
Pythonでやってみた(画像処理編4):モザイク処理

1.概要
画像や動画を公開する時に見せたくない部分にモザイク処理をかけることがあると思います。
Pythonを用いていろいろなモザイク処理ができるようにしてみました。サンプル画像はいつもの"konan.JPG"を使用します。

なお紹介用として画像を対比させる関数を事前に作成しました。ポイントとしてplt.imshow(img)で表示しているためデータ型はPIL形式でもNumpy形式でも問題ございません。
[IN]
from PIL import Image
import matplotlib.pyplot as plt
import japanize_matplotlib
path_imgfile = 'konan.JPG'
img = Image.open(path_imgfile) #PIL形式で開く
#オリジナル画像と加工画像を並べて表示
def contimages(img_proc, title: str):
fig = plt.figure(figsize=(10,6))
plt.rcParams["font.size"] = 14 #フォントサイズを設定
for idx in range(2):
if idx == 0:
ax = fig.add_subplot(1,2,1) #1行2列の1番目のグラフ
ax.imshow(img) #オリジナル画像
ax.set_title('オリジナル画像', y=-0.10)
else:
ax = fig.add_subplot(1,2,2) #1行2列のグラフを作成
ax.imshow(img_proc) #処理後画像
ax.set_title(f'処理画像({title})', y=-0.10) #タイトルを下に設定
plt.axis('off') #軸を消す
plt.show()
contimages(img, '処理した画像をこちらに表示')
[OUT]
2.Pillowで作成
画像処理ライブラリのPillowを使用して自作のライブラリを作成します。
2-1.ぼかし処理(縮小ー>拡大):全体処理
画像のぼかし処理は「画像を一度圧縮」->「画像を再度拡大」することで実施します。
[IN]
#ぼかし処理(縮小->拡大)
def imageblur(img, reso: float):
width, height = img.size #imgのオリジナルサイズ(幅・寸法を記憶)
img_resize = img.resize((int(img.width/reso), int(img.height /reso))) #縮小
img_blur = img_resize.resize((width, height)) #オリジナルサイズの戻す
return img_blur
img_blur = imageblur(img, reso=5)
contimages(img_blur, title='ぼかし処理5倍') #画像を表示
img_blur = imageblur(img, reso=10)
contimages(img_blur, title='ぼかし処理10倍') #画像を表示
[OUT]

