
SIGNATEコンペの練習2:ソニーグループ合同 データ分析コンペティション(for Recruiting)大気中の汚染物質濃度の予測に挑戦しよう!

1.概要
最近学んだPyCaretの能力検証も含めてコンペに参加してみました。今回はSIGNATEの「【ソニーグループ合同 データ分析コンペティション(for Recruiting)大気中の汚染物質濃度の予測に挑戦しよう!」です。
今回は時間の都合上PyCaretでまともな処理ができるかだけ確認しており、結論として特徴量エンジニアリングなどは全くしていないためスコアは全くダメでした。
2.事前準備:SIGNATE側
2-1.データ概要の確認
データは一般的(専門知識が不要)な情報から特定地域のPM2.5を予想する回帰問題です。
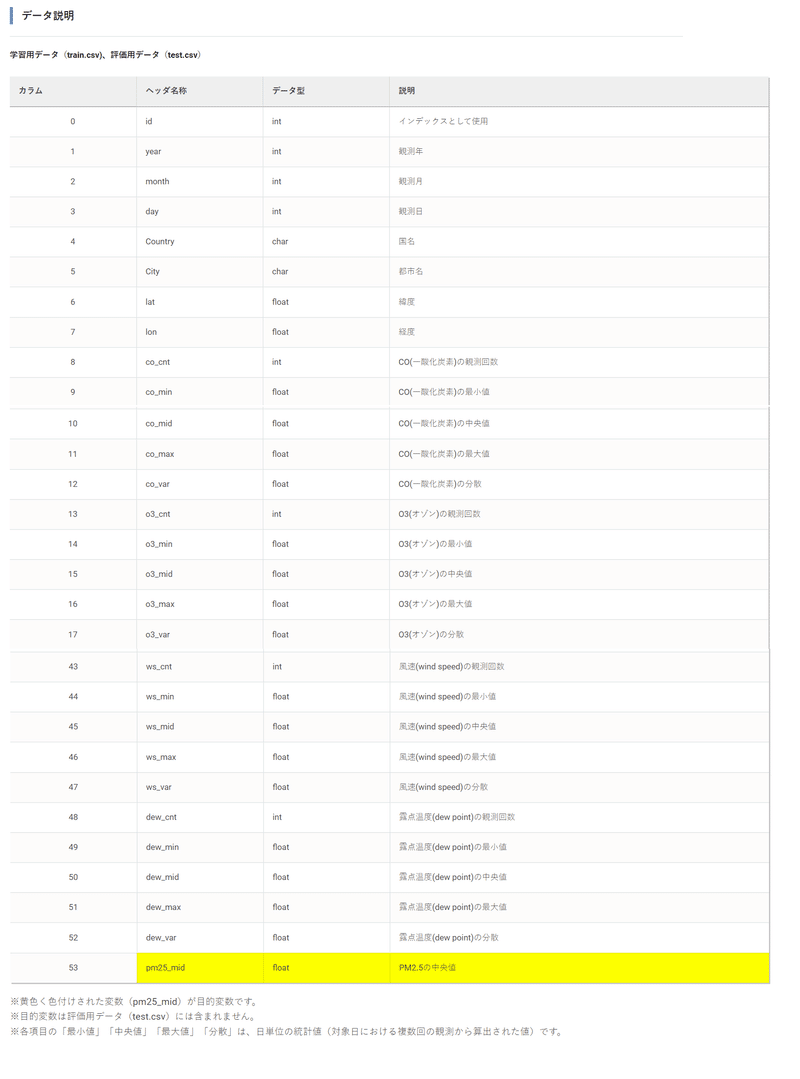
評価指標はRMSEのため一般的な回帰での指標となります。

提出CSVの形はヘッダー無しでindexとラベルの2列とします。

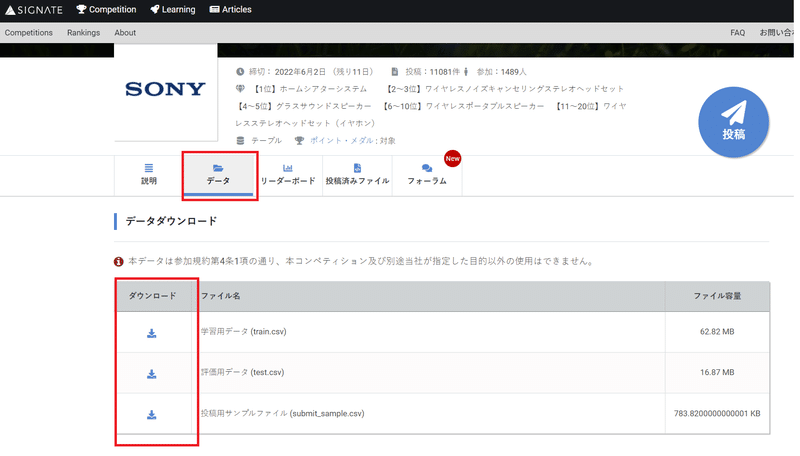
2-2.学習・評価用データのダウンロード
学習・評価用データを下記からダウンロードします。CLIでもDL可能ですがカラムの有無やデータ項目の意味を確認するためHPに移動するので手動ででも問題ないです。
2-3.SIGNATE APIトークンの準備
データ予想後のCSVを提出する時にCLIを使用したいため事前にAPI Token(signate.json)を準備します。
※なおホーム右上の「投稿」を押して下記画面からでも投稿できるため手動で実行するなら本節は不要です。
3.事前準備:Google Colab側
PyCaretを使用するためGoogle Colabを使用します。
3-1.SIGNATE APIトークンの配置/CLI準備
下記手順でAPIトークン(signate.json)を配置しました。※データDLも提出も手動でするなら不要。
[IN]
import os, shutil
from google.colab import drive
drive.mount('/content/drive') #Googleドライブをマウント
path_signate = '/content/drive/MyDrive/11. コンペ/signate.json' #ファイル保管場所
os.chdir('../')#ディレクトリを親ファイルに移動
#親ファイル内のrootフォルダにjsonファイルを移動
path_target = './root/.signate'
if os.path.exists(path_target) != True:
os.mkdir(path_target) #rootフォルダに.signateを作成
# shutil.copy(path_signate, os.path.join(path_target, 'signate.json'))
shutil.copy(path_signate, path_target)
print(f'{path_target}にjsonをコピーしました。')
os.chdir('./content') #起動時の作業ディレクトリに戻る
print(os.getcwd())
!pip install signate3-2.必要なファイルの配置
contentフォルダ(作業dir)にDLしたファイルをアップロードします。
APIトークンを準備した場合は"signate download --competition-id=<id>"を実行すると作業dirにファイルをDLできます。
[IN]
# !signate list #① 投稿可能なコンペティション一覧の取得
!signate download --competition-id=624 #③ コンペティションが提供するファイルのダウンロード3-3.必要ライブラリのインポート
google colabは基本的な環境構築はされておりますが不足分は自分でインポートします。今回はPyCaretに必要な環境構築を実行します。
[IN]
#必要なライブラリのインストール
!pip install pandas-profiling==3.1.0
!pip install pycaret
!pip install shap
#Google Colabでのインタラクティブ化
from pycaret.utils import enable_colab
