
知識より計算力―AI時代の新しい価値観

人類が文明社会に入って以来、本や読書人が現れ、私たちの価値観は常に知性を暴力よりも尊ぶものであり、いくら力が強くても知識がある方が上だと考えられてきました。今こそ、この認識を見直す時が来ました。
計算力の時代
人間の筋肉の力は非常に限られており、一日に5回食事をしても、少しの肉しか増えません。工学的な機械の力は非常に大きくできますが、できることは限られており、文明に必要なのは力よりも繊細さです。誰も「私たちの国には世界最大のクレーンがある」と誇ることはありませんし、クレーンの力にも限界があります。比較すると、知識は無限であり、上限なく使用できるため、知識を尊ぶのは理にかなっています。
しかし、現在、ある種の力は無限であり、その成長速度は知識の蓄積速度をはるかに上回っています。その力とは、コンピュータの計算能力です。
これは美的感覚や道徳とは関係なく、純粋に力の比較です。現状では、知識を頼りにするよりも、計算能力を頼りにする方が良いでしょう。
私が言いたい教訓は、計算能力こそが王道であるということです。
計算力の教訓
DeepMindにはリチャード・サットン(Richard S. Sutton)というコンピュータ科学者がおり、彼は「強化学習」このAIアルゴリズムの創始者の一人です。

2019年には、サットンが自身のウェブサイトに「苦い教訓」という記事を掲載しました。彼は、過去70年のAI研究が私たちに最大の教訓を与えたと言います。それは、計算能力を利用することが最も効果的な方法であるということです。
いくつかの歴史的事例を見てみましょう。
1997年、AIが国際チェスでガリー・カスパロフを破りましたが、当時多くの研究者は興奮するどころか失望しました。彼らの元々の考えは、人間のチェスの知識をAIに教え、AIが人間のプレイヤーのように考えることでした。しかし、予想に反して、大規模な深層検索のみを行う、純粋に計算能力に依存したプログラムが最終的に勝利しました。
これは理不尽ではないでしょうか?それ以来、チェスではこの方法が有効だが、囲碁では無理だろうと言われ続けました。囲碁は複雑すぎるからです……
20年後、AlphaGoが囲碁で人間の世界チャンピオンを破り、またしても暴力的な解決法を使いました。そのAIは囲碁の知識を理解していないどころか、何も学んでいませんでした。それにもかかわらず、人間に新しい囲碁の知識を提供しました。
音声認識の分野では、20世紀70年代には、人間の音声知識―単語、音素、声道など―をコンピュータに教える方法が主流でしたが、結局勝利したのはそのような知識を一切無視し、統計的な方法で自ら規則を発見するモデルでした。
コンピュータビジョンの分野でも、科学者たちは初めにいくつかの知識―グラフィックのエッジをどこで見つけるか、何が「一般的な円筒体」であるかなど―を発明しましたが、それらの知識は全く役に立たず、問題を解決したのは深層学習ニューラルネットワークでした。
今ではGPT言語モデルも同様です。以前の研究者が取り組んだ知識―構文分析、意味解析、自然言語処理(NLP)など―は全く使われず、GPTは膨大なコーパスを一通り学ぶだけで何でもできるようになりました。
無限の計算能力の前では、人間の知識は単なる小さな知恵に過ぎません。
サットンは歴史の法則を次の四つのステップでまとめました。
人間の研究者は常にAIにいくつかの知識を教えようとします。
これらの知識は短期的には常に役立ちます。
しかし長期的に見ると、これらの人間が構築した知識には明らかな限界があり、発展を制限します。
AIによる自己探索と学習の暴力的な解決法が、最終的には革新的な進歩をもたらしました。
計算能力こそが王道であり、知識はただの妨害です。
AI学習の類型
AIが暴力的に解決する方法はどのようなものでしょうか?以前、最も一般的な三つのニューラルネットワークアルゴリズムについて話しました:監視学習、非監視学習、強化学習。今、これら三つの「学習」方法を改めて考えてみましょう。
教師あり学習(supervised learning)は最も基本的なニューラルネットワークアルゴリズムであり、トレーニング素材にラベルを付けてAIに何が正しいかを知らせる必要があります。その役割は「判断」であり、目指すものは「是か非か」です。
