使うとそのことが証明できます。
image_np[6, 10]/255
PyTorchが浮動小数点型を使うのは、勾配の値が大きくてばらつきがあると学習する際に効率が悪くなるからです。勾配についても後々に解説します。今は、そういうものだと思っておいてください。
ちなみに、matplotlibはチャンネル・ラストの形式を期待するので、このままだと表示できません。解決策は二つあります。
一つ目の方法はチャンネルの次元を次のように最後に移動させることです。
image.permute(1, 2, 0).shape
次元が0、1、2となっていたものを1、2、0と組み替えました。よって次のように表示が可能です。
plt.imshow(image.permute(1, 2, 0), cmap='gray')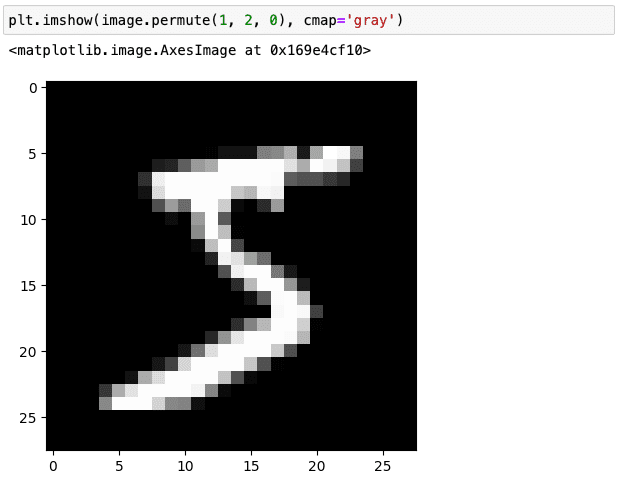
もう一つの方法では、チャンネルの次元を取り除きます。次のように squeeze を呼び出すと無駄な次元がなくなります。
image.squeeze().shape
よって次のように表示することが可能です。
plt.imshow(image.squeeze(), cmap='gray')
テストデータ
テストデータでも扱いは基本的に同じですが、データセットのオブジェクトを作成する際に train = False と指定する必要があります。
test_data = datasets.MNIST(
root = "data",
train = False,
download = True,
transform = transforms.ToTensor()
)download = True としてありますが、先ほどダウンロード済みなので data フォルダからロードします。
len(test_data)
テスト画像は1万個あるのがわかります。
最初の画像とラベルを見てみます。
# 最初の画像とラベル
image, label = test_data[0]
print("Type of Image Object:", type(image))
print("Image Shape:", image.shape)
print("Image Label:", label)
画像を表示します。
plt.imshow(image.squeeze(), cmap='gray')
以上のように、テスト用の画像と訓練用の画像と扱い方は全く同じです。
ファッションMNIST
データセット
ファッションMNIST(Fashion-MNIST)は、Zalando の画像データセットで、6万画像の訓練セットと 1万画像のテストセットで構成されています。
データセットオブジェクトの作り方はMNISTと同様です。
# 訓練セット
training_data = datasets.FashionMNIST(
root = "data",
train = True,
download = True,
transform = transforms.ToTensor()
)
# テストセット
test_data = datasets.FashionMNIST(
root = "data",
train = False,
download = True,
transform = transforms.ToTensor()
)次のようにデータセットの情報を表示することができます。
training_data
画像データ
最初の画像データの詳細も見ていきましょう。
image, label = training_data[0]
print("Type of Image Object:", type(image))
print("Image Shape:", image.shape)
print("Image Label:", label)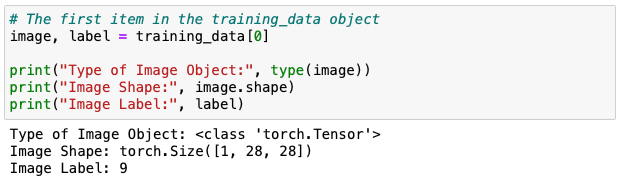
チャンネルが1つになっています。matplotlib で表示してみます。
plt.imshow(image.squeeze(), cmap='gray')
ラベルの値
ラベルの値の意味は次のようになっています。
fashion_mnist_labels_map = {
0: "T-Shirt",
1: "Trouser",
2: "Pullover",
3: "Dress",
4: "Coat",
5: "Sandal",
6: "Shirt",
7: "Sneaker",
8: "Bag",
9: "Ankle Boot",
}CIFAR 10
データセット
CIFAR-10 データセットは、5万画像の訓練セットと 1万画像のテストセットで構成されています。
training_data = datasets.CIFAR10(
root = "data",
train = True,
download = True,
transform = transforms.ToTensor()
)
test_data = datasets.CIFAR10(
root = "data",
train = False,
download = True,
transform = transforms.ToTensor()データの数を確認します。
print("Training Data:", len(training_data))
print("Test Data :", len(test_data))
画像データ
最初の画像の詳細を見てみます。
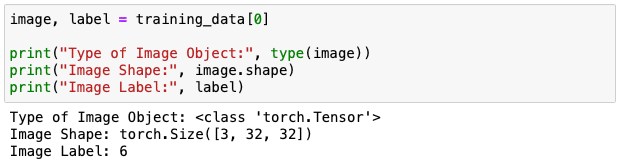
CIFAR 10には3チャンネルあります。
matplotlibで表示するには、チャンネル・ファーストをチャンネル・ラストに変換する必要があります。
# (チャンネル、行、列) から (行、列、チャンネル)
image.permute(1, 2, 0).shape
