OpenAI GPT APIを用いたAI小説生成環境の作成 ━各種パラメータの調整━

先月の続きになります。
WebサイトからChatGPTを使うのではなく、APIを使うと、独自開発のシステムに組み込んだり、他のシステムと連携したりできるだけでなく、細かくパラメータを指定することが可能です。
とはいえ、ある程度プロンプトで結果を追い込んでから、細かいパラメータの調整をすればいいやと思い、パラメータのことは後回しにしていたのですが、実際に少しパラメータをいじってみるとかなり結果が変わるので、慌ててドキュメントを読み直しています。
つまり、これまで完全にプロンプトエンジニアリングの罠にはまっていたわけです。うっかりこいつが巨大なTransformerであることを忘れていました。自然言語で話しかければ気さくに答えてくれるという思い込みから、ついつい文章生成システムを擬人化してしまっておりました。
プロンプトをいじくりまわす前にパラメータの意味と、パラメータを変えたときの挙動の変化を抑えておく必要がありそうです。
OpenAI Chat completion API のパラメータ
とりあえず、OpenAIのドキュメントを読みながら、ポチポチとパラメータを変えて試しています。
temperature
OpenAIの説明では、0~2のあいだの数値で設定でき、値が大きくなるほど出力がランダムになるとのこと。
説明の中では、"Higher value" の例として0.8を挙げていますが、値を何も指定しなかったとき、つまりデフォルト値は1です。はじめからHigherな設定なのですね。どうりで、プロンプトをいじくってもなかなか思い通りにいかないはずです。
実際に試してみた感じでは、0.8より小さめに設定すると安定した文章が出力されます。プロンプトの指示にも忠実になります。普段は0.5から0.8のあいだに設定しておくのがいいかもしれません。
ただ、0.8前後で少し長い文章を書かせたとき、最後に「仲良く暮らすことになりました」や「平和になりました」のような、物語の終わりを示唆する文章で締めくくろうとする傾向が強くなるように感じます。
0に近づけると、同じプロンプトを投げたときに似た文章を出力するようになります。0にすると、同じプロンプトには同じ文章が出力されるようになります。
逆に1より大きくした場合、1.5ぐらいまでなら個々の文章は日本語としてそれほどおかしくないので、少し話を展開させたい場合など、1より少し大きめに設定するといいかもしれません。ただし、少し長くなると、後の方は辻褄の合わないヘンな文章を出力するようになります。
top_p
元々は上記のtemperatureを代替するものとして設計されているようで、核サンプリング(nucleus sampling)という手法が使われているとのこと。
トークンの持つ確率質量(probability mass)という言葉を使って説明されています。例えば、top_pに0.1を設定すると、上位10%の確率質量を占めるトークンだけが採用候補になるということだそうです。
次に出力するトークンを予測したときに確率の高いものから順に並べて、上から順に確立を累積していって、10%になったところまでの候補から次のトークンが選ばれるというもののようです。
このパラメータに指定できる値の範囲は示されていませんが、試してみると最大値は1のようです。最小値は0で、0を指定してもそれっぽい結果が返ってきます。説明を読んだだけでは、0を与えると0%になってしまい、結果が出なくなりそうですが、そういうわけではないようですね。
デフォルト値は1。確率質量が100%になるまで選択肢候補として採用する設定。つまり、何も設定していないのと同じというわけですね。
temperatureとtop_pの関係
OpenAIの説明では、temperatureとtop_pを一緒に設定することはお勧めしないと注意書きが添えられています。
では、両方一緒に設定したらどうなるのだろうかと思い、試してました。temperatureを徐々に大きくしていき、1.8ぐらいに設定すると、日本語になっていないおかしな文章が生成され始めます。この状態で、top_pを0.98とか、0.95ぐらいに落としてやると、日本語らしい文章が出力され、出力が安定したように感じます。
なに?いけるじゃん。
試してみた表面的な結果だけから想像すると、ある程度お話を発散させる目的でtemperatureを高めに設定して、文章を安定させるためにtop_pを少し減らしてやるという使い方ができそうな気がします。
AIって開発者も想像しない結果を生み出すんですよね~
っていう、いま流行りのAIスゴイ!勝手に人間超えるかも!的な風潮に乗っかって行こうかと思ったのですが、ただ、説明文をあちこち何度も読み返したり、値を変えて文章を生成してみたりを繰り返していると、どうやらtemperatureもtop_pも、結果的に、スコアの高いものから順に並べたときの足切り値(閾値)をずらしているだけのような気がします。そう考えると、実は両方を同時に設定する意味はなく、厳しい方が効いているだけなのかもしれません。
