<学習シリーズ>機械学習モデルの検証:モデルの適用範囲(外挿)を確認

1.概要
本記事は”学習シリーズ”として自分の勉強備忘録用になります。
経緯としては作成した機械学習モデル(XGBoost)が学習していないデータレンジでの出力の挙動が理屈と合わない事象が発生したため、外挿性に関して確認しようと思った次第です。
1-1.内挿/外挿とは
内挿と外挿の定義は下記の通りです。
【用語の定義】
内挿:実験データ内(データのMIN~MAX間)で未知の説明変数Xから予想
外挿:実験や実測データにおいてデータ範囲外を未知の値を予想すること
研究や設計で反応や物理現象をモデル化するのは「既知のデータから未知のデータを予測したい」ためであり、未知データの推測は重要となります。
機械学習では内挿(データ範囲内において未知の値を予想)することは得意ですが、外挿が上手くいくのかを検証したいと思います。
1-2.モデルの適用範囲:AD
モデルの適用領域 (Applicability Domain, AD)とは「機械学習モデルが本来の性能を発揮できるデータ領域」です。
ADは内挿・外挿に限らずデータが使用できる(信頼できる推定値)範囲を示すものであり、本記事では概念のみ参考資料を紹介します。
1-3.サンプルデータ:Arrenius Plot
サンプルデータとしてアレニウスの式(Arrhenius Equation)を使って適当なデータを作成します。
アレニウスの式は「温度と反応速度の経験則的な関係式」であり数式は下記の通りです。また実験で計測できるのはkとTのため両辺に対数をとり切片と傾きから$${k_{0}}$$とEを求めます。この時のプロットをアレニウスプロットと呼びます。
$$
k=k_{0}\exp(-\frac{E}{RT})
$$
$$
アレニウスプロット: lnk = lnk_{0}-\frac{E}{R}\frac{1}{T}
$$
$${k_{0}}$$:頻度因子、E:活性化値エネルギー[J/mol]、T:絶対温度[K]、R:気体定数[J/mol/K]
[IN]
import sympy as sp
sp.init_printing()
k, k0, E, R, T = sp.symbols('k k0 E R T')
eq = sp.Eq(k, k0*sp.exp(-E/(R*T)))
eq_ln = sp.Eq(sp.ln(eq.lhs), sp.ln(eq.rhs).expand(force=True))
display(eq, eq_ln)
[OUT]
サンプルデータは下記の手順で作成しました。
頻度因子$${k_{0}}$$と活性化エネルギーEに適当な数値を入れる(EはkJ単位で記載されることが多いため$${10^3}$$区切りで記載)。
アレニウスの式から温度150~250℃での理論反応速度kを算出
(実際の実験データはばらつきがあるため)実データを模擬して上記で求めたkに適当な乱数値を加える(約1%ほどばらつくように調整)。
学習用データとして180~220℃のみ使用するため、このデータを抽出
プロット
[IN]
import glob
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import japanize_matplotlib
import sympy as sp
[OUT]
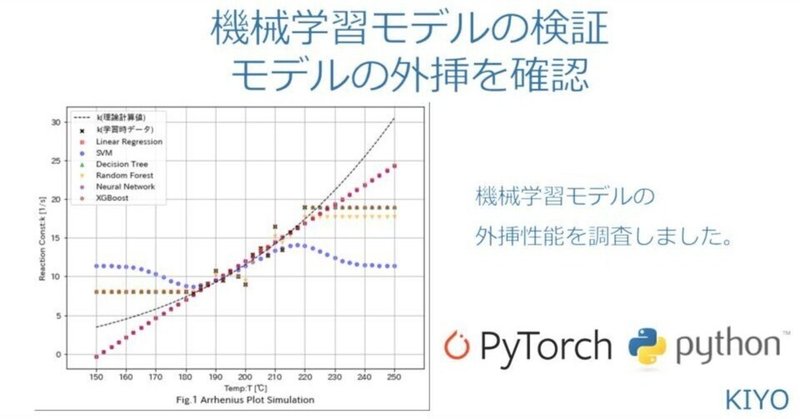
150~250℃のデータの内、180~220℃のデータで学習させて後に外挿で理論値に合うか確認します(赤×のデータから学習させて外挿したときに黒線の上に乗るか確認)。
なお見てわかる通りもともとは対数で線形になるようなプロットのため、通常の単回帰分析だと精度が低くなる条件になっております。
2.機械学習モデルの作成
外挿するための機械学習モデルを作成していきます。学習後の結果は次章で紹介します。
2-1.一般的な機械学習モデル:scikit-learn
機械学習モデルのオープンソースであるscikit-learnを用いて複数個の教師あり学習モデルを使用しました。
線形回帰(単回帰分析):直線のため最もシンプルであり直感的にわかりやすいが複雑なモデルには適用できない
サポートベクターマシン:複雑なモデルにも対応できるがハイパーパラメータの調整が必要
決定木・ランダムフォレスト:比較的性能が高いが過学習しやすい
2-2.XGBoost
勾配ブースティング決定木(GBD)のXGBoostを使用しました。後述の通り、高性能な機械学習モデルですが基本的には決定木のため決定木と同じような傾向が出ます。
2-3.全結合:NN
多層パーセプトロンのニューラルネットワークNNを作成しました。なおNNはscikit-learnと同じAPIで作成できないため個別で実装・学習しました。
ノードのレイヤ数は適当に設定
学習精度を上げるためにlr=0.05にしてepoch=10,000とした
[IN]
#Deep Learning
import torch
import torch.nn as nn #パラメータをもつレイヤ関数
import torch.nn.functional as F #パラメータをもたないレイヤ関数
from tqdm import tqdm
