
SIGNATE-練習コンペ:ガラスの分類(その1)

1.概要
SIGNATEの「【練習問題】ガラスの分類ー酸化物含有量からガラスの種類(6種)を分類しよう!」に参加しました。
比較的簡単な部類であり、リーダーボードをみるともの高精度な結果もあるためいくつか試してみたいと思います。

2.事前準備:SIGNATE側
2-1.学習・評価用データのダウンロード
学習・評価用データを下記からダウンロードします。CLIでもDL可能ですが今回はHPから直接DLしました。

2-2.SIGNATE APIトークンの準備
データ予想後のCSVを提出する時にCLIを使用したいため事前にAPI Token(signate.json)を準備も必要であれば実施します。ホーム右上の「投稿」から直接投稿できるため、今回は本作業も省きました。
3.探索的データ解析:EDA
EDA(Exploratory Data Analysis)を実施して、データの理解を深めたうえでモデルを実装していきます。
3-1.データの概要確認
3-1-1.コンペ情報
コンペページより下記が確認できます。
ガラスの屈折率と組成からガラス種を判定する分類問題
一般論として種類は成分組成によって決まるはずなので、特徴量エンジニアリングでガラスの化学的特性を出せるかが重要
製法の違いを出すには屈折率しかデータがない
(MIらしく)データ数が107個と少ない
学習・検証データセットの分け方も重要
分類問題でclass:4の情報がない->もしテスト側にclass4となるデータが入っている場合、決定木だとかなり厳しい
(後述の通り、)107データの内7割以上がclass1と2のデータであり、不均衡データセットである。よって分割方法や不均衡解消(アンダーサンプリングなど)を検討する必要があるかもしれない。
複雑なモデルだと過学習の恐れがあるため、シンプルなモデルの結果をベンチマークとしながら比較する方がよさそう
数値がwt%なのかat&なのか実験時の合成重量なのか不明。


【クラスの翻訳】
ビル用窓ガラス_フロート加工
ビル用窓ガラス_非フロート加工
車載用窓ガラス_フロート加工
-
コンテナ
食器
ヘッドランプ
3-1-2.ドメイン知識
ケイ酸 SiO2:ガラスの網目構造を作る。軟化温度が高く、熱膨張係数が小さい。化学的に安定である。
ホウ酸 B2O3:ガラスの網目構造を作る。熱膨張係数や化学耐久性に変化を与えずに軟化温度を下げる。分相しやすい。
アルミナ Al2O3:結晶化を抑える。軟化温度を上げる。
酸化鉛 PbO:屈折率が大きい。還元ふん囲気ではPbになる。金属との濡れを良くする。
酸化ナトリウム Na2O:軟化温度を下げる。熱膨張係数を大きくする。化学耐久性を減少させる。
酸化カリウム K2O:Na2Oと同じ効果。 Na+より大きいので移動せず、化学耐久性はNa2Oより大きい。光沢を与える。
酸化カルシウム CaO:アルカリの移動を止めるためアルカリガラスの化学耐久性を増す。
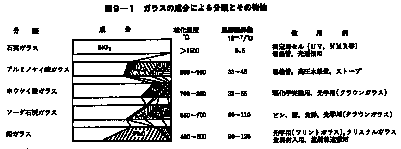
以上のほか、MgO, BaOなどがある。これらがどのような割合で混合されるかによりガラスの性質が決まる。ガラスの成分による分類とその特性を表9-1に示す。理化学実験に用いられるガラスは主に石英ガラスとホウケイ酸ガラスである。
屈折率は組成によって決まり、反射率や透過率も屈折率に依存する。



