今年もやります!Jリーグ予測2019シーズン編:予測方法の説明(20190429追記あり)
昨年夏あたりから,ワールドカップ予測(下記記事参照)のプログラムを流用してJリーグの予測も始めておりまして,Twitterで上げておりましたところグラサポ界隈に発見していただき今日に至っております.徐々にではありますがフォロワーとインプレッションが増えててうれしい.
ということで,今年もJリーグ予測,やります!Bリーグとかぶっている春先はちょっと作業が多そうですが!
この記事は予測方法の説明です
基本的には試合のあった週末明けの月曜日,J1からJ3の予測をTwitterで公開します.予測方法の概要をここで説明します.
予測方法は,非常に大まかに言うと,
1. 各チームに強さを表すパラメータ(レーティングと呼んでいます)が1個だけあるとする.
2. 対戦チームのレーティング差が,試合での得点割合を説明するようにがんばってパラメータを調節する.これを毎週行う.
* 数学の言葉で言うと「ロジスティック回帰モデル」を利用しています.
*「得点割合」は,(ホームチームの得点+1)/ホームチームの得点+1 + アウェイチームの得点+1)です.Colley法と呼ばれる修正方法で,完封の価値を適切に反映させるためのものです.
3. 過去の対戦での試合直前のレーティング差と勝ち分け負けの関係を,統計的に見つける←これが確率を予測するモデルになる.
2.では,今シーズン行われた全ての試合結果に基づいてレーティングを算出します.試合結果は最新のものほど反映されるように調整します(半年前の試合は最新の半分程度の重要度になるようにしています)
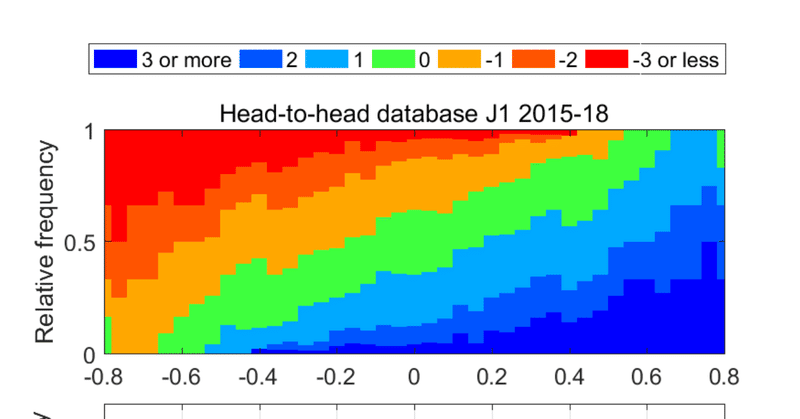
3. では,2015年以降4年間の各試合日について,2.の処理を行ったデータベースを作ります.たとえば,J1だと下図ができ上がります.
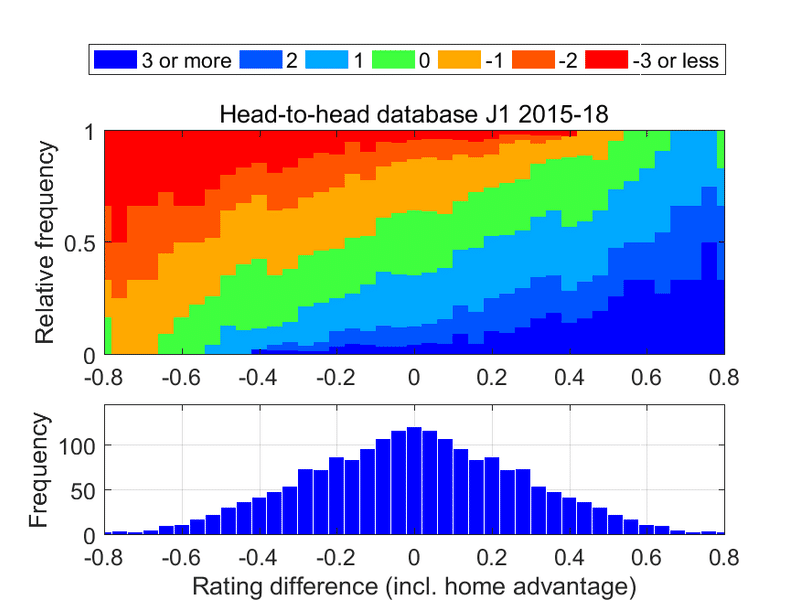
横軸はレーティング差(ホームアドバンテージを含む),上図はそのレーティング差(の近く)の対戦でおこった得点差の割合,下図はそのレーティング差(の近く)の対戦数です.当然ですが,その試合までに好成績を収めていたほうのチームが勝利する確率が高く,得失点差の期待値も大きいことがわかります.ホームアドバンテージはそこそこあり,上図の横軸で0.033でした.