class Net(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(1, 16)
self.fc2 = nn.Linear(16, 16)
self.fc3 = nn.Linear(16, 1)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
torch.manual_seed(123)
epochs = 10000
lr=0.05
net = Net()
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
criterion = nn.MSELoss()
X_train = torch.tensor(df_data['T_deg'].values, dtype=torch.float32).view(-1, 1).to(device)
Y_train = torch.tensor(df_data['k_noise'].values, dtype=torch.float32).view(-1, 1).to(device)
net= net.to(device) # モデルをGPUへ転送
net.train()
for epoch in tqdm(range(epochs)):
optimizer.zero_grad() # 勾配の初期化
output = net(X_train) # モデルの出力
loss = criterion(output, Y_train) # 損失の計算
loss.backward()
optimizer.step()
if epoch%100 == 0:
print('epoch: {}, loss: {}'.format(epoch, loss.item()))
net.eval()
[OUT]
1%| | 56/10000 [00:00<00:20, 495.59it/s]epoch: 0, loss: 307.5443420410156
epoch: 100, loss: 6.755832672119141
4%|▍ | 399/10000 [00:00<00:11, 867.15it/s]epoch: 200, loss: 6.614007949829102
epoch: 300, loss: 6.418054103851318
・・・・
98%|█████████▊| 9828/10000 [00:10<00:00, 948.85it/s]epoch: 9700, loss: 1.5472378730773926
epoch: 9800, loss: 1.5370984077453613
100%|██████████| 10000/10000 [00:10<00:00, 953.74it/s]epoch: 9900, loss: 1.5345027446746826
Net(
(fc1): Linear(in_features=1, out_features=16, bias=True)
(fc2): Linear(in_features=16, out_features=16, bias=True)
(fc3): Linear(in_features=16, out_features=1, bias=True)
)
3.モデルの適用性確認:外挿
3-1.モデルの学習・推論
前述の通り「180~220℃」のみを学習に使用して、「150~250℃」のデータを推論したうえで外挿の精度を確認しました。
[IN]
x_train = df_data[['T_deg']].values #180<=T<=220℃の温度データ
y_train = df_data['k_noise'].values #ノイズを加えた反応速度定数k
x_test = df[['T_deg']].values #全温度データ
y_test = df['k'].values #理論計算値の反応速度定数k
#線形回帰
from sklearn.linear_model import LinearRegression
linear = LinearRegression()
linear.fit(x_train, y_train)
y_pred1 = linear.predict(T_deg[:, np.newaxis])
print(f'外挿Score(Linear): {linear.score(x_test, y_test):.3f}, 内挿Score(Linear): {linear.score(x_train, y_train):.3f}')
#ロジスティック回帰(分類のみ )
# https://www.statology.org/valueerror-unknown-label-type-continuous/
#SVM:サポートベクターマシン
from sklearn.svm import SVR
SVM = SVR(C=10) #回帰のSVM
SVM.fit(x_train, y_train)
y_pred2 = SVM.predict(T_deg[:, np.newaxis])
