
Pythonでやってみた(画像処理編3):物体検出(ultralytics/YOLOv8)

1.概要
以前の記事でYOLOv3、YOLOV5による物体検出をしました。
今回は2023年1月にUltralytics社からリリースされた最新モデルのYOLOv8を実装してみました。
2.YOLOの比較
2-1.YOLOの歴史
YOLO(You Only Look Once、一度だけ見る)は、ワシントン大学のJoseph RedmonとAli Farhadiによって開発された、流行のオブジェクト検出および画像セグメンテーションモデルです。
YOLOv3まではJoseph Redmonが関与していたが、YOLOv4以降では独自の形で進化しております。
YOLO
発表:2016年5月、著者:Joseph Redmon
YOLOv2:バッチ正規化、アンカーボックス、次元クラスタリングを導入し、オリジナルモデルを改善
発表:2017年12月、著者:Joseph Redmon(v1の著者)
YOLOv3:より効率的なバックボーンネットワーク、複数のアンカー、空間ピラミッドプーリングを使用し、モデルの性能を一段と向上させた
発表:2018年4月、著者:Joseph Redmon(v1の著者), Ali Farhadi
YOLOv4:モザイクデータオーギュメンテーション、新しいアンカーフリー検出ヘッド、新しい損失関数などの革新を導入
発表:2020年4月、著者:Alexey Bochkovskiy
YOLOv5:モデルの性能をさらに向上させ、ハイパーパラメータ最適化、統合実験トラッキング、一般的なエクスポート形式への自動エクスポートなどの新機能を追加
発表:2020年6月9日、著者:Glenn Jocher(Ultralytics社)
発表:2021年6月、著者:Alexey Bochkovskiy
発表:2021年5月、著者:Chien-Yao Wang
発表:2021年7月、著者:Zheng Ge
YOLOv6:Meituanによってオープンソース化され、同社の多くの自動配送ロボットで使用
発表:2022年6月、著者:Meituan Technical Team
YOLOv7:COCOキーポイントデータセット上のポーズ推定などの追加タスクを追加
発表:2022年7月、著者:Alexey Bochkovskiy(v4の著者)
YOLOv8:UltralyticsによるYOLOの最新版
発表:2023年1月、著者:Ultralytics社
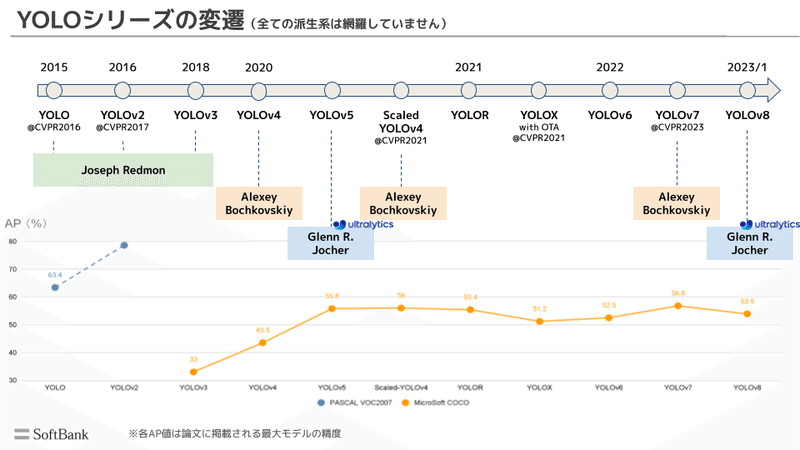
2-2.YOLOv8モデルの特徴
YOLOv8は前モデルより少ないパラメータで高性能が出ており、効率が良くなっていると判断できます。各問題(物体検出、セグメンテーション、姿勢推定、分類)におけるモデルのパラメータや性能は下図の通りです。
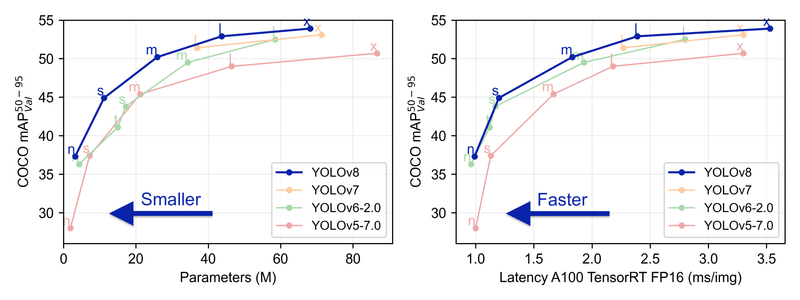

下記記事によるとYOLOv5とYOLOv8の相違点は「C2f layerの導入」と「Decoupled head導入とobjectness branchの削除」とのことです。
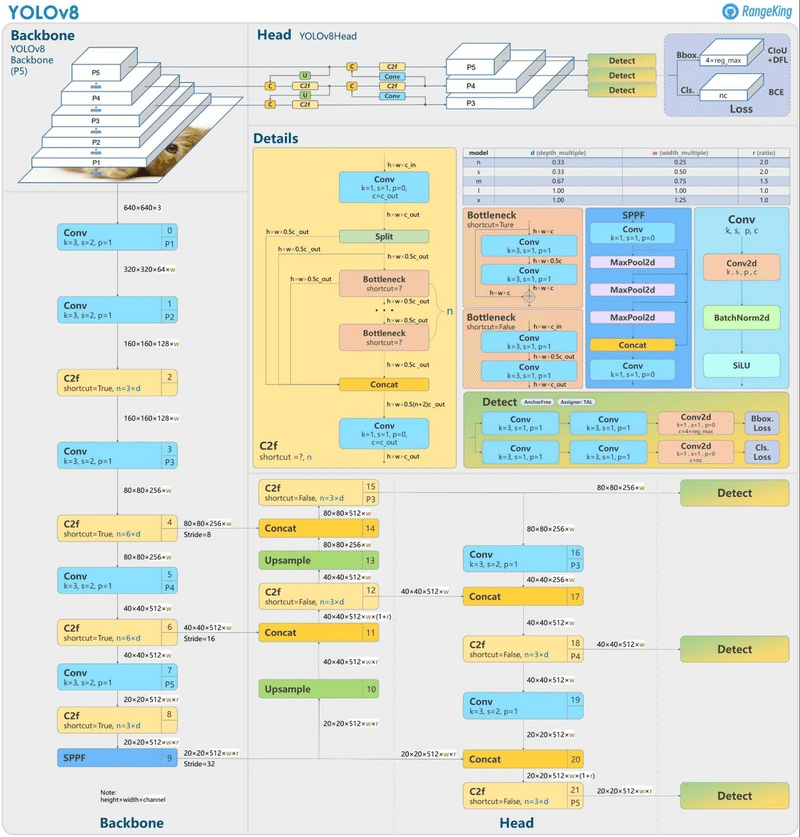
2-3.YOLOv8でできること
Ultralytics YOLOv8は複数のコンピュータービジョンタスクをサポートするAIフレームワークであり検出、セグメンテーション、分類、及びポーズ推定を実行するために使用できます。

またultralyticsでは、単純な物体検出の推論だけでなく複数のことが対応できます。
トレーニングモード:カスタムデータセットでYOLOv8モデルのトレーニングを行うために使用
バリデーションモード:学習済みYOLOv8モデルを検証
予測モード:実世界のデータでモデルの予測能力を発揮
エクスポートモード:様々な形式でデプロイ準備ができたモデルを作成
トラッキングモード:オブジェクト検出モデルをリアルタイム追跡アプリケーションに拡張
ベンチマーキングモード:様々なデプロイメント環境でモデルの速度と精度を分析
ultralystic社は下記の会社と協力してデータセットのラベリング、学習、可視化、モデル管理を提供するAIプラットフォームの統合が強みと紹介されています。

3.YOLOv8の環境構築
YOLOv8を実装するための環境構築します。方法は2パターンあります。
ultralytics pipパッケージ:最新の安定版リリース
Ultralytics GitHubリポジトリをクローン:最新バージョンを取得
基本的には仮想環境を作成して、そこで環境構築することを推奨します。推奨環境は「Python>=3.8 environment with PyTorch>=1.8.」です。
なお前提としてGPUを使用する方はCUDA設定は完了済みとします。
3-1.ライブラリのインストール(安定版)
最新の安定版リリースを利用する場合は、ultralytics pipパッケージを通じてYOLOv8をインストールします。
[Terminal]
pip install ultralytics3-2.リポジトリをクローン(最新版)
最新版を入手する場合は下記の通りです。
ultralyticsリポジトリをクローン
ディレクトリに移動
pipを使って編集可能モード-eでパッケージをインストール
[Terminal]
# ultralyticsリポジトリをクローン
git clone https://github.com/ultralytics/ultralytics
# クローンしたディレクトリに移動
cd ultralytics
# 開発用に編集可能モードでパッケージをインストール
pip install -e .