2-2.ぼかし処理2:トリミング×部分処理
上記は全体ですが部分的に処理したい場合は下記手順で処理できます。
画像の切取り(トリミング):Numpy配列でスライスを使用
切取り画像に処理:Numpy->PIL形式に戻して前節の関数を使用
処理後の画像をオリジナルに被せる
まずはトリミング関数(coordinate_xywh)を作成します。感覚的に切取りできるよう起点の座標および切取り幅・高さはすべてオリジナル画像からの相対値としました。
[IN]
import numpy as np
path_imgfile = 'konan.JPG'
img = Image.open(path_imgfile) #PIL形式で開く
img_array = np.array(img)
print(img.size) #画像サイズ(PIL形式):(484, 648)->(幅, 高さ)
print(img_array.shape) #画像のサイズ(numpy):(648, 484, 3)->(高さ, 幅, RGB)
#トリミングするエリアを選択
def coordinate_xywh(img, x:float, y:float, w:float, h:float):
width, height = img.size #画像の幅と高さ
x = int(x * width) #x座標を指定した場合
y = int(y * height) #y座標を指定した場合
w = int(w * width) #幅を指定した場合
h = int(h * width) #幅を指定した場合
return x, y, w, h
(x, y, w, h) = coordinate_xywh(img, x=0.3, y=0.3, w=0.5, h=0.5) #トリミングするエリアを選択
print('x:', x, 'y:', y, 'w:', w, 'h:', h)
img_trim = img_array[y:y+h, x:x+w, :] #画像の部分を取得
plt.imshow(img)
plt.imshow(img_trim)
[OUT]
(484, 648)
(648, 484, 3)
x: 145 y: 194 w: 242 h: 242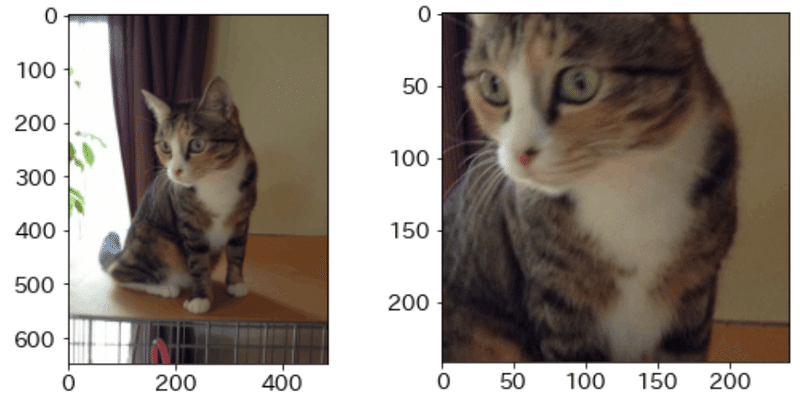
トリミングできましたのでそれでは実際に処理をかけてみます。先ほどとは異なり抽出された部分だけにぼかしがかかっていることが確認できました。
[IN]
import numpy as np
#トリミングするエリアを選択
def coordinate_xywh(img, x:float, y:float, w:float, h:float):
width, height = img.size #画像の幅と高さ
x = int(x * width) #x座標を指定した場合
y = int(y * height) #y座標を指定した場合
w = int(w * width) #幅を指定した場合
h = int(h * width) #幅を指定した場合
return x, y, w, h
path_imgfile = 'konan.JPG'
img = Image.open(path_imgfile) #PIL形式で開く
img_array = np.array(img) #PIL形式->Numpyに変換
(x, y, w, h) = coordinate_xywh(img, x=0.3, y=0.3, w=0.5, h=0.5) #トリミングするエリアを選択
# print('x:', x, 'y:', y, 'w:', w, 'h:', h)
img_trim = img_array[y:y+h, x:x+w, :] #画像の部分を取得
_img_trim = Image.fromarray(img_trim) #Numpy->PIL形式に変換
img_blur = imageblur(_img_trim, reso=10) #ぼかし処理10倍
img_array[y:y+h, x:x+w, :] = np.array(img_blur) #ぼかし処理後の画像を元の画像に代入
contimages(img_array, title='トリミング×ぼかし処理10倍') #画像を表示
[OUT]
3.OpenCVで作成
OpenCVでぼかしやモザイクを入れていきます。なおOpenCVで必要な前処理(BGR->RGBへ変換)などの詳細は記事をご確認ください。
3-1.トリミング:Numpyでスライス
Pillowの紹介で作成したトリミング関数をNumpy形式用に修正したうえで簡単に切取りできる関数を作成しました。
[IN]
import cv2
imgfile = "konan.jpg" #画像ファイルパス
img_bgr = cv2.imread(imgfile)
img_rgb = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB) #BGRをRGBに変換
def coordarray_xywh(img_array, x:float, y:float, w:float, h:float):
height, width, _ = img_array.shape #画像の幅と高さ
x = int(x * width) #x座標を指定した場合
y = int(y * height) #y座標を指定した場合
w = int(w * width) #幅を指定した場合
h = int(h * width) #幅を指定した場合
return x, y, w, h
def trim_imgarray(img_array, x:float, y:float, w:float, h:float):
return img_array[y:y+h, x:x+w, :] #画像の部分を取得
x,y,w,h = coordarray_xywh(img_rgb, x=0.3, y=0.3, w=0.5, h=0.5) #トリミングするエリアを選択
img_trim = trim_imgarray(img_rgb, x, y, w, h) #画像の部分を取得
plt.imshow(img_trim) #画像を表示
[OUT]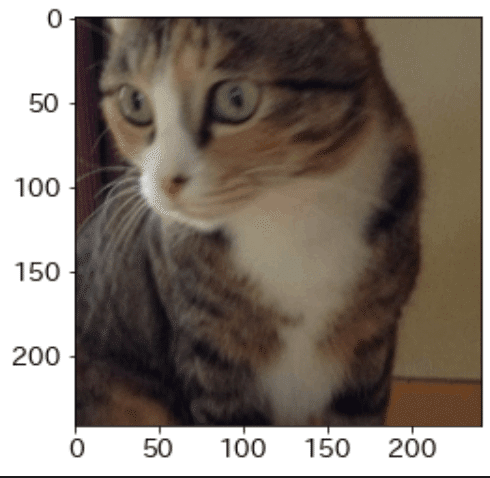
3-2.ぼかし処理1:cv2.blur
OpenCVのぼかし処理としてcv2.blurがあります。
[IN]
import cv2
imgfile = "konan.jpg" #画像ファイルパス
img_bgr = cv2.imread(imgfile)
img_rgb = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB) #BGRをRGBに変換
img_blurcv2 = cv2.blur(img_rgb, (10,10)) #ぼかし処理 (幅, 高さ)
contimages(img_blurcv2, title='cv2.blur(10,10)') #画像を表示
img_blurcv2 = cv2.blur(img_rgb, (20,20)) #ぼかし処理 (幅, 高さ)
contimages(img_blurcv2, title='cv2.blur(20,20)') #画像を表示
[OUT]