enable_colab()3-4.記事紹介用:Pandasのdf並列表示
記事用+見やすさのためDataFrameを並列表示できる関数を作成します。
[IN]
from IPython.display import display_html
def display_dfs(dfs, gap=50, justify='center'):
html = ""
for title, df in dfs.items():
df_html = df._repr_html_()
cur_html = f'<div> <h3>{title}</h3> {df_html}</div>'
html += cur_html
html= f"""
<div style="display:flex; gap:{gap}px; justify-content:{justify};">
{html}
</div>
"""
display_html(html, raw=True)4.データ解析
次章以降ではいろいろなパターンを検討しますが、本章ではどのモデルでも必要な処理を記載しました。
4-1.データ確認
データの中身に関しては最低でも下記を確認します。
【データ概要の確認事項】
①統計量
②欠損値の有無
③不要そうなカラムの有無
④ラベルデータの偏り ※カテゴリデータではないため統計量から確認
[IN]
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
df_train = pd.read_csv('train.csv')
df_test = pd.read_csv('test.csv')
df_sample = pd.read_csv('submit_sample.csv', header=None) #カラム無しのためheader=None
print('df_train',df_train.shape, 'df_test', df_test.shape, 'df_sample', df_sample.shape)
display(df_train.head(5)) #提出データの形確認
#データの中身確認
display_dfs( {'df_train': df_train.describe(),
'df_test': df_test.describe()}
, justify='flex-start')
display_dfs( {'欠損値_train':pd.DataFrame(df_train.isnull().sum()),
'欠損値_test': pd.DataFrame(df_test.isnull().sum())}
, justify='flex-start')
df_train['pm25_mid'].value_counts() #ラベルデータの偏り確認
[OUT]
df_train (195941, 54) df_test (53509, 53) df_sample (53509, 2)
0 985
1 123
2 92
Name: charges, dtype: int64【確認結果】
●学習データは19.6万程度あり十分なデータ量がある。
●欠損値は学習・テストデータともに無し
●ほぼ高確率で特徴量の選定が必要
ー>idは学習に不要。
ー>緯度・経度と国・Cityは同じ意味のためどっちかにしてよさそう
ー>年月日は時系列に関係がないなら落としてもよさそう(そもそも物理的には年月日とPMに直接的な因果関係はないため)。月は影響がありそうだが気温のデータもあるため要検討
ー>各項目で観測回数, 最小値, 中央値, 最大値, 分散があるが多分全部は不要そう
●数値データに関して統計量としては学習データとテストデータで大きな違い(平均や標準偏差)は無さそう。
●欠損値は学習・テストデータともになし:欠損値処理は不要
なおデータ数が多いためsns.pairplot(df_train)は実行しませんでした。
5.CASE1:シンプルなPyCaretで処理
まずはPyCaretをシンプルに使用してどの程度性能が出るか確認しました。
5-1.前処理
まずは前処理を実施します。①不要なカラムを除去、②GPU使用 だけ追加して、後はPyCaret任せにします。
[IN]
from pycaret.regression import * #分類
