
第3章:学習状況のリアルタイムモニタリング

本記事は、「誰でも合格る!学習管理システムの構築と運用」の第3章である。

親記事は以下を参照:
第3章では第1章、第2章を受け、Ankiに蓄積された学習履歴をPowerクエリの機能を用いてExcelに取り出し、リアルタイムに可視化する方法について述べる。これは、学習のモチベーションアップへの貢献を目的としている。
なお、本記事は使用するパソコンとしてはWindowsを前提としている。また、友人の環境で下記方法で構築できることは確かめたが、あなたの環境で再現できないかもしれない。一部ソフトウェアのインストールが必要な箇所もあるため、もし興味があるが構築ができない方がいたら、ITに詳しい知人友人に頼ってほしい。それでもだめな場合は、筆者にご連絡いただければ可能な範囲でサポートしたい。
全体像
AnkiとSQLite、Powerクエリの連携
AnkiはデータベースにSQLiteを使っているため、クライアントソフトを用いることで直接データベースにアクセスすることも可能である。また、同ソフトを用いて学習履歴をCSV形式でエクスポートすれば、それをExcelに取り込むことも可能である。しかし、いずれも手数がかかり、面倒である。
PowerクエリはExcelの機能の一つで、データを外部ソースから取り込み、必要な整形を行うことができる。読み込んだデータはPowerピボットを用いることで集計表や、グラフに表現することができる。この外部のデータソースとしてSQLite(正確にはODBCを経由したSQLite)を指定することで、Excel上で「再読み込み」するだけで自動的に学習履歴が集計表やグラフに反映できるようになる。

なお、Ankiを起動した状態だとPowerクエリへデータが抽出されないため、集計時には一度Ankiを終了させる必要がある。
Ankiのデータベースの構造
Ankiのデータベースの構造は以下から参照できる:
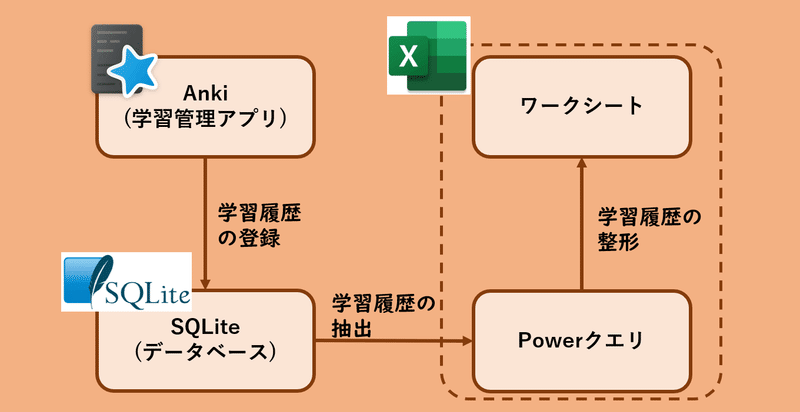
Cardsというテーブルで単語帳に登録したカードを管理し、それらの学習履歴はrevlogというテーブルで管理されていることがわかる。カードはデッキ(=単語帳)に所属することになるが、それはDecksテーブルで管理される。