3-2.データの中身確認
ダウンロードしたデータをPandasでDataFrame化して中身を確認します。ファイルはtsv形式で1列目がidのため”pd.read_csv(<filepath>, delimiter='\t', index_col=0)”で抽出しました。
train, test(提出用)ともに107データであり、目的変数は"Type"列に入っています。
[IN]
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import seaborn as sns
import japanize_matplotlib
import os, glob
import pycaret
from sklearn.model_selection import train_test_split
class HorizontalDisplay:
def __init__(self, *args):
self.args = args
def _repr_html_(self):
template = '<div style="float: left; padding: 10px;">{0}</div>'
return '\n'.join(template.format(a._repr_html_()) for a in self.args)
#EDA (Exploratory Data Analysis)
def summary(df):
print(f'data shape: {df.shape}')
summ = pd.DataFrame(df.dtypes, columns=['data type'])
summ['#missing'] = df.isnull().sum().values * 100
summ['%missing'] = df.isnull().sum().values / len(df)
summ['#unique'] = df.nunique().values
desc = pd.DataFrame(df.describe(include='all').transpose())
summ['min'] = desc['min'].values
summ['max'] = desc['max'].values
summ['first value'] = df.iloc[0, :].values
summ['second value'] = df.iloc[1, :].values
summ['third value'] = df.iloc[2, :].values
return summ
def plot_missing_values_ratio(df_list, titlenames, threshold=1, verbose=False):
if isinstance(df_list, pd.DataFrame):
df_list = [df_list]
fig, axes = plt.subplots(nrows=1, ncols=len(df_list), figsize=(8 * len(df_list), 8))
plt.rcParams['font.size'] = 16
if len(df_list) == 1:
axes = [axes]
for i, (df, titlename) in enumerate(zip(df_list, titlenames)):
missing_ratios = df.isna().sum() / len(df)
colors = ['red' if ratio == 1 else
'pink' if ratio >= threshold else
'orange' for ratio in missing_ratios.values]
#欠損値を割合による色分けで棒グラフを描画
axes[i].bar(missing_ratios.index,
missing_ratios.values,
color=colors)
#閾値の線を描画
axes[i].axhline(y=threshold, color='red', linestyle='--', lw=0.5)
axes[i].set_xlabel('Feature', fontsize=12)
axes[i].set_ylabel('Missing values ratio', fontsize=12)
axes[i].set_yticks(np.arange(0, 1.1, 0.1))
axes[i].set_title(f'Missing values ({titlename})', fontsize=12)
axes[i].tick_params(axis='x', labelrotation=90)
axes[i].legend(handles=[mpatches.Patch(color='orange'),
mpatches.Patch(color='pink'),
mpatches.Patch(color='red')],
labels=[f'部分欠損 < {threshold}' ,
f'部分欠損 >= {threshold}',
'完全欠損'],
fontsize=12)
#グリッド線を描画
if verbose:
axes[i].grid(axis='y')
plt.tight_layout()
plt.show()
file_train, file_test = 'train.tsv', 'test.tsv'
df_train = pd.read_csv(file_train, delimiter='\t', index_col=0)
df_test = pd.read_csv(file_test, delimiter='\t', index_col=0)
display(HorizontalDisplay(df_train, df_test))[OUT]
3-2-1.チーティングチェック
チーティングとはコンペルール外や目的と外れた手法で性能向上を目指すことでありコンペ外データ使用、多重アカウントなどがあります。
今回はindex番号から学習とテストが連番であることは分かりますので、管径があるかだけ確認しておきます。
結果としてはある程度傾向はありそうなので時系列変化処理でもそれなりの性能が出るかもしれませんが、本書では意味がないので次へ進みます。
[IN]
df_train_leakcheck = df_train.copy()
df_train_leakcheck = df_train_leakcheck.reset_index()
fig, ax = plt.subplots(1,1, figsize=(20, 6), facecolor='white')
sns.scatterplot(x='index', y='Type', data=df_train_leakcheck,
ax=ax, hue='Type', s=100, style='Type', palette='bright')
ax.set(title='IndexとTypeの関係', xticks=np.arange(0, df_train_leakcheck['index'].iloc[-1], 2))
plt.xticks(rotation=90)
ax.grid()
[OUT]
3-3.データの概要・欠損値確認
下記記事の関数を使用してデータの概要と欠損値確認しました。
全て連続値でありエンコーディングなどは不要
欠損値は無いため前処理不要
組成は連続値だが比較的同じ値のものも多い
[IN]
summary(df_train)
summary(df_test)
plot_missing_values_ratio([df_train, df_test], ['train', 'test'], threshold=0.1, verbose=True)[OUT]
data shape: (107, 10)
data shape: (107, 9)


