日本語言語モデルのGUIを作ってフェイクニュースを生成!?

ブルゾンちえみが「35億」って言うだけで面白かったのはいつ頃のことでしたっけ。ギター侍よりは最近のような気がするけど……
先月17日に、rinnaから、日本語で学習した36億パラメータのGPT言語モデルが公開されました。
1億違い。惜しいですね。なんで35億にしなかったんだろう。当時女子高生だった りんな は、絶対ブルゾンちえみを覚えてるはずなんですけどね。
さて、ここ2、3か月で急にいろんな言語モデル、特に、日本語ネイティブな言語モデルが公開され始めた印象です。
なんか、もうめっちゃ気になるのですが、GPUメモリが大量にないと動かないんだろうな~という雰囲気がしますよね。
あんまり深入りするとバカ高いグラフィックボードを衝動買いする羽目になるような気がして、ロシュの限界近傍で適当にクルクル公転していようかと思っていました。
ところが、Internet Watchの記事「自宅PCで「rinna」の日本語言語モデルを試用、メモリ32GBあればCPUだけでも動くぞ!」によると、GPUを使わずにCPUだけでもとりあえず動くとのこと。
えっ、マジ!?
なんと、記事によると、Core i3 & メモリ32GBで動くみたい。いやぁ、2020年のコロナ禍の中、一律給付された給付金をぶち込んで組んだMy PC、メモリは64GBございます。
なんせ、ワードとエクセルとパワポを複数同時に開いて、Chromeのタブをファビコンが見えなくなるぐらい大量に開いてもストレスなく資料作りができ、且つ、仮想デスクトップを切り替えて気晴らしにBlenderで遊んだりできる。そういう庶民のプチ贅沢な環境が欲しかったのです。
当時は、AMDとインテルのメニーコア競争の真っ只中。「見せてもらおうか。インテルの新型10コア20スレッドの性能とやらを」と、CPUはCore i9-10900をチョイスしたのでした。
CPUが20コアあるのにメモリが4GBとか8GBじゃ意味ないですからね。とはいえ、フル装備の128GB買うにはバジェット不足。懐事情が許す範囲の64GBブッ刺しました。おかげで、いまも機嫌よく動いております。
なんか、これならいけそう……
「こいつ、動くぞ!」
とりあえず、上記のInternet Watchの記事を参考に必要なライブラリをインストール。PyTorchはCPU用を使うため、記事とは異なり、下記のコマンドを使用しました。
pip3 install torch torchvision torchaudio
必要なライブラリをインストールした後、取り急ぎHugging Face上にある、rinna/japanese-gpt-neox-3.6bのREADMEに書かれているPythonのコードをほとんどそのまま実行してみました。
いまのところ、チャットにはあまり興味がないので、上記の記事の中に書かれている、rinna/japanese-gpt-neox-3.6b-instruction-sft ではなく、rinna/japanese-gpt-neox-3.6bの方です。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("rinna/japanese-gpt-neox-3.6b", use_fast=False)
model = AutoModelForCausalLM.from_pretrained("rinna/japanese-gpt-neox-3.6b")
if torch.cuda.is_available():
model = model.to("cuda")
text = "吾輩は猫である。"
token_ids = tokenizer.encode(text, add_special_tokens=False, return_tensors="pt")
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
max_new_tokens=100,
min_new_tokens=100,
do_sample=True,
temperature=0.8,
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id
)
output = tokenizer.decode(output_ids.tolist()[0])
print(output)スクリプトを実行すると、config.json、spiece.model、tokenizer_config.json、model.safetensors、の4ファイルがキャッシュにダウンロードされます。データのサイズが7GB以上あるので、ここでかなり待たされますが、これはCPUの性能やメモリの容量とは無関係なところなので黙って待ちます。
思ったより長いな、スマホで詰将棋でもして時間を潰すか。と思っていると、おもむろに下記の文章が出力されました。
吾輩は猫である。』は、その題名と作品の内容が極めて奇妙にマッチしている。題名は猫の一生を描いた小説であるが、作品そのものも猫の一生についての考察が随所に織り交ぜられている。作品の舞台は、猫の一生を擬人化した作品であり、猫視点で物語が進められている。作品の内容と題名が見事にマッチしている。 小説の内容は、猫の一生を擬人化した作品であり、猫視点で物語が展開されていく。猫の一生