上図のデータベースから扱いやすい関数にしたものを勝敗予測確率のモデル,データベースそのものを得失点差の予測に利用します.
具体例
J1第7節(2019年4月13日),横浜FM対名古屋の対戦を予測してみましょう.それぞれのチームのレーティングは,横浜FMは0.0069+0.0332=0.0401,名古屋は0.4876です.レーティングは差のみ意味があり,0はリーグの平均を示します.ホームの横浜FMから見たレーティング差は-0.4475です.上図からこの付近の勝敗を抜き出したものをここでは「予測」と称します.
つまり,「過去に似たような実力差で行われた試合の結果と似たような結果がこれから起きるだろう」という予測です.
(横浜FMのレーティングが得失点の割には低く感じますが,これはこれまでの対戦相手や,そもそも試合数が少ないことに起因します.)
これを同節の全試合に対して行ったものが以下のツイートです.
#Jリーグ J1次節予測.2019/4/8更新.
— konakalab (小中研究室/名城大) (@konakalab) April 8, 2019
青:ホーム勝利.濃いほど得点差大.緑:引き分け.赤:アウェー勝利.濃いほど得点差大. pic.twitter.com/9fiu4kDUDr
そして,これ以降の全試合に対し,現時点でのレーティングに基づく勝敗確率を用いて試合結果を予測すると,最終的な勝点の分布を計算できます.これが以下のツイートです.
#Jリーグ J1シーズン勝点予測.2019/4/8更新.赤丸:予測平均,緑三角:現在の勝点,青点線:上位5%から95%,青実線:上位25%から75%. pic.twitter.com/ELydtUeWUK
— konakalab (小中研究室/名城大) (@konakalab) April 8, 2019
現時点で順位に関わる予測(優勝,ACL,昇降格など)は時期が早いので示しませんが,シーズン中盤以降は追加する予定です.
さて,この手法ですが,上記を読んでいただければお分かりかもしれませんが,「チーム間の相性」「気候」「怪我」「新規加入」など全く考慮できないものです.平均勝点をまっすぐ伸ばすよりはちょっとはチームの実力を考慮できているかな・・・?という程度のものではありますが,お楽しみいただければ幸いです.
それでは,今年も楽しくサッカー観戦を!
追記(20190429):勝点予測の見方について
そういえば勝点予測の読み方について説明していませんでしたね,という追記です.現時点(2019年4月29日)での最新版の予測は↓です.
#Jリーグ J1シーズン勝点予測.2019/4/29更新.赤丸:予測平均,緑三角:現在の勝点,青点線:上位5%から95%,青実線:上位25%から75%. pic.twitter.com/d6iM9w8DjS
— konakalab (小中研究室/名城大) (@konakalab) April 29, 2019
縦軸はチーム名です.横軸は勝点で,各チームいくつかの数値を示してあります.
・緑三角:現時点での勝点
・赤丸:10000シーズン分シミュレーションを繰り返したときの平均値.「現在の実力のまま全試合終わったとして,一番起こりそうな勝点」です.
・青線:点線と十字は,10000回シミュレーションした結果を勝点が多い順に並べたとき,上位と下位それぞれ5%での勝点です.「現在の実力のまま全試合終わったとして,この間に最終的な勝点が入る確率が90%の区間」を示しています.統計の用語では「信頼区間」と呼びます.実線と四角は上位下位それぞれ25%,つまり,「青実線の間に最終的な勝点が入る確率が50%の区間」です.
追記(20190409夜):この予測の目的など
ここでこんな予測をする目的を追記しておきたくなりました.
この予測モデルの開発目的は,試合結果をバシバシ正確に当てまくること,ではありません.
じゃあ何か?というと,「過去の得点のみでここまで予測できます.しかも複数競技が同じモデルで!」が大きなテーマです.
下記リンクは採録予定の私の論文ですが,「一つの手法でオリンピックの5競技(バスケットボール,ハンドボール,ホッケー,バレーボール,および水球)10種目を予測してみたら,世界ランキングや専門家の予測よりも精度が高かった」ことを報告しています.(単独競技の予測は実践例が多いのですが,同一モデルで競技横断的に報告した例は自分の調査範囲内では見当たりませんでした)
複数競技にまたがって共通な指標といえば「得点」しか無いので,競技固有の現象をモデルに入れることができません.
もうちょっと言うと,「試合を全く見ないで過去の得点とシンプルなモデルでどこまで予測できるか」という挑戦でもあります.ぶっちゃけるとサッカー選手を知らなくて良いし,もっと言うとサッカーというスポーツを知らなくてもできてしまう予測です.
煎じ詰めると「お互いが得点を取り合い,その多少で勝敗が決まるゲーム」であるなら何でも適用可能な方法しか利用していません.種目特有の項目を反映させた予測モデルを構築したときの比較対象(基準)になりうるものを作っている,ともいえるでしょうか.
この記事が気に入ったらサポートをしてみませんか?