たとえば、AIにたくさんの分子式から新しい抗生素の可能性があるものを判断させる場合、教師あり学習です。あらかじめ抗生素がどのようなものかを知っておく必要があり、そのためにはAIにトレーニング用の既存の例を提供する必要があります。
しかし、データ量が非常に大きい場合、トレーニング素材を一つずつ事前にマークするのは人間には困難です。そのために「自己教師あり学習(self-supervised learning)」という方法があり、AIに自分で答えを照らし合わせるようにします。たとえば、GPT言語モデルのトレーニングプロセスの一部は自己監視学習に属します。最も単純な考え方は次のようなものです:一つの記事を取り、まずその上半分をモデルに供給し、モデルに上半分に基づいて記事の下半分が何であるかを予測させ、その後、実際の下半分を見せて、フィードバックから学習させます。
自己教師あり学習はAIの生産性をさらに解放すると言えます。2023年8月、多くの研究者が「Nature」誌に共同でレビュー記事を発表し、現在のAIが科学的発見において果たしている一連の応用を列挙しました。その中で自己教師あり学習が大きな役割を果たしています。
以下の図は、AIが新薬開発に関与する過程を示しています。
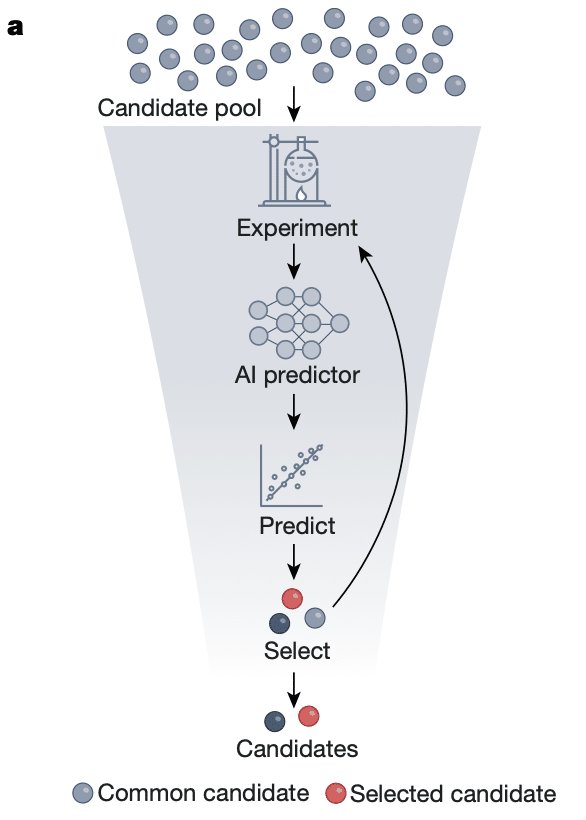
ここで研究者はまず、自己教師あり学習で基本的なAIモデルを訓練します。あなたの手元には、薬物の分子構造と実験結果のデータが大量にありますが、どの実験結果が求める薬物であるかをマークしていません。分子構造をAIモデルに一つずつ入力し、それが実験結果を予測させ、データの実際の実験結果と比較して、薬物構造と実験結果の関係について基本的な印象を持たせます。その後、マークされた少量のデータを使ってこの基本モデルを監視学習で微調整し、どの構造が求める実験結果を得る可能性が最も高いかを正確に判断するように学ばせます。最終的にAIは大量の候補をスクリーニングし、新薬となる可能性のあるものを判断できるようになります。
教師なし学習(unsupervised learning)はさらに強力であり、トレーニング素材に何の前処理も必要とせず、AIに何を求めているのかを伝える必要がありません。ただそのままAIに素材を供給すればよく、AIは素材の中の規則を自ら発見します。GPTが膨大なコーパスを学習できるのは、主に教師なし学習を使用しているからです。
教師なし学習は主に「生成」に使用され、「似ているかどうか」を追求します。GPTが記事を生成したり、Midjourneyが写真を生成したりするのは生成であり、甲骨文字の欠けた部分をAIに補完させるのも生成です。一小節の塩基対を与えてAIにタンパク質構造を生成させるのも生成です。生成型AIは多くのことを行うことができます。
強化学習(reinforcement learning)は、ある指標を最適化し、それらを一定の範囲内に保つことを目指し、「制御」の役割を果たし、「良いか悪いか」を追求します。囲碁を下す、自動運転、前回話した核融合プラズマの制御など、すべて強化学習です。
これらの方法の本質は、一定の入力と出力データを使用してニューラルネットワークを訓練し、そのニューラルネットワークを使用して新しい入力を読み取り、出力を生成することです。このプロセスでは、データのみに焦点を当てることができます:データがどの学問分野から来たのか、それらがどのような物理的意味を持つのかを気にする必要はありません……
2023年8月、マスクはテスラの最新版自動運転AI(FSD Beta V12)を披露しました。このバージョンの特徴は、プログラム全体に、AIに減速帯での減速、自転車の回避、交通信号の意味などを教えるコードが一行もないことです。システムにはいかなる交通ルールも注入されておらず、ニューラルネットワークが入力から出力まで全てを自ら理解しました。
これらの方法の詳細は非常に巧妙ですが、任意の学問分野の人間の知識と比較すると、これらは非常に単純な方法です。これらの方法が強力である根本的な理由は計算能力です:強力な計算速度と安価で大量のデータストレージがこれを可能にしました。
人間の単純性
計算能力のサポートを受けて、2022年末以降のGPTのパフォーマンスは、私たちに第三の教訓を与えました:人間は単純です。