3-4.クラスの不均衡確認
クラスデータの不均衡を確認しました。結果としてtype1,2だけで75%、Type7を含めると86%の割合を占めます。つまり学習・検証データへ分割時に適当にすると、7分類問題にも関わらずtype1,2だけ使用しても75%程度の正解率が得られます。
学習・検証の精度はどのような判定をしているか確認する必要があります。
[IN] #データの概要・欠損値確認 ]
_data = df_train['Type'].value_counts().sort_index()
_idxs, _vs = _data.index, _data.values
plt.bar(_idxs, _vs, color='blue')
for i, v in zip(_idxs, _vs):
plt.text(i, v, v, ha='center', va='bottom', fontsize=12)
plt.xticks(np.arange(1, 8, 1)), plt.xlabel('Type'), plt.ylabel('Count'), plt.grid()
df_train['Type'].value_counts()[OUT]
2 47
1 33
7 12
5 6
3 5
6 4
Name: Type, dtype: int64
3-5.相関関係の確認
データ数が少ない場合は各次元の相関関係を確認するために「散布図行列:sns.pairplot()」と「sns.heatmap()」が非常に便利です。
まずは全Typeまとめて確認しました。結果は下記の通りです。
CaとNaの相関関係は小さい。「ソーダ石灰ガラスでは、ナトリウムと一緒に使われる」、「CaOはアルカリの移動を止めるためアルカリガラスの化学耐久性を増す」なので相関係数高いと思ってたけどなんでや??
CaとRI(屈折率)の相関は高い。
Na、Mg, Al, BaあたりがType(ラベル)との相関が高い。プロット見る限り、特定エリアは決定木で分けれそう。Baは0のデータが多いため注意
[IN]
sns.pairplot(df_train, palette='Set1')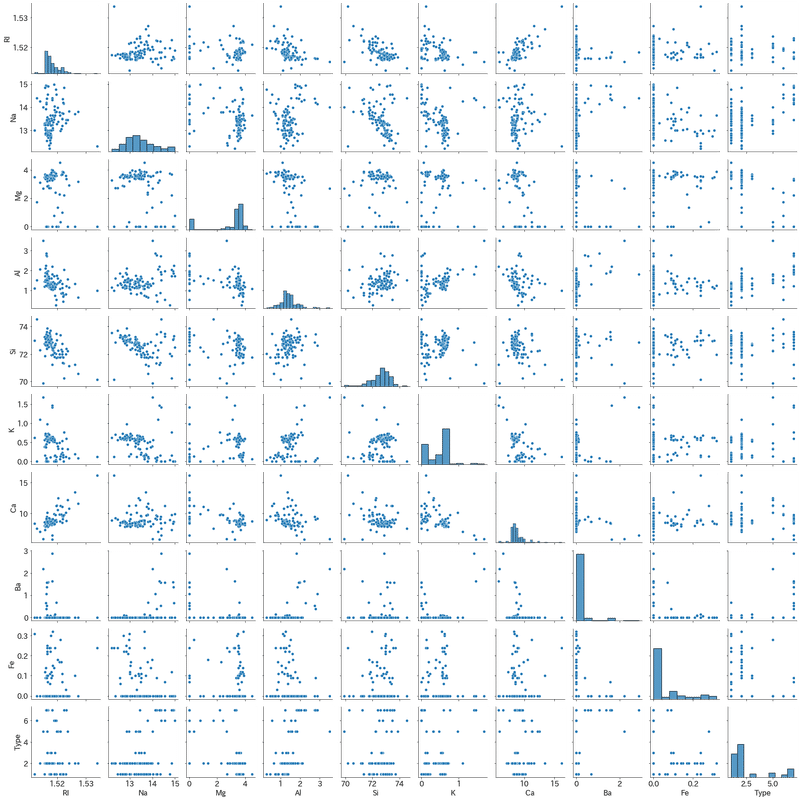
[IN]
fig, ax = plt.subplots(figsize=(15, 15), facecolor='white')
sns.heatmap(df_train.corr(), annot=True, cmap='coolwarm')
plt.title('Correlation Matrix', fontsize=20)
各Type(クラス)でのプロットも可視化しました。ここではtype1, 2, 7が大部分を占めるため、前の情報と大差はありませんでした。
※ラベル4が欠損値のためmarkersは6個で指定しないとエラー
[IN]
# sns.pairplot(df_train, palette='Set1', hue='Type', diag_kind='kde')
sns.pairplot(df_train, palette='Set1', hue='Type', diag_kind='kde', markers=['o', 's', 'D', 'X', 'v', '<'])
4.Case1:AutoML(PyCaret)でごり押し
特に前処理不要であることは分かりました。(実際にやったらダメでしたが)特徴量はシンプルのため適合性の良いモデルにあてはめたらいけると仮定して、AutoMLで処理して最適なモデルを選定することにしました。
今回使用したAutoMLはPyCaretです。細かい説明は記事にあるため本章では要点と結果のみ紹介します。
4-1.PyCaretの前処理:setup()
PyCaretから分類問題を選択して"setup()"で前処理します。
【設計】
データ数が少ないため、学習:検証=8:2と学習データの比率を増加
データ数が少なく不均衡もあるため交差検証のfold数は5に設定
【結果】
Fix Imbalance=Trueにするとエラーは出ないが次節での学習時に結果が出ないためコメントアウト->おそらくSMOTE処理をしているがここで異常が発生->Type4のデータが存在しないためかもしれない。
学習は指定割合に分割されている。
[IN]
from pycaret.classification import * #分類
exp = setup(df_train,
target='Type', #目的変数
session_id=123, #乱数シード
silent=True, #実行時のログを表示
train_size=0.8, #学習データの割合
log_experiment=True, #mlflowにログを残す
use_gpu=True, #GPUを使う
# fix_imbalance=True, #不均衡データの調整
fold=5, #交差検証の分割数
)
[OUT]
4-2.複数モデルで一括学習:compare_models()
複数のモデルで一括学習します。”best_model = compare_models()”とすることでSoTAモデルの結果を変数で取得できます。