【参考:Gitのインストール】
Gitのインストールは下記記事に記載しております。
4.クイックスタート
公式Docsを参照しながら、まずはサクッと物体検出を実行してみます。
4-1.CLIで実行:yolo predict
4-1-1.静止画
CLI(Command Line Interface)でYOLOv8を直接実行するためのコマンドは下記の通りです。
[API]
yolo predict model=<YOLOv8の重み.pt> source=<画像ファイルのpath>【Case1:公式通り(物体検出)】
3-2節の通りレポジトリ(ultralytics)のクローン+ディレクトリへ移動して、公式Docsの通り下記を実行します。結果として"runs\detect\predict"フォルダ内に物体検出された画像が作成されました。
[Terminal]
yolo predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg'

【Case2:自分の画像を使用(物体検出)】
作業ディレクトリ内に好きな画像を保存し、sourceを画像のパスに変更しました。オリジナル画像でも同様に処理できます。
[Terminal]
yolo predict model=yolov8n.pt source='konan.jpg'

4-1-2.Youtube動画で処理
sourceにYoutubeのショートカットリンクを指定すればYoutube動画の物体検出も可能となります。
『千鳥・ノブがSKE48須田亜香里にNG発言連発!? 千鳥MC『チャンスの時間 # 129』』を使用し、公式Docsに基づきイメージサイズ320の学習済みsegmentation model(セグメンテーション)を適用しました。
[Terminal]
yolo predict model=yolov8n-seg.pt source='https://youtu.be/Yx1CqlmLJSs?si=qrSLRnZD54Wn9nqV' imgsz=320結果としてピクセル単位の物体検出が正常に実行されました。

4-2.Pythonで実行
CLIだけでなくPython(モジュール、Jupyter)でも利用可能です。今回は利用しやすいJupyter形式で実装しました。
4-2-1.画像処理
今回はクローンしたレポジトリ(ultralytics)内にipynbファイルを配置して、下記を実行しました。初回実行のためGitHubから重みと画像のダウンロードを実行しています。
結果としてCLIと同様に物体検出された画像を取得できました。
[IN]
from ultralytics import YOLO
model: YOLO = YOLO(model="yolov8n.pt") #Modelの選択※yolov8n.pt
result: list = model.predict("https://ultralytics.com/images/bus.jpg", save=True) #推論[OUT]
Downloading https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n.pt to 'yolov8n.pt'...
100%|██████████| 6.23M/6.23M [00:00<00:00, 10.1MB/s]
Downloading https://ultralytics.com/images/bus.jpg to 'bus.jpg'...
100%|██████████| 476k/476k [00:00<00:00, 10.6MB/s]
image 1/1 c:\Users\KIYO\Desktop\ultralytics\bus.jpg: 640x480 4 persons, 1 bus, 1 stop sign, 85.0ms
Speed: 2.0ms preprocess, 60.0ms inference, 1.0ms postprocess per image at shape (1, 3, 640, 480)
Results saved to runs\detect\predict3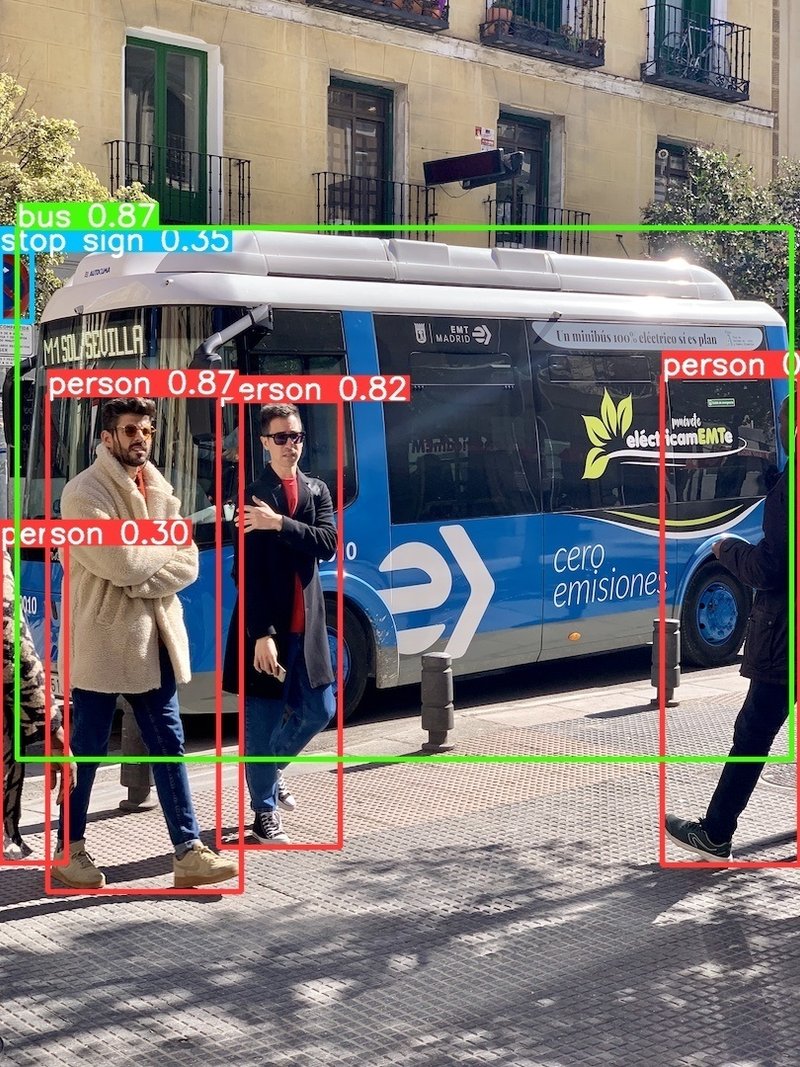
4-2-2.動画処理
次に動画を処理してみます。動画は「動画AC」、「Pexels」、「Pixabay」から素材を集めました。
動画の処理方法は静止画と同じでありパスを変更するだけです。私のPCにおいて、処理時間は下記の通りでした。
約3sの動画:約1min
約13sの動画:約3min
約23sの動画:約6min(5min48s)
[IN]
from ultralytics import YOLO
model: YOLO = YOLO(model="yolov8x.pt") #Modelの選択※yolov8x.pt
result: list = model.predict("movie/32210_640x360.mp4", save=True)[OUT]
WARNING ⚠️ inference results will accumulate in RAM unless `stream=True` is passed, causing potential out-of-memory
errors for large sources or long-running streams and videos. See https://docs.ultralytics.com/modes/predict/ for help.