第2章で説明した通り、Ankiでは各科目ごとに親となるDeckを作成し、配下に子Deckを作成する運用を想定している。したがって、親Deck単位でカードの学習履歴を取り出して集計するロジックを記述することになる。
SQLiteの操作
データ抽出クエリの作成
本項目は、SQL文を自分で作成する方法を紹介するものである。結果だけ必要であれば下記で紹介するPupSQLiteの導入などは不要であるため、次の節までスキップしてほしい。
以下、必要なデータ抽出クエリを作成するために、SQLiteを操作する方法を説明する。ここではPupSQLiteというアプリを使用している。
当該アプリから「開く」メニューでデータベースを指定する。Ankiではデータは通常C:\Users\【Windowsのユーザー名】\AppData\Roaming\Anki2\【Ankiのユーザ名】に格納される。「Ankiのユーザ名」は初期値では「ユーザ1」である。ここで、collection.anki2を指定するため、ファイル名の拡張子をAll filesに指定してから選択肢「開く」をクリックする。
その後、「SQL文入力」「クエリウインドウを開く」で以下のSQL文を書き、稲妻のアイコンを押せばSQLが実行され結果が表示される。
select * from Cards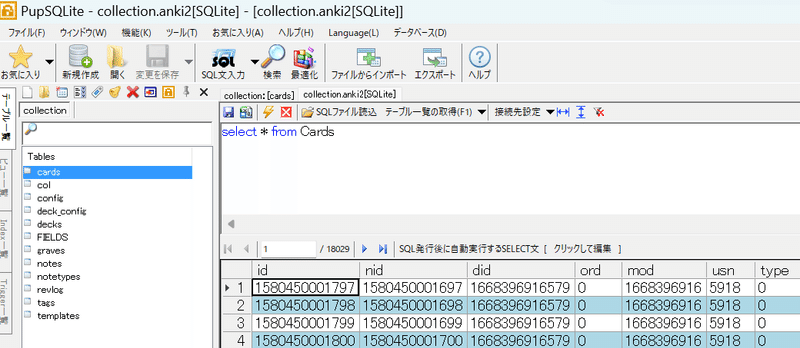
さて、今回は、あるDeck配下の子Deckに所属するすべての単語カードについて、その全ての学習履歴(いつどれだけの時間勉強したか)を抽出することとする。このSQL文は以下のようになる。
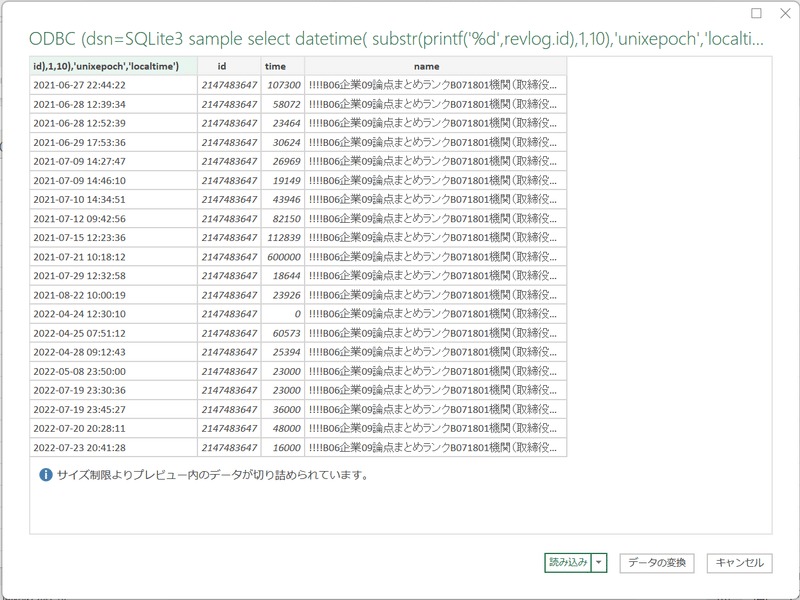
select datetime( substr(printf('%d',revlog.id),1,10),'unixepoch','localtime') ,
revlog.id,
time,
decks.name
from revlog
left join cards on revlog.cid = cards.id
left join decks on cards.did = decks.id