結果としてtree系(Extra Tree, Random Forest, LightGBM)やldaが強い
ロジスティック回帰の精度は61%程度でよくない。
SVMはハイパラ調整必須だが、たぶん頑張って決定木レベル
トップクラスは100%に近い精度だったことを考えると全然ダメ->モデルで頑張るより特徴量エンジニアリングが必要
[IN]
best_model = compare_models()
best_model[OUT]
ExtraTreesClassifier(bootstrap=False, ccp_alpha=0.0, class_weight=None,
criterion='gini', max_depth=None, max_features='auto',
max_leaf_nodes=None, max_samples=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=100, n_jobs=-1,
oob_score=False, random_state=123, verbose=0,
warm_start=False)
Model Accuracy AUC Recall Prec. F1 Kappa MCC TT (Sec)
et Extra Trees Classifier 0.7294 0.5294 0.5935 0.6669 0.6933 0.5879 0.5966 0.3300
lda Linear Discriminant Analysis 0.6941 0.5235 0.5618 0.6551 0.6561 0.5662 0.5764 0.0080
rf Random Forest Classifier 0.6824 0.5340 0.5163 0.6269 0.6417 0.5136 0.5325 0.3320
knn K Neighbors Classifier 0.6588 0.4882 0.5060 0.6147 0.6261 0.4897 0.5030 0.0320
ridge Ridge Classifier 0.6353 0.0000 0.4835 0.5587 0.5645 0.4039 0.4451 0.0060
lightgbm Light Gradient Boosting Machine 0.6353 0.5126 0.4600 0.5687 0.5854 0.4352 0.4508 0.4760
gbc Gradient Boosting Classifier 0.6235 0.4720 0.5425 0.5744 0.5881 0.4390 0.4472 0.2880
lr Logistic Regression 0.6118 0.4948 0.4848 0.4950 0.5345 0.3768 0.4219 0.1760
dt Decision Tree Classifier 0.6118 0.4158 0.5022 0.6064 0.6006 0.4336 0.4382 0.0080
ada Ada Boost Classifier 0.5059 0.4192 0.3257 0.3468 0.3962 0.1900 0.2369 0.0700
dummy Dummy Classifier 0.4706 0.3000 0.1800 0.2215 0.3012 0.0000 0.0000 0.0060
nb Naive Bayes 0.4471 0.4373 0.3067 0.3838 0.3915 0.1498 0.1587 0.0100
qda Quadratic Discriminant Analysis 0.4000 0.2009 0.1708 0.2131 0.2741 -0.0074 -0.0048 0.0080
svm SVM - Linear Kernel 0.2588 0.0000 0.2467 0.0920 0.1303 0.0477 0.0879 0.0160
4-3.モデル評価
性能が全然ダメなのは分かっていますがまずは現状のモデルの評価を実施します。
4-3-1.結果の可視化:evaluate_model()
PyCaretの"evaluate_model()"から多種の結果を確認しました。
[IN]
evaluate_model(best_model) #モデルの評価
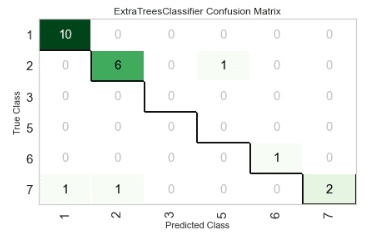
[OUT]【混同行列:Confusion Matrix】
検証データ数が少ない(22個)ため分かりにくいですが、比較的よさそうな結果ではあります。データが相対的に多いType1, 2で間違いがあるのは少し気にはなります。
【重要度分析:Feature Importance】
Tree系では特徴量の重要度を計算できるためそちらも確認します。
相関係数が高かったNa, Mgの重要度は高い
相関係数が高かったけど、Na, Baの重要度は低い
相関係数は低かったけどRI(屈折率)とKの重要度は高い
恐らくSiはガラスの主成分ではあるけど絶対値そのものには意味がないため重要度が低いと思われるー>比率にした場合は不明
総じて、重要度からType判定は難しい