試しに、temperatureとtop_pに交互に0を設定してみました。
temperatureもtop_pも、どちらかの値を0にすると何度プロンプトを投げても同じ結果が出力されるようになります。お互い、片方を0にすると、もう片方の値を変えても返ってくる結果が同じになることから、パラメータは違うものの、影響するところは結局同じのようです。
したがって、やはりOpenAIの説明通りで、temperatureとtop_pの組み合わせをいろいろ試してみるのは、あまり意味がない気がします。
ただ、top_pは最大値が1ですが、temperatureは最大値が2です。意図的に不安定な結果を出力させたいときは、temperatureを1より少しだけ大きくして、top_pを1(デフォルト値)にしておけば良いようです。
また逆に、より安定した結果を得たいときは、temperatureを下げてもtop_pを下げてもだいたい似たような結果が得られそうなので、常にどちらか片方は1(デフォルト値)にしておいたほうが、どちらのパラメータが効いているのかわかりやすく、調整がしやすいように思います。
presence_penalty
-2.0~2.0の値で設定でき、この値が大きくなるほど新しいトピックについて話すようになるとのこと。
temperatureと合わせて設定すれば、物語の展開をコントロールできるかもしれません。
デフォルト値は0。
frequency_penalty
-2.0~2.0の値で設定できます。OpenAIのドキュメントには、この値が大きくなるほど同じ行(same line)の逐語的(verbatim)な繰り返しを減らす と、説明されています。デフォルト値は0。
ちくごてき? 何のこっちゃ? と思ったら、一字一句忠実にということなのだそうです。
よくわからないので試してみました。例えば、-2.0に設定して「むかしむかし、あるところに」の続きを書かせてみると、「おばあさんと、おじいさんが住んでいました。おばあさんはとてもやさしく、おおらかな性格で、おじいさんはおおらかでおおらかなおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおおお……」と、後半は同じ文字が繰り返し出力されて文章になりませんでした。
たまたま「おばあさん」「おじいさん」と、「お」が繰り返し使われたので、より「お」を使いやすくなり「おおらかな性格」を選んで、さらに「お」が強化されて「おおおおお……」となったようです。
same lineと説明されていますが、どうも行ではなくトークンのようです。
presence_penaltyとfrequency_penaltyの関係
presence_penalty(プレゼンス ペナルティ)とfrequency_penalty(周波数ペナルティ)については、更に詳しく説明されており、下記の式で表されています。
mu[j] -> mu[j] - c[j] * alpha_frequency - float(c[j] > 0) * alpha_presence
mu[j]:j番目のトークンのロジット
c[j]:そのトークンが現在の位置の前にサンプリングされた頻度
float(c[j] > 0) :c[j] > 0 の場合は 1、それ以外の場合は 0
alpha_frequency :周波数ペナルティ係数
alpha_presence :プレゼンス ペナルティ係数
ここでいうロジットについて "un-normalized log-probabilities"(正規化されていない対数確率) という注釈が入っているのであれこれ悩んだのですが、ロジット関数のロジットとは、ちょっと解釈が違うのかもしれません。どうもOpenAIのAPIに関するドキュメントの中では、モデルが返してきた数値(スコア)そのもののことをロジット(logits)と言っているのかな?という気がします。あるいは、学習のさせ方次第で、だいたい同じ意味になるのかもしれません。
ともかく、トークンを選ぶときに、各候補トークンのロジットに対して、その候補トークンが過去に使われた頻度によってマイナスの下駄を履かせて(ペナルティを与えて)います。
presence_penaltyは、過去に一度でも使われていると、毎回同じ値でペナルティを与えますが、frequency_penaltyは、過去の使用頻度に比例してペナルティを与えます。
だから、frequency_penaltyをマイナスの値にすると、同じトークンを繰り返してしまうのですね。
ただ、この理屈でpresence_penaltyを大きくすると、トピックが変わりやすくなるというのは興味深いところです。
英語だと一つの単語が1~2トークンで構成されていることが多いので、そうなるのでしょうか?