何回言うの「猫の一生」。
でも、ま、とりあえず動きました。CPUで。
なんとなく行けそうなので、フォルダ(ディレクトリ)を決めて https://huggingface.co/rinna/japanese-gpt-neox-3.6 から、ファイルを一式ダウンロード。
スクリプトの方は、カレントディレクトリのモデルを読むようにちょっと修正しました。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
import os
cwd = os.getcwd()
#tokenizer = AutoTokenizer.from_pretrained("rinna/japanese-gpt-neox-3.6b", use_fast=False) #model = AutoModelForCausalLM.from_pretrained("rinna/japanese-gpt-neox-3.6b")
tokenizer = AutoTokenizer.from_pretrained(cwd, use_fast=False)
model = AutoModelForCausalLM.from_pretrained(cwd)
# if torch.cuda.is_available():
# model = model.to("cuda")
text = "吾輩は猫である。名前は"
token_ids = tokenizer.encode(text, add_special_tokens=False, return_tensors="pt")
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
max_new_tokens=100,
min_new_tokens=100,
do_sample=True,
temperature=0.8,
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id
)
output = tokenizer.decode(output_ids.tolist()[0])
print(output)実行すると……
吾輩は猫である。名前はない。まだ野良時代、のら猫が子を産んだので、それをもらってきて名づけ親になったのだ。それも、何回か、いや、何十回か、名前を変えた。名前の付け方は、自分の好みだ。猫は、名前を付けると、その名前で呼ぶと、必ず反応する。呼んでも何の返事もしなかった野良猫が、名前を呼ぶとこっちを見たり、手でちょい
なんか、できましたね。約1分ぐらいかかりますが、とりあえずそれらしい日本語が出力されます。
ただ、なんか「名前」にこだわり過ぎのような気がしますね。パラメータを調整したいのですが、何をどう変えればいいのやら。
ん~と考えながらソースを眺めていると、temperatureというパラメータがあります。ああ、これ、OpenAIのAPIでも見たやつですね。
たぶんこのあたりをいじればいいんだなと、アタリを付けつつネット検索していると……ありますね。ちゃんとドキュメントが。
ここを見ると、top_pもあるし、repetition_penaltyなんていう、frequency_penaltyみたいなパラメータもある。更に、どうやらforce_words_idsを指定すると、文章の中に特定の単語を含めてくれるようです。
ちょっと試してみます。「おばあさん」の強制召喚にトライ。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
import os
cwd = os.getcwd()
#tokenizer = AutoTokenizer.from_pretrained("rinna/japanese-gpt-neox-3.6b", use_fast=False) #model = AutoModelForCausalLM.from_pretrained("rinna/japanese-gpt-neox-3.6b")
tokenizer = AutoTokenizer.from_pretrained(cwd, use_fast=False)
model = AutoModelForCausalLM.from_pretrained(cwd)
# if torch.cuda.is_available():
# model = model.to("cuda")
text = "吾輩は猫である。名前は"
token_ids = tokenizer.encode(text, add_special_tokens=False, return_tensors="pt")
force_words_ids = tokenizer('おばあさん', add_special_tokens=False).input_ids
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
max_new_tokens=100,
min_new_tokens=100,
do_sample=False,
temperature=0.2,
top_p=1.0,