Example:
results = model(source=..., stream=True) # generator of Results objects
for r in results:
boxes = r.boxes # Boxes object for bbox outputs
masks = r.masks # Masks object for segment masks outputs
probs = r.probs # Class probabilities for classification outputs
video 1/1 (1/113) c:\Users\KIYO\Desktop\ultralytics\movie\32210_640x360.mp4: 384x640 7 persons, 7 cars, 1 bus, 1 tv, 524.0ms
video 1/1 (2/113) c:\Users\KIYO\Desktop\ultralytics\movie\32210_640x360.mp4: 384x640 5 persons, 6 cars, 1 train, 507.0ms
video 1/1 (3/113) c:\Users\KIYO\Desktop\ultralytics\movie\32210_640x360.mp4: 384x640 11 persons, 7 cars, 1 bus, 525.0ms
video 1/1 (4/113) c:\Users\KIYO\Desktop\ultralytics\movie\32210_640x360.mp4: 384x640 10 persons, 8 cars, 2 buss, 482.0ms
video 1/1 (5/113) c:\Users\KIYO\Desktop\ultralytics\movie\32210_640x360.mp4: 384x640 11 persons, 6 cars, 2 buss, 1 truck, 482.0ms
video 1/1 (6/113) c:\Users\KIYO\Desktop\ultralytics\movie\32210_640x360.mp4: 384x640 12 persons, 3 cars, 3 buss, 503.0ms
video 1/1 (7/113) c:\Users\KIYO\Desktop\ultralytics\movie\32210_640x360.mp4: 384x640 10 persons, 6 cars, 3 buss, 476.0ms
video 1/1 (8/113) c:\Users\KIYO\Desktop\ultralytics\movie\32210_640x360.mp4: 384x640 8 persons, 5 cars, 3 buss, 1 truck, 470.0ms
video 1/1 (9/113) c:\Users\KIYO\Desktop\ultralytics\movie\32210_640x360.mp4: 384x640 7 persons, 6 cars, 476.0ms
video 1/1 (10/113) c:\Users\KIYO\Desktop\ultralytics\movie\32210_640x360.mp4: 384x640 5 persons, 1 bicycle, 10 cars, 1 bus, 464.0ms
video 1/1 (11/113) c:\Users\KIYO\Desktop\ultralytics\movie\32210_640x360.mp4: 384x640 10 persons, 8 cars, 1 bus, 479.0ms
video 1/1 (12/113) c:\Users\KIYO\Desktop\ultralytics\movie\32210_640x360.mp4: 384x640 6 persons, 9 cars, 2 buss, 484.0ms
video 1/1 (13/113) c:\Users\KIYO\Desktop\ultralytics\movie\32210_640x360.mp4: 384x640 4 persons, 6 cars, 3 buss, 495.0ms
...
video 1/1 (112/113) c:\Users\KIYO\Desktop\ultralytics\movie\32210_640x360.mp4: 384x640 12 persons, 4 cars, 1 truck, 1 backpack, 491.0ms
video 1/1 (113/113) c:\Users\KIYO\Desktop\ultralytics\movie\32210_640x360.mp4: 384x640 11 persons, 5 cars, 471.7ms
Speed: 1.0ms preprocess, 487.3ms inference, 1.0ms postprocess per image at shape (1, 3, 384, 640)
Results saved to runs\detect\predict4


5.API:推論(predict)
YOLOv8でできることは多数ありますが、まずは推論に絞ってYOLOv8の使用方法を記載します。転移学習は次章以降で対応します。
5-1.推論:model.predict
作成したモデルで推論する場合はmodelインスタンスにそのまま処理ファイルを与えるか、model.predict(<Path>)で実行可能です。
[IN]
from ultralytics import YOLO
model = YOLO(model="yolov8n.pt") #Detectionの最小Paramモデル
results = model(['bus.jpg']) #推論
# results = model.predict(['bus.jpg']) #こちらでもOK
#出力の確認
print(type(results), len(results))
print(type(results[0]))
print(f'Path:{results[0].path}')
print(f'names:{results[0].names}')
print(f'numpy:{type(results[0].numpy())}')[OUT]
<class 'list'> 1
<class 'ultralytics.engine.results.Results'>
Path:bus.jpg