4-3-2.モデルの解釈:interpret_model()
解釈性を高めるためにPyCaretにあるSHAPの機能で可視化しました。正直SHAPの理解は結構難しいので、こんなもんだくらいで終わります。
[IN]
interpret_model(best_model) #モデルの解釈
interpret_model(best_model, plot='correlation') #相関プロット
interpret_model(best_model, plot='reason') #推論プロット 


4-4.モデルの作成:create_model()
自分が学習したいモデルを作成します。例えば違うタイプのモデルを複数選んでアンサンブル(各モデルで予想して多数決)させることも可能です。
今回は最高性能ExtraTreeだけ選択しました。
KFoldによる平均値の結果はcompare_models()の結果と同じ
Fold1だけ他と比較して精度、再現率、適合率共に高い値となっています。つまり分割したデータの中でたまたま性能が良いデータセットに当たった(データ数が少ないクラスが無いなど)可能性があります。
[IN]
extree = create_model('et') #Extra Trees Classifier
print(extree)
# knn = create_model('knn') #K Neighbors Classifier
# tuned_extree = tune_model(extree) #Extra Trees Classifierのチューニング
# lightgbm = create_model('lightgbm') #Light Gradient Boosting Machine
# lda = create_model('lda') #Linear Discriminant Analysis[OUT]
ExtraTreesClassifier(bootstrap=False, ccp_alpha=0.0, class_weight=None,
criterion='gini', max_depth=None, max_features='auto',
max_leaf_nodes=None, max_samples=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=100, n_jobs=-1,
oob_score=False, random_state=123, verbose=0,
warm_start=False)
4-5.ハイパーパラメータ調整:tune_model()
ハイパーパラメータの自動調整は”tune_model()”となります。前より性能が落ちたので、今回はこの結果は使用しません。
[IN]
tuned_extree = tune_model(extree) #ハイパーパラメータのチューニング
tuned_extree[OUT]
ExtraTreesClassifier(bootstrap=False, ccp_alpha=0.0, class_weight={},
criterion='entropy', max_depth=5, max_features=1.0,
max_leaf_nodes=None, max_samples=None,
min_impurity_decrease=0.0002, min_impurity_split=None,
min_samples_leaf=5, min_samples_split=10,
min_weight_fraction_leaf=0.0, n_estimators=150, n_jobs=-1,
oob_score=False, random_state=123, verbose=0,
warm_start=False)
4-6.データの推論/提出用ファイル作成:predict()
データの推論は"predict_model(<モデルのオブジェクト>, data=<推論用データ>)"です。しかし実行すると下記エラーがでました。原因としてクラス4が存在しないことが影響しているかもしれません。
[Error]
IndexError: index 6 is out of bounds for axis 0 with size 6
Output is truncated. View as a scrollable element or open in a text editor.
Adjust cell output settings...しかしもう一つの手法"model.predict(<data>)"は通ったので、こちらで実行しました。後は規定通りのCSVファイル(1列目id, 2列目推論値、ヘッダー、Index無し)を作成して提出します。
[IN]
y_submit = extree.predict(df_test)
display(y_submit) #提出用ファイル作成
df_submit = pd.DataFrame([df_test.index.values, y_submit]).T
df_submit.to_csv('output/submit.csv', header=False, index=False)
[OUT]
array([2, 2, 1, 1, 1, 1, 1, 2, 1, 6, 1, 3, 7, 2, 5, 1, 2, 5, 2, 7, 2, 2,
2, 1, 2, 2, 7, 1, 5, 1, 2, 1, 1, 1, 1, 1, 2, 6, 2, 2, 2, 1, 2, 1,
1, 1, 1, 2, 1, 1, 2, 2, 2, 2, 2, 5, 7, 2, 1, 1, 7, 1, 5, 1, 1, 2,
7, 1, 1, 7, 7, 1, 7, 2, 1, 5, 7, 2, 6, 1, 7, 5, 5, 7, 2, 1, 7, 2,
1, 2, 2, 7, 1, 1, 6, 6, 7, 1, 1, 2, 7, 2, 2, 3, 1, 1, 2],
dtype=int64)4-7.投稿・結果確認
結果は精度=73%とまずまずの結果です。もう一回り改善できれば、3位くらいにはいけそうです。ただ1・2位の精度と比較すると全くダメなので、更なる改善が必要です。