dropcols = ['id', 'year', 'day', 'lat', 'lon', 'co_cnt',
'o3_cnt', 'so2_cnt', 'no2_cnt', 'temperature_cnt', 'humidity_cnt', 'pressure_cnt', 'ws_cnt', 'dew_cnt',]
exp = setup(df_train,
ignore_features=dropcols,
use_gpu = True,
# fix_imbalance = True, #偏りは小さいため不要
target = 'pm25_mid') #データの前処理
[OUT]
session_id=87185-2.学習・モデル比較
モデルの学習・比較を実施します。学習時は「Extra Trees Regressor」がベストスコアとなりました。
[IN]
best = compare_models() #モデルの比較
print(best)
print(type(best))
[OUT]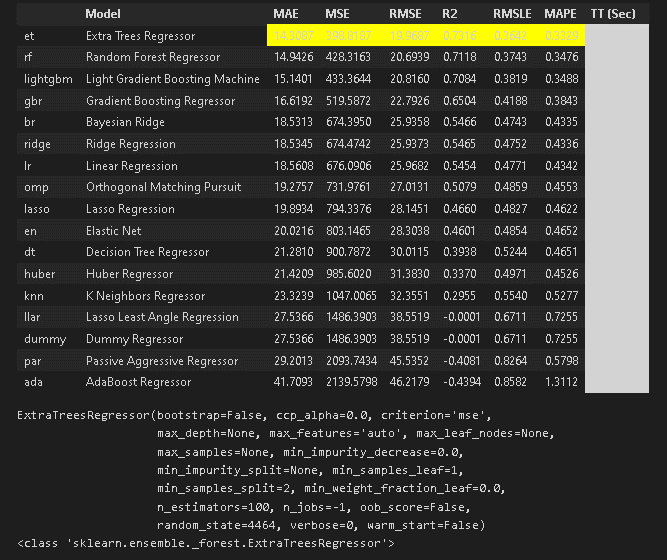
5-3.モデルの選択/ハイパーパラメーター調整
ベストモデルはたまたま性能が良いだけかもしれませんので上位モデルを何個か試します。選択時は多様性を考慮して別種のモデル(例:LightGBMを選択するならXGBoostは不要など)を選択します。
[IN]
extree = create_model('et') # Extra Trees Regressor
ramforest = create_model('rf') #Random Forest
lgbm = create_model('lightgbm') #Light GBM
bayridge = create_model('br') # Bayseian Ridge
linear = create_model('lr') #Linear Regression
#ハイパーパラメータ調整
#Ridge Classifier
tuned_extree, tuner_extree = tune_model(extree,
optimize ='f1',
return_tuner=True,
choose_better = True)
#Random Forest
tuned_ramforest, tuner_ramforest = tune_model(ramforest,
optimize ='f1',
return_tuner=True,
choose_better = True)
#Light GBM
tuned_lgbm, tuner_lgbm = tune_model(lgbm,
optimize ='f1',
return_tuner=True,
choose_better = True)
#Bayseian Ridge
tuned_bayridge, tuner_bayridge = tune_model(bayridge,
optimize ='f1',
return_tuner=True,
choose_better = True)
#Linear Discriminant Analysis
tuned_linear, tuner_linear = tune_model(linear,
optimize ='f1',
return_tuner=True,
choose_better = True) 5-4.モデルの評価/結果の可視化
モデルの評価/結果の可視化を実施します。自分が詳しいモデルならハイパーパラメータの確認は重要ですが、よくわからない場合は最低でも①AUC:性能、②混同行列:精度、③学習カーブ:過学習は確認します。
[IN]
evaluate_model(tuned_ridge)
evaluate_model(tuned_logistic)
evaluate_model(tuned_lda)
evaluate_model(tuned_ramforest)
evaluate_model(tuned_lgbm) 可視化はplot_modelで実施します
[IN]
plot_model(tuned_ridge, plot='learning')
plot_model(tuned_logistic,plot='learning')
plot_model(tuned_lda,plot='learning')
plot_model(tuned_ramforest,plot='learning')