names:{0: 'person', 1: 'bicycle', 2: 'car', 3: 'motorcycle', 4: 'airplane', 5: 'bus', 6: 'train', 7: 'truck', 8: 'boat', 9: 'traffic light', 10: 'fire hydrant', 11: 'stop sign', 12: 'parking meter', 13: 'bench', 14: 'bird', 15: 'cat', 16: 'dog', 17: 'horse', 18: 'sheep', 19: 'cow', 20: 'elephant', 21: 'bear', 22: 'zebra', 23: 'giraffe', 24: 'backpack', 25: 'umbrella', 26: 'handbag', 27: 'tie', 28: 'suitcase', 29: 'frisbee', 30: 'skis', 31: 'snowboard', 32: 'sports ball', 33: 'kite', 34: 'baseball bat', 35: 'baseball glove', 36: 'skateboard', 37: 'surfboard', 38: 'tennis racket', 39: 'bottle', 40: 'wine glass', 41: 'cup', 42: 'fork', 43: 'knife', 44: 'spoon', 45: 'bowl', 46: 'banana', 47: 'apple', 48: 'sandwich', 49: 'orange', 50: 'broccoli', 51: 'carrot', 52: 'hot dog', 53: 'pizza', 54: 'donut', 55: 'cake', 56: 'chair', 57: 'couch', 58: 'potted plant', 59: 'bed', 60: 'dining table', 61: 'toilet', 62: 'tv', 63: 'laptop', 64: 'mouse', 65: 'remote', 66: 'keyboard', 67: 'cell phone', 68: 'microwave', 69: 'oven', 70: 'toaster', 71: 'sink', 72: 'refrigerator', 73: 'book', 74: 'clock', 75: 'vase', 76: 'scissors', 77: 'teddy bear', 78: 'hair drier', 79: 'toothbrush'}
numpy:<class 'ultralytics.engine.results.Results'>使用できる引数の一部は下記の通りです。
save{defalut:False}:Trueでフォルダ内に画像を出力
stream{defalut:False}:Trueでジェネレータを返す
長い動画や大きなデータセットを効率的にメモリ管理するためにstream=Trueを使用
ストリーミングモードは、動画やライブストリームを処理する場合に有利であり、すべてのフレームをメモリにロードする代わりに結果のジェネレータを作成します
5-2.モデル選定:model
モデルの選定方法はmodel引数にモデルの重み(ptファイル)を指定します。具体的なモデルの種類や詳細は次項に記載します。
[Terminal(CLI)]
# Load a COCO-pretrained YOLOv8n model and train it on the COCO8 example dataset for 100 epochs
yolo train model=<モデルのPath> data=<yamlファイル> epochs=<エポック数> imgsz=<画像サイズ>
# Load a COCO-pretrained YOLOv8n model and run inference on the 'bus.jpg' image
yolo predict model=<モデルのPath> source=<ファイルのPath>[IN(Python)]
from ultralytics import YOLO
# Load a COCO-pretrained YOLOv8n model
model = YOLO(<モデルのpath>)
# Display model information (optional)
model.info()5-2-1.モデルの種類
UltralyticsライブラリではYOLOv8だけでなく、様々なモデルを選定することが出来ます。
YOLOv3: Joseph RedmonによるYOLOモデルファミリーの第三世代で、効率的なリアルタイムオブジェクト検出能力で知られています。
YOLOv4: 2020年にAlexey BochkovskiyによってリリースされたYOLOv3のdarknetネイティブアップデートです。
現段階でUltralyticsはYOLOv4モデルをサポートしていない
YOLOv5: UltralyticsによるYOLOアーキテクチャの改良版で、以前のバージョンと比較してパフォーマンスと速度のトレードオフが向上しています。
YOLOv7: YOLOv4の著者によって2022年にリリースされたYOLOモデルのアップデートです。
現段階でUltralyticsはYOLOv4モデルをサポートしていない
YOLOv8 NEW 🚀: YOLOファミリーの最新バージョンで、例えばインスタンスセグメンテーション、ポーズ/キーポイント推定、分類などの機能が強化されています。
Segment Anything Model (SAM): MetaのSegment Anything Model (SAM)です。
Mobile Segment Anything Model (MobileSAM): 慶應義塾大学によるモバイルアプリケーションのためのMobileSAMです。
Fast Segment Anything Model (FastSAM): 中国科学院自動化研究所、画像及びビデオ解析グループのFastSAMです。
YOLO-NAS: YOLO Neural Architecture Search (NAS)モデルです。
Realtime Detection Transformers (RT-DETR):百度のPaddlePaddle Realtime Detection Transformer (RT-DETR)モデルです。
使用方法はPyTorchの事前訓練済み*.ptモデルや構成*.yamlファイルをYOLO()、SAM()、NAS()、RTDETR()クラスに渡してインスタンス化することで利用できます。
5-2-2.YOLOv8モデルの詳細
YOLOv8の目的別(物体検出、セグメンテーション、姿勢推定、分類)のモデルは下記の通りです。4章クイックスタートでは問題に合わせて適当なモデルを選定しておりました。

5-3.処理対象の制定:source
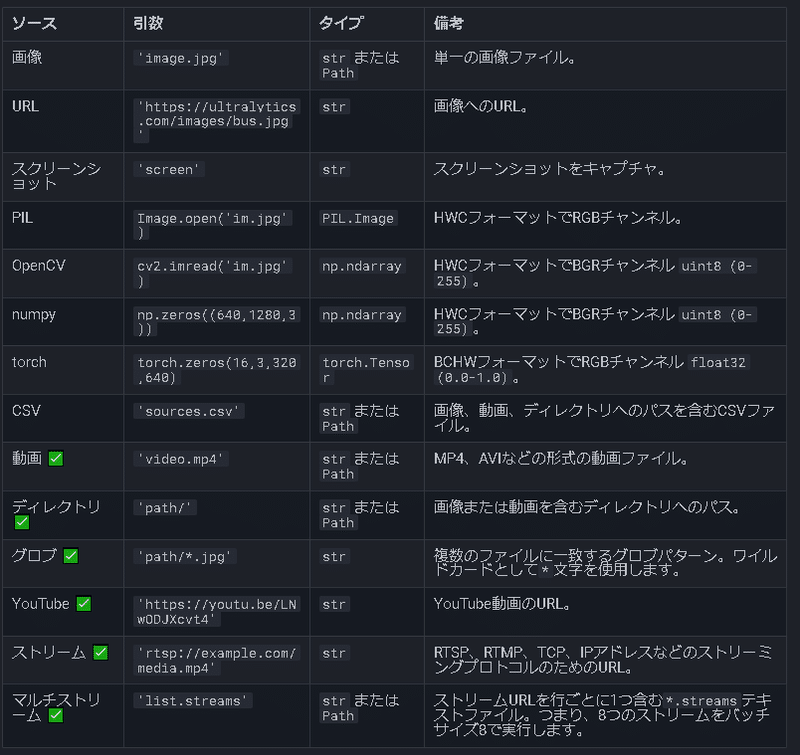
処理対象は静止画、動画以外にも様々なフォーマット(スクリーンショット、URL、PIL、OpenCV、numpy)に対応しています。
画像はリストで渡せばまとめて処理も可能です。
[IN※modelのpredict記載は省略]
from ultralytics import YOLO
model = YOLO(model="yolov8n.pt") #Detectionの最小Paramモデル
results = model(['bus.jpg', 'konan.jpg'], save=True) #推論
[OUT]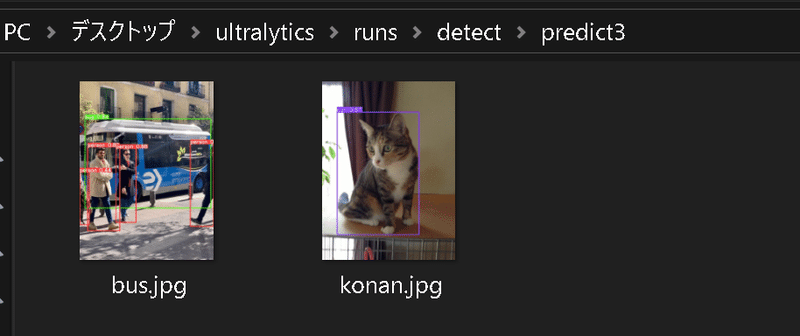
5-4.推論:model.predict()
推論はインスタンスに直接パスを渡すか、predictメソッドを使用します。クイックスタートでは”save=True”引数を渡して画像ファイルで出力しましたが、今回は引数無しで出力結果を確認しました。
5-4-1.シンプルVer.の出力確認
出力結果より下記が確認できました。
出力はリストであり、中に専用のクラス(Results)がある。
"stream=True"引数を渡せばジェネレータに変更可能