5.特徴量エンジニアリング
目標精度90%越えする場合、現状からモデル×ハイパーパラメータ調整(Optunaなど)の改善ではほぼ無理であり特徴量エンジニアリングが重要と考えられます。
ここでは何パターンか試してみてよい性能が得られるか検討しました。
5-1.Case1 交互作用特徴量:PolynomialFeatures
特徴量自身のべき乗と各特徴量同士の掛け算をすることで次元同士の組み合わせを考慮した特徴量を作成しました。次元数は下記の通りです。
$$
元の特徴量 :9+それらの2乗 :9+2つの組み合わせ \frac{9\times8}{2}=54
$$
[IN]
from sklearn.preprocessing import PolynomialFeatures
df_train_Poly = df_train.copy()
df_train_Poly = df_train_Poly.drop('Type', axis=1)
df_train_Poly_2dim = PolynomialFeatures(degree=2, include_bias=False).fit_transform(df_train_Poly)
#PolynomialFeaturesのカラム作成
columns_origin = df_train.columns
columns_Poly_2dim = PolynomialFeatures(degree=2, include_bias=False).fit(df_train.drop('Type', axis=1)).get_feature_names(df_train.drop('Type', axis=1).columns)
df_train_Poly_2dim = pd.DataFrame(df_train_Poly_2dim, columns=columns_Poly_2dim)
_dfType_resetIdx = df_train['Type'].reset_index(drop=True)
df_train_Poly_2dim = pd.concat([df_train_Poly_2dim, _dfType_resetIdx], axis=1)
df_train_Poly_2dim
[OUT]
多次元で実行した結果は下記の通りです。結果として性能が低下しました。おそらくデータ数が少ないのに特徴量を作成しすぎて次元の呪い (Curse of dimensionality)による過学習を起こしている可能性があります。
また一部の特徴量の交互作用がノイズとなり、モデルの性能を低下させる可能性があります。
[IN]
exp2 = setup(df_train_Poly_2dim,
target='Type', #目的変数
session_id=123, #乱数シード
silent=True, #実行時のログを表示
train_size=0.80, #学習データの割合
log_experiment=True, #mlflowにログを残す
use_gpu=True, #GPUを使う
# fix_imbalance=True, #不均衡データの調整
fold=5, #交差検証の分割数
)
best_model = compare_models() #モデルの比較
lgb = create_model('lightgbm') #Light Gradient Boosting Machine[OUT]
LGBMClassifier(boosting_type='gbdt', class_weight=None, colsample_bytree=1.0,
device='gpu', importance_type='split', learning_rate=0.1,
max_depth=-1, min_child_samples=20, min_child_weight=0.001,
min_split_gain=0.0, n_estimators=100, n_jobs=-1, num_leaves=31,
objective=None, random_state=123, reg_alpha=0.0, reg_lambda=0.0,
silent='warn', subsample=1.0, subsample_for_bin=200000,
subsample_freq=0)