print(f'外挿Score(SVM): {SVM.score(x_test, y_test):.3f}, 内挿Score(SVM): {SVM.score(x_train, y_train):.3f}')
#決定木
from sklearn.tree import DecisionTreeRegressor
tree = DecisionTreeRegressor()
tree.fit(x_train, y_train)
y_pred3 = tree.predict(T_deg[:, np.newaxis])
print(f'外挿Score(DecisionTree): {tree.score(x_test, y_test):.3f}, 内挿Score(DecisionTree): {tree.score(x_train, y_train):.3f}')
#ランダムフォレスト
from sklearn.ensemble import RandomForestRegressor
randomtree = RandomForestRegressor()
randomtree.fit(x_train, y_train)
y_pred4 = randomtree.predict(T_deg[:, np.newaxis])
print(f'外挿Score(RandomForest): {randomtree.score(x_test, y_test):.3f}, 内挿Score(RandomForest): {randomtree.score(x_train, y_train):.3f}')
#ニューラルネットワーク
from sklearn.metrics import r2_score
y_pred5 = net(torch.tensor(T_deg, dtype=torch.float32).view(-1, 1).to(device)).detach().cpu().numpy()
mask = df['T_deg'].apply(lambda x: x>=180 and x<=220) #180<=T<=220℃のデータを抽出用
print(f'外挿Score(NeuralNetwork): {r2_score(y_test, y_pred5):.3f}, 内挿Score(NeuralNetwork): {r2_score(y_train, y_pred5[mask]):.3f}')
#XGBoost
import xgboost
xgb = xgboost.XGBRegressor()
xgb.fit(x_train, y_train)
y_pred6 = xgb.predict(T_deg[:, np.newaxis])
print(f'外挿Score(XGBoost): {xgb.score(x_test, y_test):.3f}, 内挿Score(XGBoost): {xgb.score(x_train, y_train):.3f}')
[OUT]
外挿Score(Linear): 0.919, 内挿Score(Linear): 0.856
外挿Score(SVM): 0.226, 内挿Score(SVM): 0.875
外挿Score(DecisionTree): 0.755, 内挿Score(DecisionTree): 1.000
外挿Score(RandomForest): 0.703, 内挿Score(RandomForest): 0.965
外挿Score(NeuralNetwork): 0.917, 内挿Score(NeuralNetwork): 0.856
外挿Score(XGBoost): 0.755, 内挿Score(XGBoost): 1.0003-2.可視化:Matplotlib
結果をプロットして可視化しました。
[IN]
#プロット
fig = plt.figure(figsize=(12, 8), facecolor='white')
ax = fig.add_subplot(111)
ax.plot(df['T_deg'], df['k'], label='k(理論計算値)',
linewidth=1, linestyle='dashed',color='black')
ax.scatter(df_data[['T_deg']], df_data['k_noise'], label='k(学習時データ)',
marker='x', color='black', s=50)
ax.scatter(T_deg, y_pred1, label='Linear Regression',
marker='s', color='red', s=15, alpha=0.5)
ax.scatter(T_deg, y_pred2, label='SVM',
marker='o', color='blue', s=15, alpha=0.5)
ax.scatter(T_deg, y_pred3, label='Decision Tree',
marker='^', color='green', s=15, alpha=0.5)
ax.scatter(T_deg, y_pred4, label='Random Forest',
marker='v', color='orange', s=15, alpha=0.5)