plot_model(tuned_lgbm,plot='learning') 5-5.テストデータの推論
predict_modelにテストデータを渡してデータを推論します。また提出用CSVの形にするためid, labelだけ抽出してindex, headerは除去しました。
[IN]
pred_extree = predict_model(extree, data=df_test)
df_output = pred_extree[['id', 'Label']]
df_output.to_csv('220524_output_extree.csv', header=False, index=False)
pred_ramforest = predict_model(ramforest, data=df_test)
df_output = pred_ramforest[['id', 'Label']]
df_output.to_csv('220524_output_ramforest.csv', header=False, index=False)
pred_lgbm = predict_model(lgbm, data=df_test)
df_output = pred_lgbm[['id', 'Label']]
df_output.to_csv('220524_output_lgbm.csv', header=False, index=False)
pred_bayridge = predict_model(bayridge, data=df_test)
df_output = pred_bayridge[['id', 'Label']]
df_output.to_csv('220524_output_bayridge.csv', header=False, index=False)
pred_linear = predict_model(linear, data=df_test)
df_output = pred_linear[['id', 'Label']]
df_output.to_csv('220524_output_linear.csv', header=False, index=False)
[OUT]
csv作成5-6.結果の提出
結果(CSVファイル)をCLIで投稿します。なおCLIを使用しなくてもコンペページから手動で投稿できます。
[IN]
!signate submit --competition-id=725 220521_output_ridge.csv --note PyCaretを使用したRidgeClassifierで投稿
!signate submit --competition-id=725 220521_output_logistic.csv --note PyCaretを使用したLogisticRegressionで投稿
!signate submit --competition-id=725 220521_output_lda.csv --note PyCaretを使用したLinearDiscriminantAnalysisで投稿
!signate submit --competition-id=725 220521_output_ramforest.csv --note PyCaretを使用したRamdoForestで投稿
!signate submit --competition-id=725 220521_output_lgbm.csv --note PyCaretを使用したLightGBMで投稿5-7.提出結果の確認
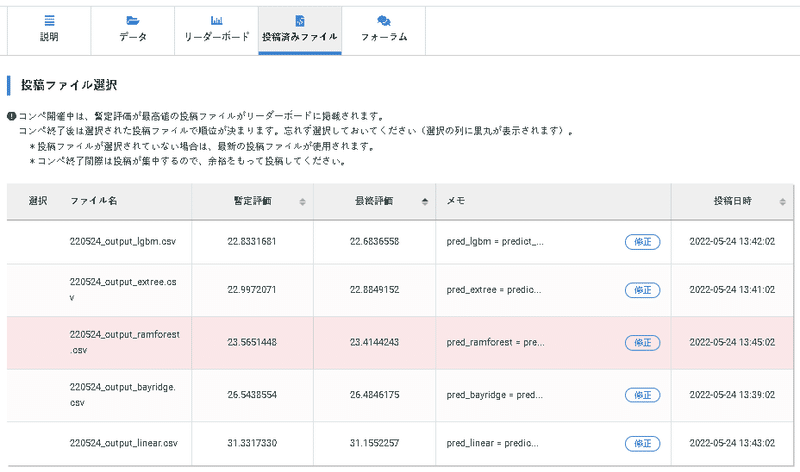
compere_models()では最高性能順に提出しましたが、実際のスコア(テストデータでの予想)は下記の通りです。
6.CASE2:ハイパラ調整:評価指標を設定
前章ではPyCaretの簡易さも含めてシンプルに実行しましたが、さらなる性能向上を求めてハイパーパラメータの調整を検討しました。
6-1.前処理/学習・モデル比較
前処理および学習・モデル比較は前章と同じ内容で実行します。
[IN]
from pycaret.classification import * #分類
exp = setup(df_train,
ignore_features=['id'],
use_gpu = True,