5-2.Case2:比率の特徴量をたくさんつくる
交互作用特徴量と近いですが、下記特徴量を追加してみました。
化学成分の比率: 入力された化学成分のペアごとに、一方の化学成分の量をもう一方の化学成分の量で割った値を計算します。しかし、0で割ると無限大になるため、割る値が0の場合はnp.nanに置き換えています。この操作により、特定の化学成分間の比率がどの程度影響するかを探ります。
総アルカリ金属量と総アルカリ土類金属量: アルカリ金属('Na'と'K')の総量とアルカリ土類金属('Mg'、'Ca'、'Ba')の総量を計算しています。これはガラスの特性に対してこれらの元素の総量が影響を与えるという化学的知識に基づいています。
屈折率と化学成分の相関: 'RI'(屈折率)と各化学成分の値の積を計算しています。これにより、屈折率がガラスのタイプを決定するのにどの程度寄与するかを探ります。
[IN]
def create_features(df):
df = df.copy()
# 化学成分のペアを作成
elements = ['Na', 'Mg', 'Al', 'Si', 'K', 'Ca', 'Ba', 'Fe']
pairs = [(i, j) for i in elements for j in elements if i != j]
# 化学成分の比率を計算
for i, j in pairs:
df[f'Ratio_{i}_{j}'] = df[i] / df[j].replace(0, np.nan) #0で割るとinfになるので 、0をnanに置換しておく
df.fillna(0, inplace=True) # nanを0に置換
# df.dropna(axis=1, inplace=True) # nanがある列を削除
# 総アルカリ金属量を計算
df['AlkaliMetals'] = df['Na'] + df['K']
# 総アルカリ土類金属量を計算
df['AlkalineEarthMetals'] = df['Mg'] + df['Ca'] + df['Ba']
# 屈折率と化学成分の相関を計算
for element in elements:
df[f'RIInteraction_{element}'] = df['RI'] * df[element]
return df
dfTrain_features = create_features(df_train)
dfTrain_features
[OUT]
交互作用特徴量と同様に次元数増加による性能が低下が確認されます。
[IN]
exp = setup(dfTrain_features,
target='Type', #目的変数
session_id=123, #乱数シード
silent=True, #実行時のログを表示
train_size=0.80, #学習データの割合
log_experiment=True, #mlflowにログを残す
use_gpu=True, #GPUを使う
# fix_imbalance=True, #不均衡データの調整
fold=5, #交差検証の分割数
)
best_model = compare_models() #モデルの比較
et = create_model('et') #Extra Trees Classifier
et
[OUT]
ExtraTreesClassifier(bootstrap=False, ccp_alpha=0.0, class_weight=None,
criterion='gini', max_depth=None, max_features='auto',
max_leaf_nodes=None, max_samples=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=100, n_jobs=-1,
oob_score=False, random_state=123, verbose=0,
warm_start=False)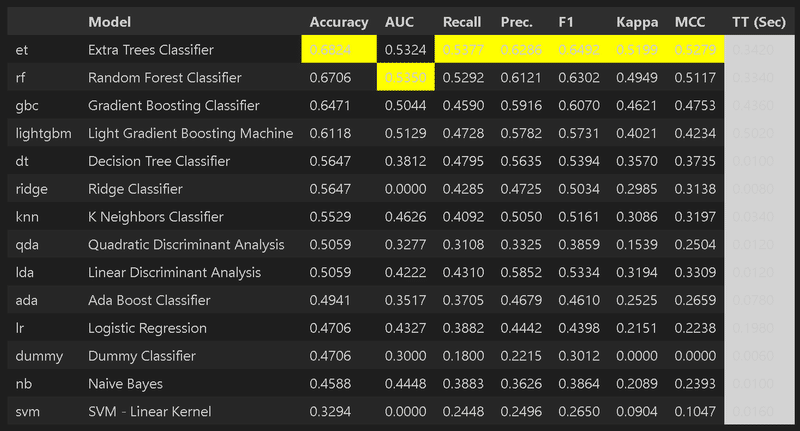

5-3.Case3:Siの比率で計算
Siと各組成の比で性能が向上するか確認してみました。こちらもダメでした。
[IN]
def create_features_small(df):
df = df.copy()
# ガラスの主要な成分はSiであるため、他の成分とSiの比率を計算
elements = ['Na', 'Mg', 'Al', 'K', 'Ca', 'Ba', 'Fe']
for element in elements:
df[f'Ratio_{element}_Si'] = df[element] / df['Si']
# アルカリ金属とアルカリ土類金属の合計のSiに対する比率を計算
df['AlkaliMetals_Si'] = (df['Na'] + df['K']) / df['Si']
df['AlkalineEarthMetals_Si'] = (df['Mg'] + df['Ca'] + df['Ba']) / df['Si']
return df
dfTrain_features_small = create_features_small(df_train)
dfTrain_features_small
exp = setup(dfTrain_features_small,
target='Type', #目的変数
session_id=123, #乱数シード
silent=True, #実行時のログを表示
train_size=0.80, #学習データの割合
log_experiment=True, #mlflowにログを残す
use_gpu=True, #GPUを使う
# fix_imbalance=True, #不均衡データの調整
fold=5, #交差検証の分割数
)
best_model = compare_models() #モデルの比較
et = create_model('et') #Extra Trees Classifier
et
[OUT]
ExtraTreesClassifier(bootstrap=False, ccp_alpha=0.0, class_weight=None,
criterion='gini', max_depth=None, max_features='auto',
max_leaf_nodes=None, max_samples=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=100, n_jobs=-1,
oob_score=False, random_state=123, verbose=0,
warm_start=False)