ax.scatter(T_deg, y_pred5, label='Neural Network',
marker='+', color='purple', s=15, alpha=0.5)
ax.scatter(T_deg, y_pred6, label='XGBoost',
marker='h', color='brown', s=15, alpha=0.5)
ax.set(xlabel='Temp:T [℃]', ylabel='Reaction Const:k [1/s]',
xticks=np.linspace(150, 250, 11), xlim=(140, 260))
plt.title('Fig.1 Arrhenius Plot Simulation', loc='center', y=-0.15)
plt.legend()
plt.grid()
plt.show()
[OUT]
3-3.考察
結論としては下記の通りです。
機械学習は万能ではない。
外挿(or AD外)の精度は低くなる可能性が高い
基本的には外挿せず、データを追加してモデルには内挿させる
外挿するなら解釈しやすいモデル(線形モデルなど)の方が信頼性が高い
詳細な結果は下記の通りです。
今回のモデル群では「高精度で外挿(黒線の上にプロットが乗る)できたモデルはない」結果となりました。
Tree系(決定木・ランダムフォレスト・GBD)はデータ範囲内の精度は抜群(ほぼ100%)だが、外挿時の傾向はいい加減である。これはモデルの特性上、分岐条件はデータ範囲外を予測できないためと思われる。
SVMはハイパーパラメータ調整はしていないが、表現力が高いためおそらく調整してもうまく外挿はできなさそう。
今回ニューラルネットワークはほぼ線形と同じ形になった。DropoutやBatchNormalizationの手法があるとはいえ表現力の高いモデルのため外挿の精度は期待しない方がよい
所感としては「解釈性が難しくなるため特に複雑なモデルに関しては、機械学習を使用しなくてよい場面では使用しない方がよい」と思います。
参考として、下記記事では「結論として線形モデルの方がテストデータでは性能がよいし解釈性(interpretability)も高い。線形モデルと複雑なモデルを比較すると内挿(interpolation)では複雑なモデルの性能は良いが、外挿(extrapolation)になると学習時でも差はないしテストデータだと線形モデルの方がよい」という結論になっています。
4.モデルの適用性確認:内挿
「機械学習は内挿に強い」と言いましたが、とびとびのデータではどうなるかも確認しました。結論としては「とびとびのデータだとデータ周辺は強いが外れたエリアは外挿と同様に精度は落ちる」です。
4-1.サンプルデータ作成
サンプルデータとして同様にArrenius Plotでデータを作成しました。前章と異なる点は「学習データは連続値ではなく離散的なデータ群として取得」することにしました。全体の温度幅は150-360℃ですが、学習用デーは温度幅30℃で3種類のデータ群を作成しました。
[IN]
import glob
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import japanize_matplotlib
import sympy as sp
np.random.seed(0) #乱数のシードを固定
class HorizontalDisplay:
def __init__(self, *args):
self.args = args
def _repr_html_(self):
template = '<div style="float: left; padding: 10px;">{0}</div>'
return ''.join(template.format(arg._repr_html_()) for arg in self.args)
def Arrhenius(T_deg):
T = T_deg + 273.15 #絶対温度 [K]に変換
# k0 = 13e3 #頻度因子
# E = 28e3 #活性化エネルギー [J/mol]
k0 = 3.0e5 #頻度因子
E = 40e3 #活性化エネルギー [J/mol]
R = 8.314 #気体定数 [J/mol/K]
return k0 * np.exp(-E/(R*T))
T_deg = np.linspace(150, 360, 101)
k = Arrhenius(T_deg) #反応速度定数
k_noise = k + np.random.randn(len(k)) #ノイズを加える
df = pd.DataFrame({'T_deg': T_deg, 'k': k, 'k_noise': k_noise})
#3つのクラスターに分類して 、カテゴリデータ追加
df['class'] = 0 #カテゴリ以外のデータはクラス0
range1_T, range2_T, range3_T = (180, 210), (240, 270), (300, 330)
#各温度群にクラスラベルを追加
mask1 = df['T_deg'].apply(lambda x: x>=range1_T[0] and x<=range1_T[1])