# fix_imbalance = True, #偏りは小さいため不要
target = 'charges') #データの前処理
best = compare_models() #モデルの比較
print(best)
print(type(best))
[OUT]
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=1000,
multi_class='auto', n_jobs=None, penalty='l2',
random_state=4487, solver='lbfgs', tol=0.0001, verbose=0,
warm_start=False)
<class 'sklearn.linear_model._logistic.LogisticRegression'>6-2.ハイパーパラメータ調整:指標追加
前回からの変更点は下記の通りです。
[IN]
ridge = create_model('ridge') #Ridge Classifier
logistic = create_model('lr') #Logistic Regression
lda = create_model('lda') #Linear Discriminant Analysis
ramforest = create_model('rf') #Random Forest
lgbm = create_model('lightgbm') #Light GBM
#ハイパーパラメータ調整
#Ridge Classifier
tuned_ridge, tuner_ridge = tune_model(ridge,
optimize ='f1',
return_tuner=True,
choose_better = True)
#Logistic Regression
tuned_logistic, tuner_logistic = tune_model(logistic,
optimize ='f1',
return_tuner=True,
choose_better = True)
#Linear Discriminant Analysis
tuned_lda, tuner_lda = tune_model(lda,
optimize ='f1',
return_tuner=True,
choose_better = True)
#Random Forest
tuned_ramforest, tuner_ramforest = tune_model(ramforest,
optimize ='f1',
return_tuner=True,
choose_better = True)
#Light GBM
tuned_lgbm, tuner_lgbm = tune_model(lgbm,
optimize ='f1',
return_tuner=True,
choose_better = True)
[OUT]
各モデルの交差検証の結果が出力(下記は最後に処理したLightGBM)参考までに下記を実行することで各モデルでの最適化アルゴリズムを確認することができます。
[IN]
print('tuner_ridge',tuner_ridge)
print('tuner_logistic',tuner_logistic)
print('tuner_lda',tuner_lda)
print('tuner_ramforest',tuner_ramforest)
print('tuner_lgbm',tuner_lgbm)
[OUT]
長いので省略6-3.評価・可視化
評価および可視化します。
[IN1]
evaluate_model(tuned_ridge)
evaluate_model(tuned_logistic)
evaluate_model(tuned_lda)
evaluate_model(tuned_ramforest)
evaluate_model(tuned_lgbm)
[IN2]
# plot_model(tuned_ridge)
plot_model(tuned_logistic)
plot_model(tuned_lda)
plot_model(tuned_ramforest)
plot_model(tuned_lgbm)
[OUT]6-4.結果提出・評価の確認
結果を提出して評価を確認します。