diversity_penalty=0.0,
repetition_penalty=1.2,
encoder_repetition_penalty = 0.5,
force_words_ids = [force_words_ids],
num_beams = 2,
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id
)
output = tokenizer.decode(output_ids.tolist()[0])
print(output)吾輩は猫である。名前はおばあさんがつけてくれたのだが、どうもぴったりとこない。そこでいろいろ考えてみたが、結局のところ、どうもこの名前に愛着が持てないのだ。そこで、この名前を捨てることにした。捨てるのは惜しい気もするが、仕方がない。捨てるのは惜しい気もするが、仕方がない。捨てるのは惜しい気もするが、仕方がない。捨てるのは惜しい気も
そんなに惜しいなら捨てなきゃいいのにとは思いますが、ちゃんと「おばあさん」が出てきます。
お題作文
こうなるとお題作文がやってみたくなりますね。
「桃太郎」「金太郎」「かぐや姫」を使って、「むかしむかし、」の続きを書かせてみます。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
import os
cwd = os.getcwd()
#tokenizer = AutoTokenizer.from_pretrained("rinna/japanese-gpt-neox-3.6b", use_fast=False) #model = AutoModelForCausalLM.from_pretrained("rinna/japanese-gpt-neox-3.6b")
tokenizer = AutoTokenizer.from_pretrained(cwd, use_fast=False)
model = AutoModelForCausalLM.from_pretrained(cwd)
# if torch.cuda.is_available():
# model = model.to("cuda")
text = "むかしむかし、"
token_ids = tokenizer.encode(text, add_special_tokens=False, return_tensors="pt")
force_words_list = ['桃太郎','金太郎','かぐや姫']
force_words_ids = []
for force_words in force_words_list :
force_words_ids.append(tokenizer(force_words, add_special_tokens=False).input_ids)
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
max_new_tokens=150,
min_new_tokens=100,
do_sample=False,
temperature=0.9,
top_p=1.0,
diversity_penalty=0.0,
repetition_penalty=1.8,
encoder_repetition_penalty = 0.2,
force_words_ids = force_words_ids,
num_beams = 3,
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id
)
output = tokenizer.decode(output_ids.tolist()[0])
print(output)さて、結果は、
むかしむかし、金太郎は桃太郎とかぐや姫に出会いました。金太郎は鬼を退治し、かぐや姫と結婚して幸せに暮らしましたとさ。めでたし、めでたし。 しかし、この話には続きがあります。金太郎が結婚してからしばらく経ったある日のこと、かぐや姫が月へ帰らなければならなくなりました。金太郎はかぐや姫のことが忘れられず、毎日泣いてばかりいました。そして、とうとうかぐや姫が月へ帰る日がやってきました。金太郎はかぐや姫に別れを告げると、ひとりで旅に出ました。 金太郎が旅から帰ってみると、かぐや姫は
おっと、思いのほかそれっぽい文章が出てきました。
金太郎が旅から帰ってみると、かぐや姫は……どうなったの! まさか、桃太郎と!? 続きが読みたい(笑)
ビームサイズを増やしたり(num_beams = 3)したので、生成に2分程度かかっていますが、パラメータをいじくるだけで結構それっぽい文章が出力されました。
尚、Beam Searchについては、下記のページがわかりやすかったです。
なんか、Hugging Faceのtransformersすごいですね。Attention Is All You Needならぬ、Hugging Face Transformer is all you needじゃないですか。
これは、結構遊べるのでは?
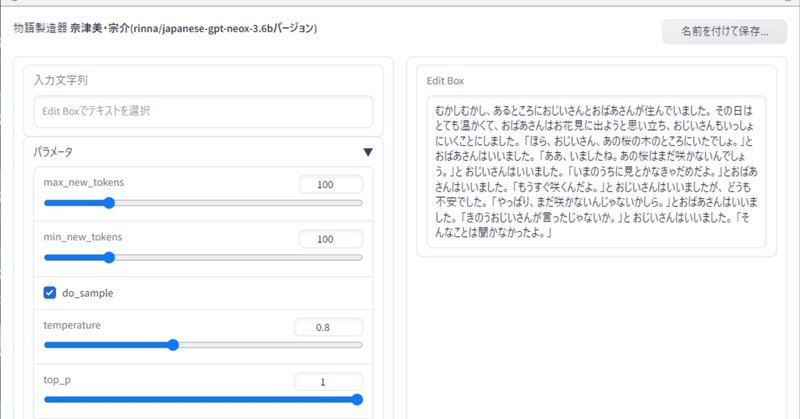
GUIを作ってみる
取り急ぎ、Gradioを使ってGUIを作ってみました。