mask2 = df['T_deg'].apply(lambda x: x>=range2_T[0] and x<=range2_T[1])
mask3 = df['T_deg'].apply(lambda x: x>=range3_T[0] and x<=range3_T[1])
#SettingWithCopyWarningを回避するために 、locを使う
df.loc[mask1, 'class'] = 1
df.loc[mask2, 'class'] = 2
df.loc[mask3, 'class'] = 3
df_data1 = df[df['T_deg'].apply(lambda x: x>=range1_T[0] and x<=range1_T[1])]
df_data2 = df[df['T_deg'].apply(lambda x: x>=range2_T[0] and x<=range2_T[1])]
df_data3 = df[df['T_deg'].apply(lambda x: x>=range3_T[0] and x<=range3_T[1])]
display(HorizontalDisplay(df[df['class']==0], df[df['class']==1], df[df['class']==2], df[df['class']==3]))
df_data = pd.concat([df_data1, df_data2, df_data3], axis=0)
#Plot
fig = plt.figure(figsize=(12, 8), facecolor='white')
ax = fig.add_subplot(111)
ax.plot(df['T_deg'], df['k'], label='k(理論計算値)',
linewidth=1, linestyle='dashed',color='black')
ax.scatter(df_data1['T_deg'], df_data1['k_noise'], label='データ1',
marker='x', color='red', s=50)
ax.scatter(df_data2['T_deg'], df_data2['k_noise'], label='データ2',
marker='o', color='blue', s=50)
ax.scatter(df_data3['T_deg'], df_data3['k_noise'], label='データ3',
marker='^', color='green', s=50)
ax.set(xlabel='Temp:T [℃]', ylabel='Reaction Const:k [1/s]',
xticks=np.linspace(150, 360, 22), xlim=(140, 370))
plt.title('Fig.1 Arrhenius Plot Simulation', loc='center', y=-0.15)
plt.legend(prop={'size': 16}, loc='upper left')
plt.grid()
plt.show()
[OUT]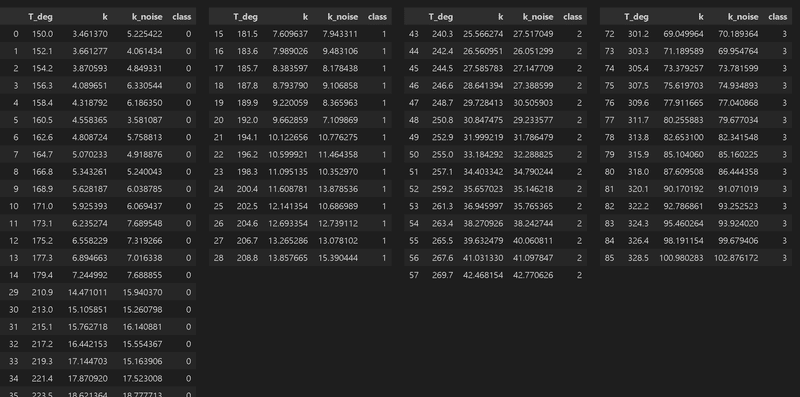

全結合(NN)はsklearnを使用していないため個別で学習させます。
[IN]
#Deep Learning
import torch
import torch.nn as nn #パラメータをもつレイヤ関数
import torch.nn.functional as F #パラメータをもたないレイヤ関数
from tqdm import tqdm
class Net(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(1, 16)
self.fc2 = nn.Linear(16, 16)
self.fc3 = nn.Linear(16, 1)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
torch.manual_seed(123)
epochs = 10000
lr=0.05
net = Net()
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
criterion = nn.MSELoss()
X_train = torch.tensor(df_data[['T_deg']].values, dtype=torch.float32).view(-1, 1).to(device)
Y_train = torch.tensor(df_data['k_noise'].values, dtype=torch.float32).view(-1, 1).to(device)
net= net.to(device) # モデルをGPUへ転送
net.train()
for epoch in tqdm(range(epochs)):
optimizer.zero_grad() # 勾配の初期化
output = net(X_train) # モデルの出力