3-3.ぼかし処理2:cv2.GaussianBlur()
別の処理としてガウシアンフィルター:cv2.GaussianBlurがあります。
[IN]
import cv2
imgfile = "konan.jpg" #画像ファイルパス
img_bgr = cv2.imread(imgfile)
img_rgb = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB) #BGRをRGBに変換
img_blurcv2 = cv2.GaussianBlur(img_rgb, (15,15), 0) #ガウジアンフィルタ (幅, 高さ, 標準偏差)
contimages(img_blurcv2, title='cv2.GaussianBlur(im, (15,15), 0)') #画像を表示
img_blurcv2 = cv2.GaussianBlur(img_rgb, (35,35), 0) #ガウジアンフィルタ (幅, 高さ, 標準偏差)
contimages(img_blurcv2, title='cv2.GaussianBlur(im, (35,35), 0)') #画像を表示
[OUT]

3-4.モザイク(リサイズ):cv2.resize()
画像を縮小後に拡大して元のサイズに戻すと画像のピクセル値が平均化されるためモザイク処理になります。
[IN]
import cv2
imgfile = "konan.jpg" #画像ファイルパス
img_bgr = cv2.imread(imgfile)
img_rgb = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB) #BGRをRGBに変換
h, w, _ = img_rgb.shape
ratio = 20 #縮小率
# モザイク処理:縮小ー>拡大
img_small = cv2.resize(img_rgb, (int(w/ratio), int(h/ratio))) #sizeと同じ値に画像を縮小
img_mos = cv2.resize(img_small, (w, h), interpolation=cv2.INTER_AREA) #元のサイズに拡大
contimages(img_mos, title='cv2.resizeで20倍変換') #画像を表示
[OUT]
※上記だとratio=20のみ出力されます。10はratio=10に変更して出力

こちらをトリムした位置に置換した画像を出力させるmosaic関数は下記の通りです。
[IN]
import cv2
def mosaic(img, x, y, w, h, size):
# モザイクをかける領域を取得
(x1, y1, x2, y2) = (x, y, x+w, y+h) #モザイク処理をかける領域を指定
img_rec = img[y1:y2, x1:x2] #スライスでモザイク処理をかける領域を取得
# モザイク処理:縮小ー>拡大
img_small = cv2.resize(img_rec, (size, size)) #sizeと同じ値に画像を縮小
img_mos = cv2.resize(img_small, (w, h), interpolation=cv2.INTER_AREA) #元のサイズに拡大
# 画像にモザイク画像を重ねる
img_out = img.copy()
img_out[y1:y2, x1:x2] = img_mos #スライス機能で値を上書き
return img_out
imgfile = "konan.jpg" #画像ファイルパス
img_bgr = cv2.imread(imgfile)
img_rgb = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB) #BGRをRGBに変換
x,y,w,h = coordarray_xywh(img_rgb, x=0.3, y=0.3, w=0.5, h=0.5) #トリミングするエリアを選択
img_mos = mosaic(img_rgb, x, y, w, h, size=10)
contimages(img_mos, title='cv2.resizeで10倍変換') #画像を表示
[OUT]
4.別途追記予定
多角形のモザイク+マスク
参考資料
あとがき
とりあえず先出し。
画像認識+物体抽出+モザイク処理で一つ作りたいのがあるけど、もう少しでいけるかも・・・・・
この記事が気に入ったらサポートをしてみませんか?