Resultsクラス内に物体検出の情報が含まれている。
[IN]
from ultralytics import YOLO
model = YOLO('yolov8n.pt') # 事前にトレーニングされたYOLOv8nモデルをロード
source = 'bus.jpg' # 画像ファイルへのパスを定義
results = model(source) # 推論を実行
#出力の確認
print(f'出力確認 Type:{type(results)} Length:{len(results)}')
print(f'出力確認 Type:{type(results[0])}')
results[0][OUT]
出力確認 Type:<class 'list'> Length:1
出力確認 Type:<class 'ultralytics.engine.results.Results'>
ultralytics.engine.results.Results object with attributes:
boxes: ultralytics.engine.results.Boxes object
keypoints: None
masks: None
names: {0: 'person', 1: 'bicycle', 2: 'car', 3: 'motorcycle', 4: 'airplane', 5: 'bus', 6: 'train', 7: 'truck', 8: 'boat', 9: 'traffic light', 10: 'fire hydrant', 11: 'stop sign', 12: 'parking meter', 13: 'bench', 14: 'bird', 15: 'cat', 16: 'dog', 17: 'horse', 18: 'sheep', 19: 'cow', 20: 'elephant', 21: 'bear', 22: 'zebra', 23: 'giraffe', 24: 'backpack', 25: 'umbrella', 26: 'handbag', 27: 'tie', 28: 'suitcase', 29: 'frisbee', 30: 'skis', 31: 'snowboard', 32: 'sports ball', 33: 'kite', 34: 'baseball bat', 35: 'baseball glove', 36: 'skateboard', 37: 'surfboard', 38: 'tennis racket', 39: 'bottle', 40: 'wine glass', 41: 'cup', 42: 'fork', 43: 'knife', 44: 'spoon', 45: 'bowl', 46: 'banana', 47: 'apple', 48: 'sandwich', 49: 'orange', 50: 'broccoli', 51: 'carrot', 52: 'hot dog', 53: 'pizza', 54: 'donut', 55: 'cake', 56: 'chair', 57: 'couch', 58: 'potted plant', 59: 'bed', 60: 'dining table', 61: 'toilet', 62: 'tv', 63: 'laptop', 64: 'mouse', 65: 'remote', 66: 'keyboard', 67: 'cell phone', 68: 'microwave', 69: 'oven', 70: 'toaster', 71: 'sink', 72: 'refrigerator', 73: 'book', 74: 'clock', 75: 'vase', 76: 'scissors', 77: 'teddy bear', 78: 'hair drier', 79: 'toothbrush'}
orig_img: array([[[122, 148, 172],
[120, 146, 170],
[125, 153, 177],
...,
[ 99, 89, 95],
[ 96, 86, 92],
[102, 92, 98]]], dtype=uint8)
orig_shape: (1080, 810)
path: 'c:\\Users\\KIYO\\Desktop\\ultralytics\\bus.jpg'
probs: None
save_dir: None
speed: {'preprocess': 2.000570297241211, 'inference': 56.0002326965332, 'postprocess': 2.001047134399414}【stream=True:ジェネレータ】
stream=Trueを指定することで出力をリストではなくジェネレータにできます。よって出力サイズが大きい時はメモリ抑制のために便利です。
[IN]
from ultralytics import YOLO
model = YOLO('yolov8n.pt') # 事前にトレーニングされたYOLOv8nモデルをロード
source = 'bus.jpg' # 画像ファイルへのパスを定義
results = model(source, stream=True) # 推論を実行
print(f'出力確認 Type:{type(results)}') #出力の確認
[OUT]
出力確認 Type:<class 'generator'>5-4-2.Resultsクラスの属性
Resultsクラスの属性は下記の通りです。Resultsクラスから分類や物体検出の情報が取得できることが分かります。
[IN]
[i for i in dir(result) if not i.startswith('_')]
[OUT]
['boxes','cpu','cuda','keypoints','masks','names','new','numpy',
'orig_img','orig_shape','path','plot','probs','save_crop','save_dir',
'save_txt','speed','to','tojson','update','verbose']結果を確認しました。今回はYOLOv8による物体検出のためboxes属性にすべての情報が含まれていました。
[IN]
boxes = result.boxes # バウンディングボックス出力用のBoxesオブジェクト
masks = result.masks # セグメンテーションマスク出力用のMasksオブジェクト
keypoints = result.keypoints # 姿勢出力用のKeypointsオブジェクト
probs = result.probs # 分類出力用のProbsオブジェクト
id2label = result.names # クラス名のリスト
print(f'出力確認 Type:{type(boxes)} Length:{len(boxes)}')
print(f'出力確認 Type:{type(masks)}')
print(f'出力確認 Type:{type(keypoints)}')
print(f'出力確認 Type:{type(probs)}')
print(result.names)
print(boxes[0])
[OUT]
出力確認 Type:<class 'ultralytics.engine.results.Boxes'> Length:6