loss = criterion(output, Y_train) # 損失の計算
loss.backward()
optimizer.step()
if epoch%100 == 0:
print('epoch: {}, loss: {}'.format(epoch, loss.item()))
net.eval()
[OUT]4-2.学習・推論・可視化
学習、推論、データの可視化をまとめて実施しました。
[IN]
x_train = df_data[['T_deg']].values #クラスター1-3の温度データ
y_train = df_data['k_noise'].values #ノイズを加えた反応速度定数k
x_test = df[['T_deg']].values #全温度データ
y_test = df['k'].values #理論計算値の反応速度定数k
print(f'データ数 学習時: {len(x_train)}, テスト時: {len(x_test)}')
print(f'温度域 学習時: {x_train.min():.1f}~{x_train.max():.1f}℃, テスト時: {x_test.min():.1f}~{x_test.max():.1f}℃')
#線形回帰
from sklearn.linear_model import LinearRegression
linear = LinearRegression()
linear.fit(x_train, y_train)
y_pred1 = linear.predict(x_test)
print(f'Score 全データ(Linear): {linear.score(x_test, y_test):.3f}, 学習(Linear): {linear.score(x_train, y_train):.3f}')
#ロジスティック回帰(分類のみ )
# https://www.statology.org/valueerror-unknown-label-type-continuous/
#SVM:サポートベクターマシン
from sklearn.svm import SVR
SVM = SVR() #回帰のSVM
SVM.fit(x_train, y_train)
y_pred2 = SVM.predict(x_test)
print(f'Score 全データ(SVM): {SVM.score(x_test, y_test):.3f}, 学習(SVM): {SVM.score(x_train, y_train):.3f}')
#決定木
from sklearn.tree import DecisionTreeRegressor
tree = DecisionTreeRegressor()
tree.fit(x_train, y_train)
y_pred3 = tree.predict(x_test)
print(f'Score 全データ(DecisionTree): {tree.score(x_test, y_test):.3f}, 学習(DecisionTree): {tree.score(x_train, y_train):.3f}')
#ランダムフォレスト
from sklearn.ensemble import RandomForestRegressor
randomtree = RandomForestRegressor()
randomtree.fit(x_train, y_train)
y_pred4 = randomtree.predict(x_test)
print(f'Score 全データ(RandomForest): {randomtree.score(x_test, y_test):.3f}, 学習(RandomForest): {randomtree.score(x_train, y_train):.3f}')
#ニューラルネットワーク
from sklearn.metrics import r2_score
y_pred5_train = net(torch.tensor(x_train, dtype=torch.float32).view(-1, 1).to(device)).detach().cpu().numpy()
y_pred5 = net(torch.tensor(x_test, dtype=torch.float32).view(-1, 1).to(device)).detach().cpu().numpy()
print(f'Score 全データ(NeuralNetwork): {r2_score(y_test, y_pred5):.3f}, 学習(NeuralNetwork): {r2_score(y_train, y_pred5_train):.3f}')
#XGBoost
import xgboost
xgb = xgboost.XGBRegressor()
xgb.fit(x_train, y_train)
y_pred6 = xgb.predict(x_test)
print(f'Score 全データ(XGBoost): {xgb.score(x_test, y_test):.3f}, 学習(XGBoost): {xgb.score(x_train, y_train):.3f}')