日本語だと、一文字ごとに1~2トークンに分かれているので、同じ効果が得られるのかどうかわかりませんが、うまく漢字などに作用すれば似た効果が出るのかもしれません。
実際に試した感じでは、例えばpresence_penaltyを1.5程度に大きくすると、トピックが変わるというよりは、文章のつながりが悪くなるように感じました。選択するトークンに制約がかかるので、お話としてありがちな文章を選びにくくなるのでしょう。
特に、temperatureを1より大きくしていると、日本語の文章の中で、突然英単語が出てきたり、文章の崩れが顕著になります。
presence_penaltyやfrequency_penaltyを0以外にするときは、temperatureやtop_pを少し保守的な値にしておいたほうがいいかもしれません。
logit_bias
logit_biasを使うとトークンごとに出現確率をコントロールできるようです。
トークンIDごとに-100~100の間で各トークンのロジットに履かせる下駄を指定できるようです。
このパラメータはまだ試していませんが、特定の不適切な単語の出現を抑えるようなことができるのかもしれません。presence_penaltyとfrequency_penaltyの挙動から考えると、このパラメータを使うときは、temperatureやtop_pの設定をよく検討しておく必要がありそうですね。
物語製造器 悪手側竜乃輔(仮名)の進捗
今月は、あまりコードはいじくっていません。
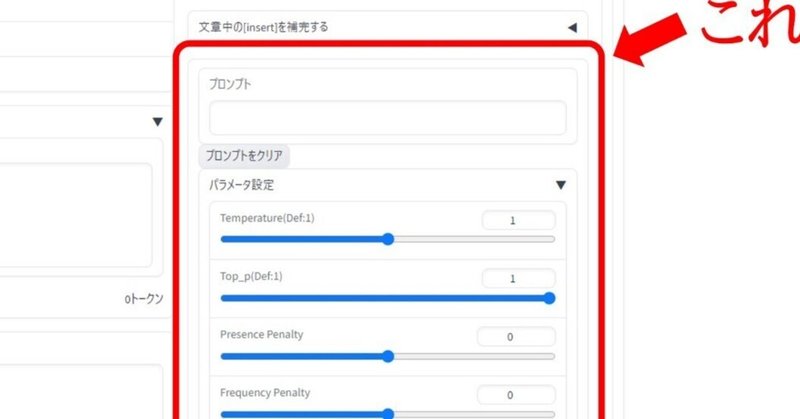
ログの出力をちょっといじるなどの細かい変更は随時進めてはいますが、見た目でわかる変更箇所としては、パラメータをポチポチ変えて遊ぶために、プロンプト用のTextboxの下に、パラメータ設定のSliderを並べてみました。
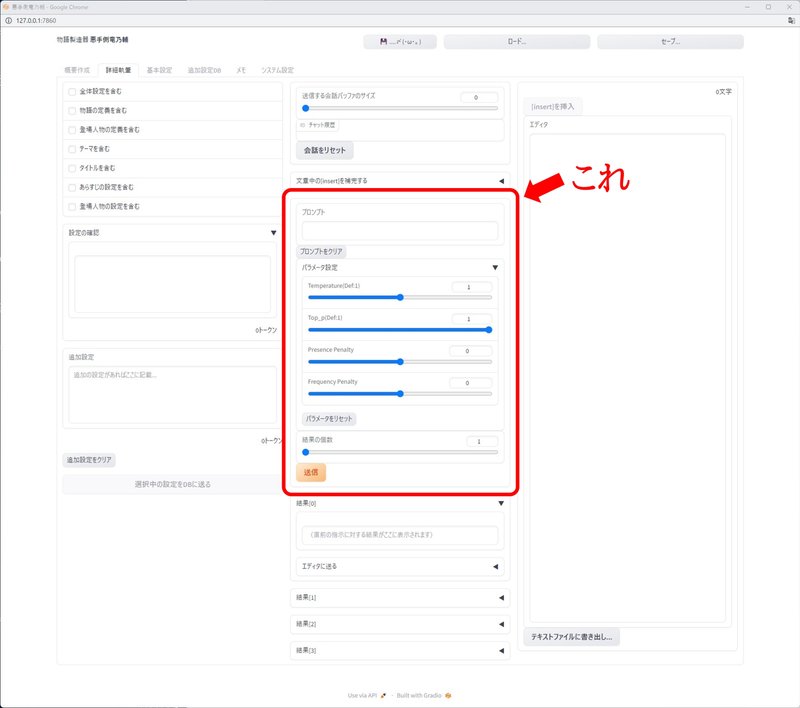
同じプロンプトで、パラメータだけ変えてみたり、パラメータをいろいろ変えながら遊んでいるうちに、なんとなく使えそうかな?っていう感じがしてきています。
もうちょっと触ってみてからUIに反映していこうかと思います。
頂いたサポートは今後の記事作成のために活用させて頂きます。