出力確認 Type:<class 'NoneType'>
出力確認 Type:<class 'NoneType'>
出力確認 Type:<class 'NoneType'>
{0: 'person', 1: 'bicycle', 2: 'car', 3: 'motorcycle', 4: 'airplane', 5: 'bus', 6: 'train', 7: 'truck', 8: 'boat', 9: 'traffic light', 10: 'fire hydrant', 11: 'stop sign', 12: 'parking meter', 13: 'bench', 14: 'bird', 15: 'cat', 16: 'dog', 17: 'horse', 18: 'sheep', 19: 'cow', 20: 'elephant', 21: 'bear', 22: 'zebra', 23: 'giraffe', 24: 'backpack', 25: 'umbrella', 26: 'handbag', 27: 'tie', 28: 'suitcase', 29: 'frisbee', 30: 'skis', 31: 'snowboard', 32: 'sports ball', 33: 'kite', 34: 'baseball bat', 35: 'baseball glove', 36: 'skateboard', 37: 'surfboard', 38: 'tennis racket', 39: 'bottle', 40: 'wine glass', 41: 'cup', 42: 'fork', 43: 'knife', 44: 'spoon', 45: 'bowl', 46: 'banana', 47: 'apple', 48: 'sandwich', 49: 'orange', 50: 'broccoli', 51: 'carrot', 52: 'hot dog', 53: 'pizza', 54: 'donut', 55: 'cake', 56: 'chair', 57: 'couch', 58: 'potted plant', 59: 'bed', 60: 'dining table', 61: 'toilet', 62: 'tv', 63: 'laptop', 64: 'mouse', 65: 'remote', 66: 'keyboard', 67: 'cell phone', 68: 'microwave', 69: 'oven', 70: 'toaster', 71: 'sink', 72: 'refrigerator', 73: 'book', 74: 'clock', 75: 'vase', 76: 'scissors', 77: 'teddy bear', 78: 'hair drier', 79: 'toothbrush'}
ultralytics.engine.results.Boxes object with attributes:
cls: tensor([5.])
conf: tensor([0.8705])
data: tensor([[ 17.2858, 230.5922, 801.5182, 768.4058, 0.8705, 5.0000]])
id: None
is_track: False
orig_shape: (1080, 810)
shape: torch.Size([1, 6])
xywh: tensor([[409.4020, 499.4990, 784.2324, 537.8136]])
xywhn: tensor([[0.5054, 0.4625, 0.9682, 0.4980]])
xyxy: tensor([[ 17.2858, 230.5922, 801.5182, 768.4058]])
xyxyn: tensor([[0.0213, 0.2135, 0.9895, 0.7115]])参考までにboxesのラベル情報を確認しました。結果として物体検出された画像と同じ結果であることを確認できました。
[IN]
for box in boxes:
print(id2label[int(box.cls)])
[OUT]
bus
person
person
person
stop sign
person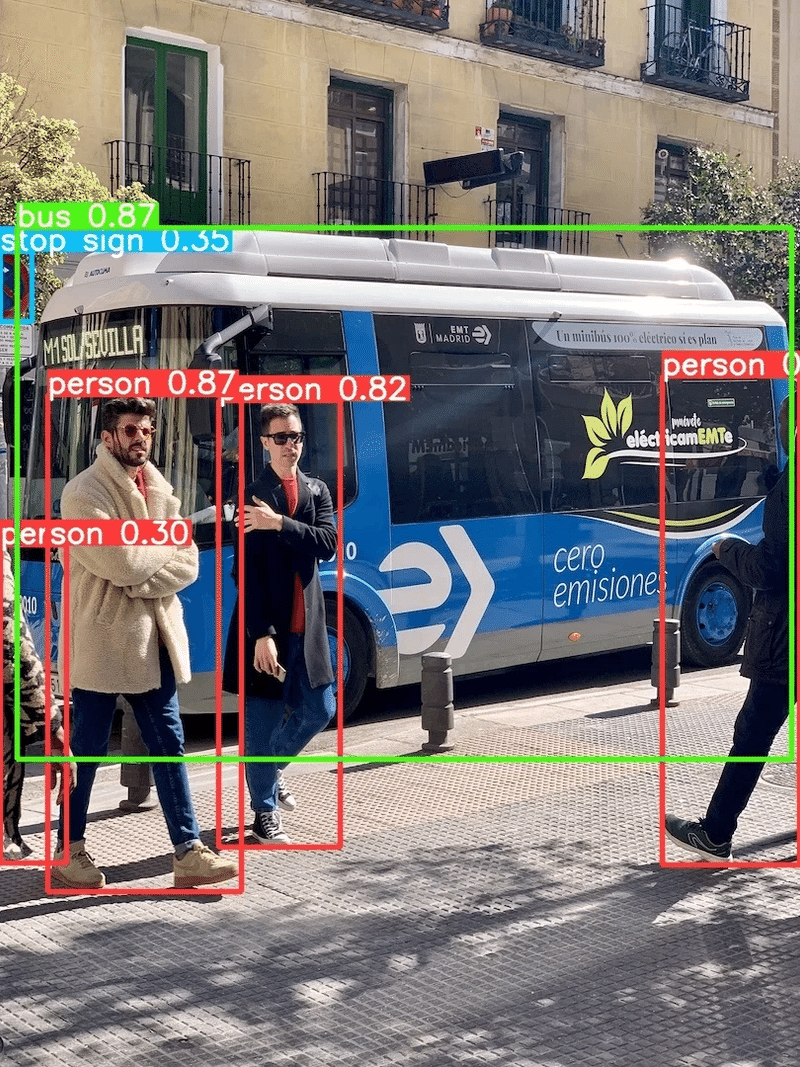
6.転移学習:Train Mode
データセットを使用してオリジナルの物体検出モデルを作成します。
6-1.学習用データセット作成
次節以降では下記記事で使用したデータを使用していきます。参考までに本節ではデータセットの作り方を紹介します。
6-1-1.データセットの作成フロー
オリジナルのデータセットで学習させるためには下記手順が必要です。
画像収集:対象としたい物が含まれる画像を収集する
基本的には学習(Train)、検証(Valid)、テスト(test)の3種類を用意
画像のアノテーション:タスクに応じてバウンディングボックス、セグメント、またはキーポイントでアノテートする
アノテーションをエクスポート:アノテーションをUltralyticsがサポートしているYOLO *.txtファイルフォーマットに変換
データセットを編成:データセットを正しいフォルダ構造に配置する。
例として、train/ 、val/ のトップレベルディレクトリーを持ち、各ディレクトリー内に images/ 、labels/ のサブディレクトリーを持つ。
Path詳細はdata.yamlに記載するため、ある程度変更は可能
data.yamlファイルを作成:データセットのルートディレクトリに、データセット、クラス、その他の必要な情報を記述するdata.yamlファイルを作成する。
画像を最適化(任意):データセットのサイズを削減してより効率的な処理を行いたい場合は、以下のコードを使用して画像を最適化することができます。※任意のため実施しないデータセットをZip化:データセットフォルダ全体をzipファイルに圧縮
ドキュメントとPRを作成:データセットに関するドキュメンテーションページを作成し、既存のフレームワークにどのように適合するかを説明し、その後でPull Request (PR)を提出します。PRを提出する方法の詳細については、Ultralyticsの貢献ガイドラインを参照。
[Datasetのディレクトリ構造:参考例1]
dataset/
├── train/
│ ├── images/
│ └── labels/
└── val/
├── images/
└── labels/[Datasetのディレクトリ構造:参考例2]
dataset/
├── images/
│ ├── train/
│ └── val/
└── labels/
├── train/
└── val/6-1-2.オープンソースのデータセット
オリジナル画像でのモデル作成時に一番時間がかかるところはアノテーションです。アノテーションデータがないものはマンパワーをかけて実施する必要がありますが、既にデータがある場合はオープンソースを利用するのがベストです。
有名なところではAIモデル構築プラットフォーム:Roboflowが提供するRoboflow Universe(90,000のデータセットと7,000 の事前トレーニング済みモデルが利用可能なオープンソース)があります。
6-1-3.Roboflow Universeでデータ取得
参考までに指のデータセットを取得してみます。検索時は下記条件で絞り込みもできます。