#プロット
fig = plt.figure(figsize=(12, 8), facecolor='white')
ax = fig.add_subplot(111)
#データのプロット ax.plot(df['T_deg'], df['k'], label='k(理論計算値)',
linewidth=1, linestyle='dashed',color='black')
ax.scatter(df_data1['T_deg'], df_data1['k_noise'], label='データ1',
marker='x', color='red', s=50)
ax.scatter(df_data2['T_deg'], df_data2['k_noise'], label='データ2',
marker='x', color='blue', s=50)
ax.scatter(df_data3['T_deg'], df_data3['k_noise'], label='データ3',
marker='x', color='green', s=50)
#機械学習の推論値のプロット ax.scatter(x_test, y_pred1, label='Linear Regression',
marker='s', color='red', s=20, alpha=0.3)
ax.scatter(x_test, y_pred2, label='SVM',
marker='o', color='blue', s=20, alpha=0.3)
ax.scatter(x_test, y_pred3, label='Decision Tree',
marker='^', color='green', s=20, alpha=0.3)
ax.scatter(x_test, y_pred4, label='Random Forest',
marker='v', color='orange', s=20, alpha=0.3)
ax.scatter(x_test, y_pred5, label='Neural Network',
marker='+', color='purple', s=20, alpha=0.3)
ax.scatter(x_test, y_pred6, label='XGBoost',
marker='h', color='brown', s=20, alpha=0.3)
ax.set(xlabel='Temp:T [℃]', ylabel='Reaction Const:k [1/s]',
xticks=np.linspace(150, 360, 22), xlim=(140, 370))
plt.title('Fig.1 Arrhenius Plot Simulation', loc='center', y=-0.15)
plt.legend(prop={'size': 16}, loc='upper left')
plt.grid()
plt.show()
[OUT]
データ数 学習時: 43, テスト時: 101
温度域 学習時: 181.5~328.5℃, テスト時: 150.0~360.0℃
Score 全データ(Linear): 0.880, 学習(Linear): 0.940
Score 全データ(SVM): 0.795, 学習(SVM): 0.985
Score 全データ(DecisionTree): 0.929, 学習(DecisionTree): 1.000
Score 全データ(RandomForest): 0.924, 学習(RandomForest): 1.000
Score 全データ(NeuralNetwork): 0.991, 学習(NeuralNetwork): 0.998
Score 全データ(XGBoost): 0.929, 学習(XGBoost): 1.000
4-3.考察
結論としては下記の通りです。
外挿だけでなく内挿でもデータの適用範囲を間違えると性能はでない。
決定木はモデルの適用範囲内では抜群の性能だが、適用範囲外だとモデルの特性上十分な予想ができない※
線形モデルは性能の有無にかかわらず解釈性は圧倒的に高い
今回のケースでは全結合の汎化性能が高かった。非線形モデルだが、まだ層が浅くノード数も少ないので過学習しなかったためと思われる。
※XGBoost(GBDT)最強!のように言われますが、特性は決定木と同じためデータが足りないと性能がでません。当然学習-テストデータへの分割やクロスバリデーションは実施しますが、それでも将来的に予想したいデータがAD外だった場合は性能がでなくなりますので注意が必要です。
機械学習は内挿・外挿するにしてもデータが重要であり、データの精度だけでなく範囲も重要となります。よって予想したいデータがある場合はその周辺のデータを取得しておかないと結果的には何も予想できない可能性があるため注意が必要です。
参考資料
あとがき
いろいろモデル作る前にこれ気づいておいてよかった。機械学習=万能のイメージが強すぎて、大きなミスをしでかすところだった・・・・
この記事が気に入ったらサポートをしてみませんか?