5-4.Case4:相関関係が高い原子の相互作用
相関関係が高かったNa, Mg, Al(Baは除く)と量が多いCaの相互作用を確認しました。
[IN]
import itertools
def create_ratio_features(df):
df = df.copy()
# 指定された化学元素
elements = ['Na', 'Mg', 'Al', 'Ca']
# 化学元素のペアを作成
pairs = list(itertools.combinations(elements, 2))
# 指定された化学元素の比率を計算
for i, j in pairs:
df[f'Ratio_{i}_{j}'] = df[i] / df[j].replace(0, np.nan) #0で割るとinfになるので 、0をnanに置換しておく
df.fillna(0, inplace=True) # nanを0に置換
return df
df_train_ratio = create_ratio_features(df_train)
df_train_ratio
[OUT]
[IN]
exp = setup(df_train_ratio,
target='Type', #目的変数
session_id=123, #乱数シード
silent=True, #実行時のログを表示
train_size=0.80, #学習データの割合
log_experiment=True, #mlflowにログを残す
use_gpu=True, #GPUを使う
# fix_imbalance=True, #不均衡データの調整
fold=5, #交差検証の分割数
)
best_model = compare_models() #モデルの比較
et = create_model('et') #Extra Trees Classifier
et
[OUT]
ExtraTreesClassifier(bootstrap=False, ccp_alpha=0.0, class_weight=None,
criterion='gini', max_depth=None, max_features='auto',
max_leaf_nodes=None, max_samples=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=100, n_jobs=-1,
oob_score=False, random_state=123, verbose=0,
warm_start=False)

5-5.Case5:原子at%に変換
数値の単位が不明ですが、wt%と仮定してat%に変換してみました。
[IN]
def convert_wt2atom(df):
df_output = df.copy()
mol_weights = {'Na': 22.9898, 'Mg': 24.305, 'Al': 26.9815, 'Si': 28.0855,
'K': 39.0983, 'Ca': 40.078, 'Ba': 137.327, 'Fe': 55.845}
for elem in mol_weights.keys():
df_output[f'{elem}_mol'] = df_output[elem] / mol_weights[elem]
cols_atom_origin = ['Na', 'Mg', 'Al', 'Si', 'K', 'Ca', 'Ba', 'Fe']
df_output = df_output.drop(cols_atom_origin, axis=1)
return df_output
df_train_atom = convert_wt2atom(df_train)
df_train_atom
[OUT]

改善しそうな兆しはあったのですが、性能は変化しませんでした。

【補足:重量+原子量】
作成したat%に重量情報?wt%も追加して学習させました。Extreeの精度は落ちましたがクラスタリング手法のKNeighborsClassifierが上に来ました。
[IN]
df_train_atom = convert_wt2atom(df_train)
df_train_addatom = pd.concat([df_train, df_train_atom.drop(columns=['Type', 'RI'])], axis=1)
exp = setup(df_train_addatom,
target='Type', #目的変数
session_id=123, #乱数シード
silent=True, #実行時のログを表示
train_size=0.80, #学習データの割合
log_experiment=True, #mlflowにログを残す
use_gpu=True, #GPUを使う
# fix_imbalance=True, #不均衡データの調整
fold=5, #交差検証の分割数
)
best_model = compare_models() #モデルの比較
knn = create_model('knn') #K Neighbors Classifier
knn
[OUT]
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=-1, n_neighbors=5, p=2,
weights='uniform')

6.まとめ
シンプルな問題のため簡単にいけると思ったのですが、想像以上に難しいです。特にデータが少ない+ガラスのドメイン知識がなく特徴量作成が的を射てないこともあり精度が上がりきらなかったです。
Optuna、学習:テストの比率、乱数値のシードを変えることで微調整できると思いますが、どう考えてもトップ1・2位は届かない+特徴量エンジニアリングのアイデアが尽きたため今回はここで終わりにします。
アイデアが出るか、能力が上がって対応できるようになったら”その2”で続き書きたいです。
参考資料
あとがき
AutoMLに頼りっぱなしになってきてる・・・
この記事が気に入ったらサポートをしてみませんか?