Has a Model:モデルの有無を選択
Project Type:分類、物体検出、セグメンテーションなどを選択
Model Type:YOLOv8や他のモデル用を選択
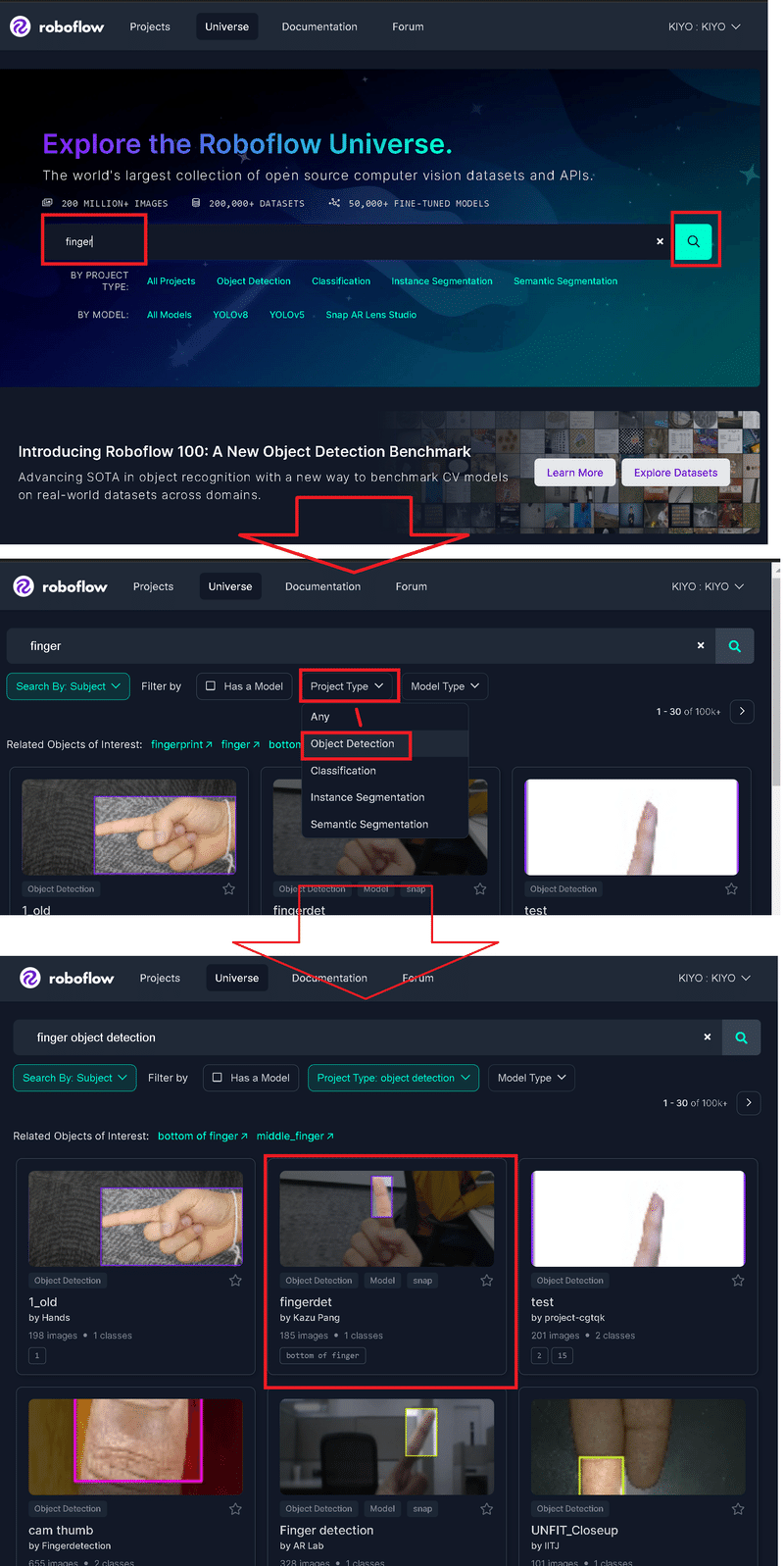
欲しいデータセットを選択して「Download this Dataset」を選択する。Exportウィンドウが開き”Format”と”出力方法”を選択して"Continue"を押すとファイルが取得できる。
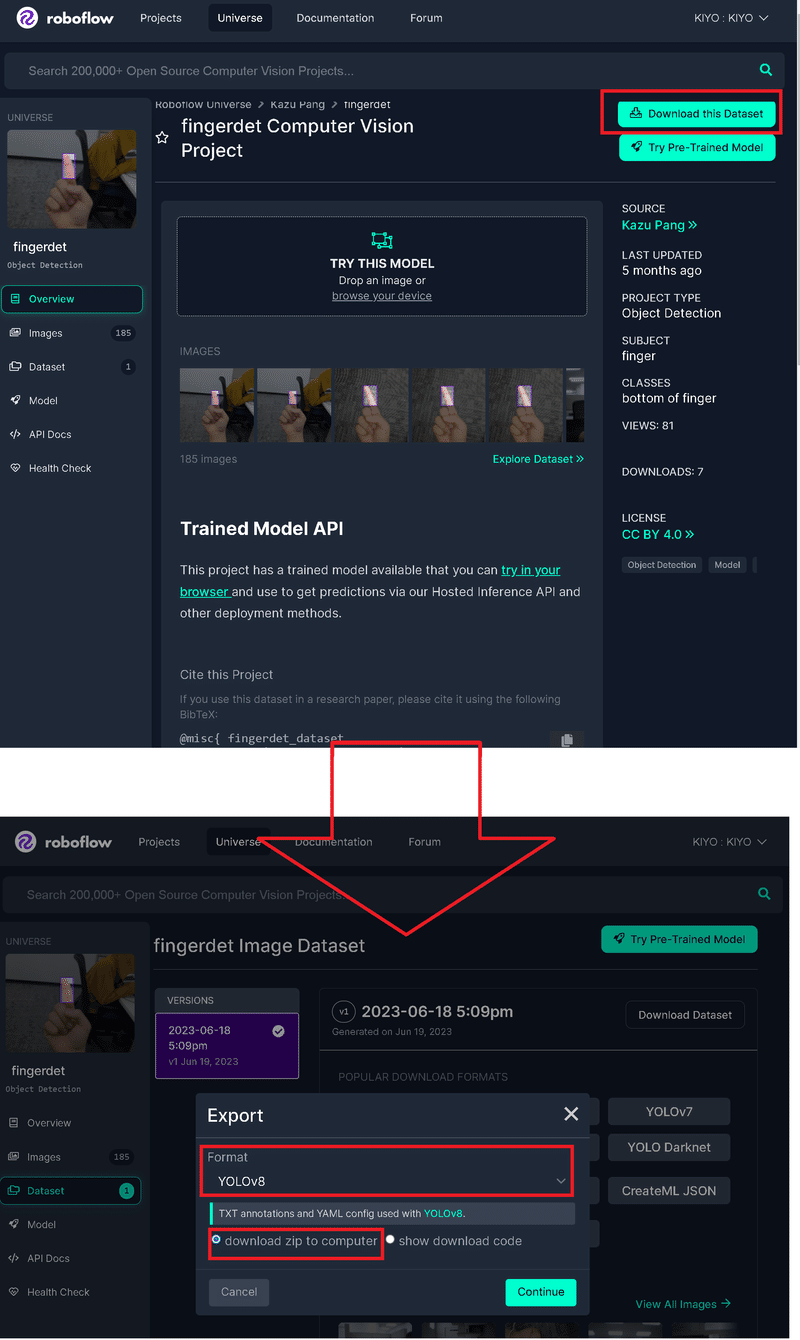
ファイルの構成はtrain, valid, testがあり、それぞれimagesとlabelsフォルダを含んでおり、学習用のdata.yamlファイルもあります。ラベルはYolov5と同じく[<class index>, <相対座標>]となります。
[data.yaml]
train: ../train/images
val: ../valid/images
test: ../test/images
nc: 1
names: ['bottom of finger']
roboflow:
workspace: kazu-pang-j1rxo
project: fingerdet
version: 1
license: CC BY 4.0
url: https://universe.roboflow.com/kazu-pang-j1rxo/fingerdet/dataset/1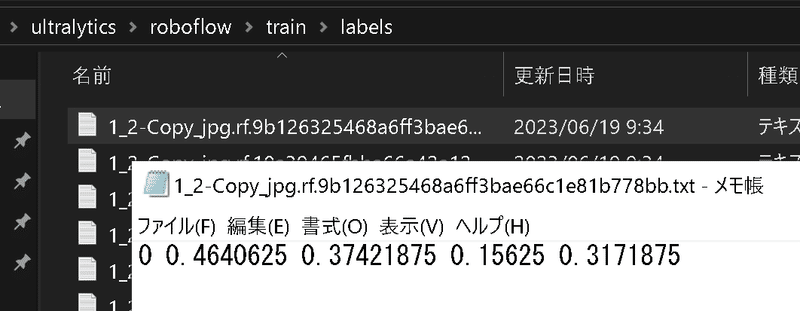
6-2.アノテーション
物体検出のためのラベル(正解データ)を作成します。今回は物体検出のため下記実行しました。詳細は記事をご確認ください。
VOTTを使用してラベル付け(アノテーション)
アノテーション結果を出力(JSONファイル)
ラベルの作成(indexと物体名の紐づけ)
絶対座標を相対座標に変換
サンプルとしてアノテーションは下図の通り「眉毛」と「指」です。

6ー3.yamlファイルの作成
YOLOv5同様にYOLOv8ではデータ学習用のデータパス、分類数、分類名を"data.yaml"で指定します。指定する内容は下記の通りです。
path:データセットのルートディレクトリ
train:訓練用データセットのパス
val:検証用データセットのパス
test:テスト用データセットのパス(オプション)
nc:データセット内のクラス数
names:クラスの名前のリスト
6-1ー1項より、データセットの学習・検証ディレクトリの配置を整備したうえで、構成に合わせてdata.yamlを下記の通り作成しました。
[data.yaml]
path: C:/Users/KIYO/Desktop/ultralytics/dataset
train: train/images #トレーニング用画像データのパス
val: valid/images #検証用画像データのパス
nc: 6 #クラスの数
#クラスの名前
names: ['thumb',
'index finger',
'middle finger',
'ring finger',
'little finger',
'eyebrows'] 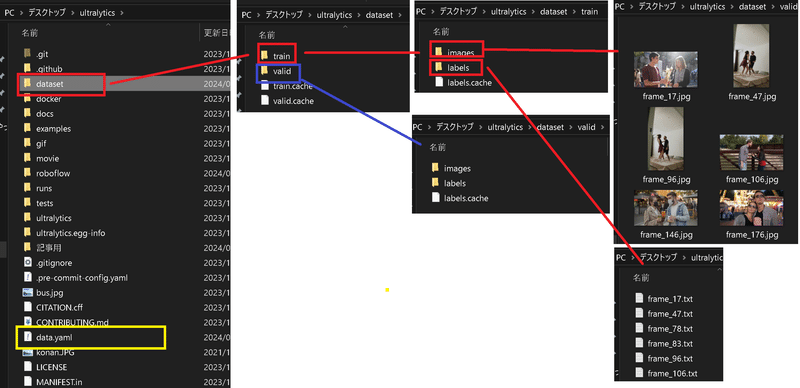
6-4.モデルの学習:model.train()
モデルの学習はtrain(<yamlファイル>, <学習条件>)で実施します。渡すことが出来る引数の一部は下記の通りです。
data:これは学習に使用するデータセットの設定ファイルへのパス
作成したyamlファイルを指定する
epochs:学習回数
imgsz:入力画像のサイズ
device:CPU/GPUの選定
引数の指定がなければtorch.deviceで自動判定
device=[0, 1]でマルチGPUトレーニングの指定も可能
AppleのM1およびM2チップはdevice='mps'で指定
verbose:学習時の出力を表示
今回は100Epochで学習してみました。約22minで学習は完了し、出力に記載の通り"runs/detect/train"に学習結果やモデルの重みが格納されています。
”results.png”の結果を確認するとTrainのlossはほぼ落ち着いており、かつValidの過学習も確認されていないため十分だと思います。
[Terminal]
from ultralytics import YOLO
model = YOLO('yolov8n.pt') # モデルを選択 #学習
model.train(data='data.yaml', epochs=100, batch=8, verbose=True)[OUT]
from n params module arguments
0 -1 1 464 ultralytics.nn.modules.conv.Conv [3, 16, 3, 2]
1 -1 1 4672 ultralytics.nn.modules.conv.Conv [16, 32, 3, 2]
2 -1 1 7360 ultralytics.nn.modules.block.C2f [32, 32, 1, True]
3 -1 1 18560 ultralytics.nn.modules.conv.Conv [32, 64, 3, 2]
4 -1 2 49664 ultralytics.nn.modules.block.C2f [64, 64, 2, True]
5 -1 1 73984 ultralytics.nn.modules.conv.Conv [64, 128, 3, 2]
6 -1 2 197632 ultralytics.nn.modules.block.C2f [128, 128, 2, True]
7 -1 1 295424 ultralytics.nn.modules.conv.Conv [128, 256, 3, 2]
8 -1 1 460288 ultralytics.nn.modules.block.C2f [256, 256, 1, True]
9 -1 1 164608 ultralytics.nn.modules.block.SPPF [256, 256, 5]
10 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
11 [-1, 6] 1 0 ultralytics.nn.modules.conv.Concat [1]
12 -1 1 148224 ultralytics.nn.modules.block.C2f [384, 128, 1]
13 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
14 [-1, 4] 1 0 ultralytics.nn.modules.conv.Concat [1]
15 -1 1 37248 ultralytics.nn.modules.block.C2f [192, 64, 1]
16 -1 1 36992 ultralytics.nn.modules.conv.Conv [64, 64, 3, 2]
17 [-1, 12] 1 0 ultralytics.nn.modules.conv.Concat [1]
18 -1 1 123648 ultralytics.nn.modules.block.C2f [192, 128, 1]
...