左右2ペインで、左がAIの作業領域、右が人間の作業領域になります。
もっとも簡単な使い方
何も入力していない状態で、左にある「文章生成」というボタンをクリックします。すると、「吾輩は猫である。名前は」に続く文章が「結果」と書かれたテキストボックスに出力されます。
すると、テキストボックスの下の「Edit Boxに送る」というボタンがオレンジ色になるので、これをクリックして右側の「Edit Box」に結果をコピーします。
この1と2を繰り返せば、続きを書くことができます。

このままだと、Edit Boxの中の文章が丸ごと入力に使われるのでメモリの消費量が多くなります。
テキストを選択して「入力文字列」へ

Edit Boxでテキストを選択すると、自動的に左の「入力文字列」と書かれたテキストボックスにコピーされます。
その状態で「文章作成」をクリックすれば、選択した文字列の続きが生成されます。

少しだけ、文字を入力してみる
「吾輩は猫である。名前は」からはじまる文章ばかり生成しても面白くありません。書き出しを少しだけ書いてみます。
文字を入力できるのは、右の「Edit Box」だけです。
「Edit Box」に「ワシントンからの情報によると、」と入力してみます。
何も選択しないと「Edit Box」の文字列がそのまま使われるので、そのまま「文章生成」ボタンをクリックします。

情報ソースはイラン側なのかアメリカ側なのか、ごっちゃごちゃのスパゲッティなフェイクニュースが生成されました。
force words を設定してみる
書き出しはそのままで、「force words」に「大統領」と「ホワイトハウス」を設定してみます。
「force words」には、文章中に含めたい単語を「,」(半角コンマ)で区切って入力します。
「force words」に文字を入力すると、自動的に「d_sample」のチェックがOFFに、「num_beams」は2以上に設定されます。

どうも、後半同じ文章が繰り返しているようです。使う単語を決められて、他の選択肢が出てこなくなったのかもしれません。
bad words を設定してみる
どうもきな臭い話題ばかりに偏ってしまうので、「イラン」と「北朝鮮」を「bad words」に設定してみます。
こちらも「force words」同様、「,」(半角コンマ)で区切って入力します。
より制約が厳しくなったので、同じ文章を繰り返す傾向がますます強くなってしまいました。とりあえず「force words」と「bad words」はそのままで、他のパラメータを変えながらトライしてみました。

どうしてもこの手の話題に執着してしまうようですが、一応はお題通りに「ワシントンからの情報によると、」ではじまって、「大統領」と「ホワイトハウス」が入っていて、「イラン」と「北朝鮮」が入っていない文章が出力されました。
気に入った文章が生成されたら、「Edit Boxに送る」ボタンをクリックして、「Edit Box」に送って行けば続きを生成することができます。
生成した文章を保存したければ、右上の「名前を付けて保存…」と書かれたボタンをクリックすると、「Edit Box」の中身がテキストデータとして保存できます。
チャットシステムではないけれど……
チャットシステムではないので、AIとの会話を楽しむことはできませんが、筆者としては、このくらいシンプルな方が、より「文章生成AI」というイメージに近いような気がしています。
完全にローカルで動いているので、OpenAIのAPIのように課金を気にしながら使う必要はありません。パラメータをいろいろ変えてみて、いろんなトライを繰り返すことができます。
今回、GUIを作ってパラメータをちまちま触ってみて、はじめて言語モデルの全体像がおぼろげながら見えてきたような気がします。やっぱり手を動かしてみることは大事ですね。
GitHubで公開
今回作成したGUIのソースファイルは、GitHubで公開しています。
頂いたサポートは今後の記事作成のために活用させて頂きます。