GPT-3は1750億のパラメータを持っています。OpenAIは公表していませんが、ネット上ではGPT-4が1.8兆のパラメータを持っていると言われています。これらは間違いなく非常に大きな数字ですが、指数関数的に増加する計算能力の前では、これらは有限の数字です。そして、このように限られたモデルが、人類のほとんどすべての一般的な知識を捉えることができました。
GPT-4は人間の常識を持ち、写真を理解し、プログラミングや執筆を含む人間ができる多くのことを行うことができ、誰よりも多くのことを理解しています……私はそれがAGIであると考えています。それは言語モデルであり、コーパスで訓練されていますが、何とかして、言語の背後にある、言葉にできないものを捉えました。それは、私たち人間がまだ言葉で表現することができないものを言語で表現することができます。
AI言語、AI絵画、AI判断、AI制御は異なることを行っていますが、基本原理は同じです。なぜでしょうか?ウォルフラムの洞察によると、AIは「人間らしい」ものを捉えているだけです。
そして、これは「人間」が実際には単純であることを示しています。単純な計算能力であなたを理解することができるほどです。「人間」とは何でしょうか?私たちはAIを通じて人間に関する画期的な新たな理解を得ることができるでしょうか?
これは間違いなくより大きな可能性を意味していますが、私たちが現在見ることができるのは、近い将来に二つの展望があるということです。
AGIの参入
一つは、AGIがすべての分野で人間の仕事に参加することです。
現在、国内外の主流の企業は自社の大規模モデルを開発することに注力していますが、モデルの応用はまだほとんど展開されていません。これは現在のAI計算能力がまだ高価であり、GPTが一度に記憶できるユーザーのローカル情報が非常に限られており、強力なカスタマイズサービスを提供するのが難しいためかもしれません。
しかし、すでに取り組んでいる人もいます。一時的な方法としては、ローカル情報を「ベクトル化」する、つまりある程度圧縮して、GPTがより多くの情報を記憶できるようにする方法があります。しかし、より根本的な方法は、GPTをローカル情報で微調整することです。最近、OpenAIはGPT-3.5の微調整サービスを開放しました。
そのため、個人アシスタント、家庭医、個別指導のような、あなたに実際にカスタマイズされ、専門知識を持つAIサービスをすぐに見ることができるでしょう。それが本当に生活様式を変えるものです。
科学研究の変革
もう一つの展望は、すべての科学研究分野でAIを使用するべきであるということです。
DeepMindが行っていることは、基本的には手に大量破壊兵器を持ち、各科学研究分野に圧倒的な打撃を与えているようなものです。囲碁、ビデオゲーム、タンパク質の折りたたみ、天気予報、前述した核融合プラズマの制御など、広く報道されていること以外にも、最近ではAIを使用して2500年前に楔形文字で書かれたテキストの解読を助け、数学者が定理を証明するのを手伝い始めました……

DeepMindが進出できない分野はありますか?彼らが進出できないのではなく、まだ手が回らないだけです。DeepMindは、孟子が夢見た「王道」の師のように、「東を征すれば西夷が怨み、南を征すれば北狄が怨む」:彼らが生物学に向かうとき、物理学者は「なぜまだ私たちの問題を解決してくれないのか」と言い、彼らが考古学に向かうと、数学者は「私たちもAIを使えるはずだ」と言います!
歴史上、こんなことがあったでしょうか?
計算能力がまだ高価であり、ほとんどの人がAIの訓練方法をまだ学んでいないため、現在の状況は、AIを使える少数の人が科学研究のテーマを選んで取り組んでいます。しかし、次のステップは、すべての科学研究者が自らAIを使いこなすことです。大きな武器は必ず普及します。
もし私が理工科の大学院生なら、今すぐにでも自分でAIモデルを訓練する方法を学びます。ほとんどの人がまだ使いこなせない今、これはあなたがどの分野でも大きく活躍できる武器になるでしょう。
計算力の限界
世の中のほとんどすべての力の増大はすぐに限界効用の逓減に陥り、その結果、速度が遅くなったり、停止したりするため、上限があります。唯一、コンピュータの計算能力の増大は、現在まだ衰退の兆しはありません。ムーアの法則は依然として強力です。
もしこの世界に神がいるなら、計算能力こそが神です。この力を理解し、この力を受け入れ、この力となることです。
この記事が気に入ったらサポートをしてみませんか?