fitness: 0.04073054406864612
keys: ['metrics/precision(B)', 'metrics/recall(B)', 'metrics/mAP50(B)', 'metrics/mAP50-95(B)']
maps: array([ 0.0015891, 0.04045, 0.026676, 0.023341, 0.0446, 0.053807])
names: {0: 'thumb', 1: 'index finger', 2: 'middle finger', 3: 'ring finger', 4: 'little finger', 5: 'eyebrows'}
plot: True
results_dict: {'metrics/precision(B)': 0.3353993935483646, 'metrics/recall(B)': 0.15086691748421563, 'metrics/mAP50(B)': 0.12160982183184517, 'metrics/mAP50-95(B)': 0.03174395765051289, 'fitness': 0.04073054406864612}
save_dir: WindowsPath('runs/detect/train')
speed: {'preprocess': 0.7999777793884277, 'inference': 35.99998950958252, 'loss': 0.0, 'postprocess': 12.20017671585083}
task: 'detect'

6-5.学習済みモデルによる推論:YOLO(<重み.pt>)
Train完了後に得られるモデル重み(last.pt)からモデルを作成し、推論を実施しました。推論はテストデータが良いのですが、枚数がないため検証用データを利用してみました。
[Terminal]
trainedmodel = YOLO('runs/detect/train/weights/last.pt') # 学習済みモデルをロード
trainedmodel("./dataset/valid/images",
save=True, #画像ファイルで保存
conf=0.2, #confidenceの閾値:低いほど多くの検出が行われる
iou=0.5) #IoU(Intersection over Union)の閾値:低いほど多くの検出が行われる[OUT]
image 1/20 c:\Users\KIYO\Desktop\ultralytics\dataset\valid\images\frame_106.jpg: 384x640 (no detections), 51.0ms
image 2/20 c:\Users\KIYO\Desktop\ultralytics\dataset\valid\images\frame_113.jpg: 640x384 (no detections), 53.0ms
・・・
image 19/20 c:\Users\KIYO\Desktop\ultralytics\dataset\valid\images\frame_950.jpg: 384x640 1 index finger, 1 little finger, 3 eyebrowss, 44.0ms
image 20/20 c:\Users\KIYO\Desktop\ultralytics\dataset\valid\images\frame_96.jpg: 640x384 (no detections), 48.0ms
Speed: 1.4ms preprocess, 50.4ms inference, 0.8ms postprocess per image at shape (1, 3, 640, 384)
Results saved to runs\detect\predict6
[ultralytics.engine.results.Results object with attributes:
boxes: ultralytics.engine.results.Boxes object
keypoints: None
masks: None
names: {0: 'thumb', 1: 'index finger', 2: 'middle finger', 3: 'ring finger', 4: 'little finger', 5: 'eyebrows'}
orig_img: array([[[214, 195, 180],
orig_shape: (1920, 1080)
path: 'c:\\Users\\KIYO\\Desktop\\ultralytics\\dataset\\valid\\images\\frame_96.jpg'
probs: None
save_dir: 'runs\\detect\\predict6'
speed: {'preprocess': 2.0008087158203125, 'inference': 48.000335693359375, 'postprocess': 0.0}]結果は出力の通り"runs\detect\predictx"に保存されています。感触として、YOLOv5と同等くらいの結果と思います。今回は簡易のために最も軽量な"yolov8n.pt"を利用しているため、高精度なモデルならうまくいくかもしれません(画像データが足りない可能性もありますが)。




7.エクスポート
最後に学習したモデルを別形式で出力してみます。出力できる形式は下記の通りです。
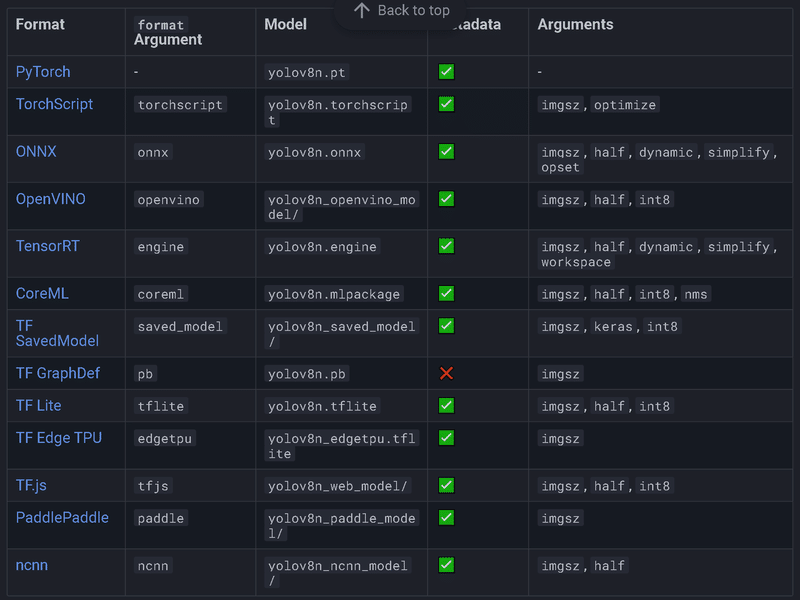
公式サンプルは下記の通りです。ただ私が同様の形で実行すると「ModuleNotFoundError: No module named 'onnx'」と出ました。おそらく別の環境構築が必要になると思いますので、今回は紹介までとなります。
[IN]
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8n.pt') # load an official model
model = YOLO('path/to/best.pt') # load a custom trained model
# Export the model
model.export(format='onnx')
[OUT]
―別添 アノテーションによるラベル作成:VOTT
自分用の学習モデルを作成する場合、ラベル付け(”アノテーション)も自分で行う必要があります。アノテーションツールのVOTTと実用例は下記記事の通りです。
参考資料
Python関係
YOLOv8
あとがき
リリース元がYOLOv5と同じだったので、案外簡単だった。YOLOv8でセマンティックセグメンテーションもできると思うので、別途フォローしたい。
この記事が気に入ったらサポートをしてみませんか?