matplotlibで表示します。
plt.imshow(image.permute(1, 2, 0))
ラベルの値
CIFAR 10には10のクラスがあります。
cifar10_labels_map = {
0: 'plane',
1: 'car',
2: 'bird',
3: 'cat',
4: 'deer',
5: 'dog',
6: 'frog',
7: 'horse',
8: 'ship',
9: 'truck'
}いくつかの画像を表示してみます。
figure = plt.figure(figsize=(8, 5))
cols, rows = 6, 3
for i in range(1, cols * rows + 1):
image_idx = i - 1
img, label = training_data[image_idx]
figure.add_subplot(rows, cols, i)
plt.title(cifar10_labels_map[label])
plt.axis("off")
plt.imshow(img.permute(1, 2, 0))
plt.show()
Data Loader
最後にデータローダーを紹介します。データローダーの主な目的は、データセットから画像とラベルのバッチ(複数の画像をまとめたもの)を作ることです。このバッチを利用してモデルの訓練をしたり、評価を行ったりします。
データローダー
from torch.utils.data import DataLoader
# 乱数のシードを固定
torch.manual_seed(123)
# データローダーを作成
train_dataloader = DataLoader(training_data, batch_size=16, shuffle=True)from torch.utils.data import DataLoader でデータローダーのクラスをインポートします。
torch.manual_seed(123) としているのは乱数のシードを固定しているからです。これはTensor編で解説しました。
train_dataloader = DataLoader(train_data, batch_size=16, shuffle=True) でデータローダーを作成しています。
train_dataはCIFAR 10のセクションで生成したデータセットオブジェクトです。
batch_sizeでバッチに含める画像とラベルの数を指定します。
shuffle=Trueは、データがシャッフルされます。画像の順番がランダムに変わります。乱数のシードを固定しているのでランダムな順番が毎回同じになります。
バッチを取り出す
最初のバッチを取り出してみます。
# 最初のバッチ
images, labels = next(iter(train_dataloader))
print(f"Image batch shape: {images.size()}")
print(f"Label batch shape: {labels.size()}")データローダーはイテラブル(iterable)なので iter でイテレータにすることができます。よって、next で最初の(次の)要素を取り出せます。

4次元のテンソルになっているのが分かります。最初の次元がバッチ中のインデックスになっており、バッチサイズ通り16の画像(ラベル)があるのが分かります。つまり、画像のバッチには16個の画像が3次元テンソルとして収納されています。
テンソルの概念はこちら記事で解説しています。
バッチの中身
バッチからの最初の画像のShapeをチェックします。
images[0].shape
これは予想通りで、特に問題はないですね。
ラベルを見てみましょう。
labels
16個の画像に対する16個のラベルがあります。
最初のラベルを見ると、テンソルであるのが分かります。
labels[0]
ちなみにデータ型は int64 (64ビットの整数型)です。
labels[0].dtype
Tensorからスカラー(ただの数値)に変換するには .item() を呼び出します。
labels[0].item()
最初の画像とラベル名を表示します。
# 最初の画像とラベル名を表示
image = images[0].permute(1, 2, 0)
label = labels[0].item()
plt.imshow(image)
plt.title(cifar10_labels_map[label])
plt.show()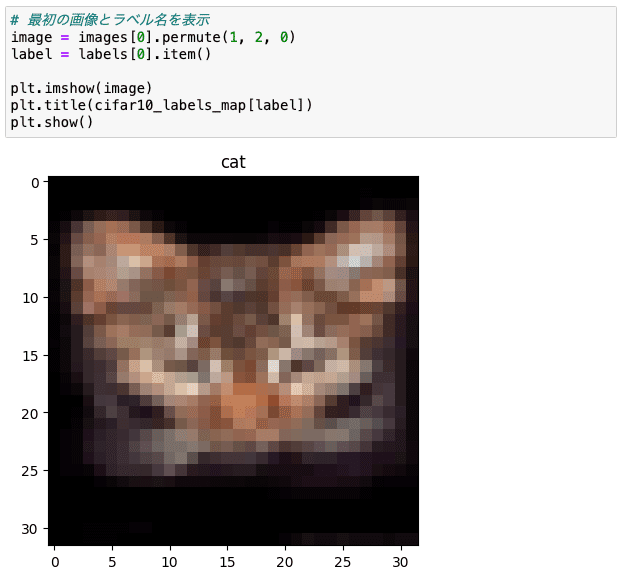
画像が小さいので拡大してみるとなんだかよくわからないですね。
ループを使う
データローダーはイテラブルなので for ループで使うことができます。
from torchvision.utils import make_grid
for images, labels in train_dataloader:
image_grid = make_grid(images, ncol=8) # 画像グリッド生成
image_grid = image_grid.permute(1, 2, 0) # チャンネル・ラスト
plt.figure(figsize=(8, 4))
plt.imshow(image_grid)
plt.xticks([])
plt.yticks([])
plt.show()
print("Labels:", labels)
break # 最初のバッチを表示したらループから脱出
データローダーは非常に重宝なのでよく出くはずです。
次回は、いよいよ機械学習を行います。線形回帰をPyTorchのモジュールを使って実装してみます。
(以上)
この記事が気に入ったらサポートをしてみませんか?