[IN]
pred_ridge = predict_model(tuned_ridge, data=df_test)
df_output = pred_ridge[['id', 'Label']]
df_output.to_csv('220522_output_ridge_f1metric.csv', header=False, index=False)
pred_logistic = predict_model(tuned_logistic, data=df_test) #Logistic Regression
df_output = pred_logistic[['id', 'Label']]
df_output.to_csv('220522_output_logistic_f1metric.csv', header=False, index=False)
pred_lda = predict_model(tuned_lda, data=df_test) #Linear Discriminant Analysis
df_output = pred_lda[['id', 'Label']]
df_output.to_csv('220522_output_lda_f1metric.csv', header=False, index=False)
pred_ramforest = predict_model(tuned_ramforest, data=df_test) #Ramdom Forest
df_output = pred_ramforest[['id', 'Label']]
df_output.to_csv('220522_output_ramforest_f1metric.csv', header=False, index=False)
pred_lgbm = predict_model(tuned_lgbm, data=df_test) #Light GBM
df_output = pred_lgbm[['id', 'Label']]
df_output.to_csv('220522_output_lgbm_f1metric.csv', header=False, index=False)[IN ※提出したモデル評価中は提出できないため時間をおいて1個ずつ実施]
!signate submit --competition-id=624 220524_output_extree.csv --note PyCaretを使用したExtraTreesRegressor
!signate submit --competition-id=624 220524_output_ramforest.csv --note PyCaretを使用したRandomForest
!signate submit --competition-id=624 220524_output_lgbm.csv --note PyCaretを使用したLightGBM
!signate submit --competition-id=624 220524_output_bayridge.csv --note PyCaretを使用したBayseianRidge
!signate submit --competition-id=624 220524_output_linear.csv --note PyCaretを使用したLinearRegression結果は下記の通りであり、性能更新とはいきませんでした。
6-5.モデルのPickle化+ファイル保存
後でハイパラを確認できるようにPickle化->ダウンロードしてファイルを保存します(Colab使用のため切断後にファイルが消えるため)。
7.結果
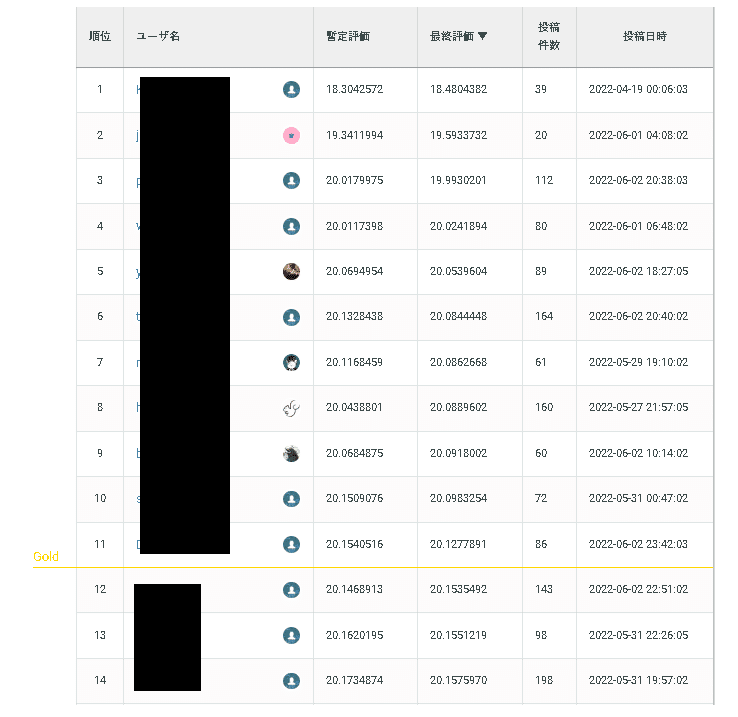
結果は最高スコアはLight GBMでRMSE=22.7程度でした。上位を狙うならRMSEは20を切らないとだめなので、特徴量エンジニアリング(不要なカラムを抜いたり、新しい特徴量を作成など)が必要そうですね。
参考資料
あとがき
やっぱテーブルデータだとGBDTは強い!
あとPyCaretの学習時(compare_models())は交差検証しているとはいえ過学習しやすいモデルが上位にいったり、ハイパラが重要なモデルが低スコアになったりするのでそこらへんは要注意かな・・・・
この記事が気に入ったらサポートをしてみませんか?