where cid in (select id from cards where did in (select id from decks where name like "%【親Deckの名前】%")) すると、以下の結果が得られる。
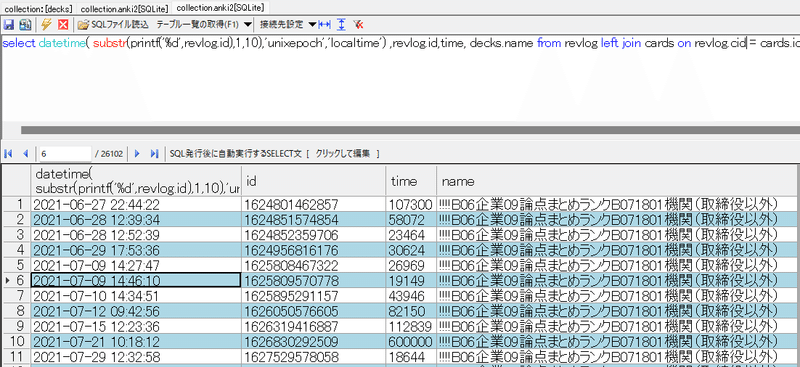
ここで先頭列は学習した日時を、id列は単語カードの学習が終了した時点の時刻(UNIX時間)を、time列は学習時間をミリ秒で、nameはDeck(親Deckから書き下したDeck名)を、それぞれ表す。
ここでデータ抽出に必要なSelect文が確かめられたので、PupSQLiteの操作は終了とする。なお、各科目ごとに学習時間を集計する処理はここで行うのではなく、Powerピボットで行うこととする。
SQLite ODBC Driverの設定
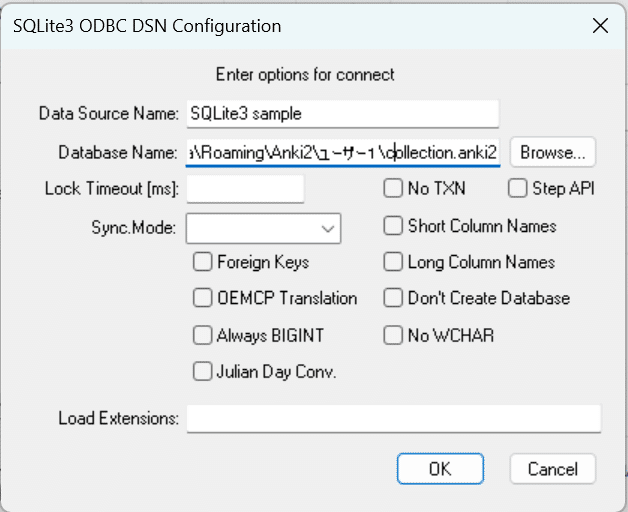
Powerクエリはデータソースとして直接SQLiteは選択できないが、ODBCを使用できる。従ってSQLiteのODBCドライバーを使用することとする。
導入の仕方は下記サイトを参考にした。
上記に従ってhttp://www.ch-werner.de/sqliteodbc/からドライバーファイルをダウンロード、インストールする。データソースの設定を以下のように行う。
PowerクエリとPowerピボットの操作
Powerクエリの設定
Excelを開き、「データ」「データの取得」「その他のデータソースから」「ODBCから」を選択する。
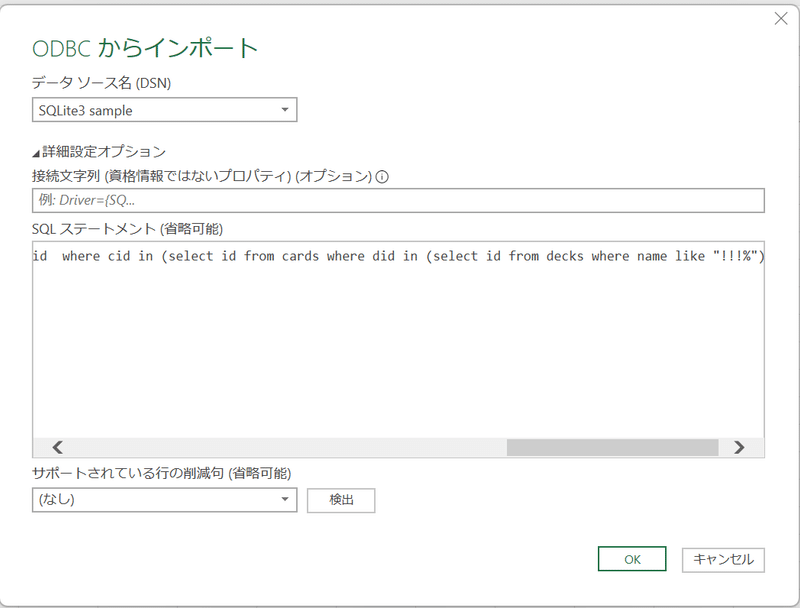
次の画面で「データソース名」を上記で自分で指定した名前(
ここでは「SQLite3 sample」)、SQLステートメントに上記で作成したselect文を指定して「OK」クリック。
続く画面ではユーザ名に適用な文字列(ここではuser)を指定(この値は以後使用しないので忘れてよい)し「接続」をクリック。
次の画面で「データの変換」をクリック。
すると、Powerクエリエディタが開く。
Powerクエリエディタの設定
ここからSQLiteから抽出されたデータを整形する。具体的には以下を行う。
時間帯を表す列の作成
日付を表す列の作成
科目を表す列の作成
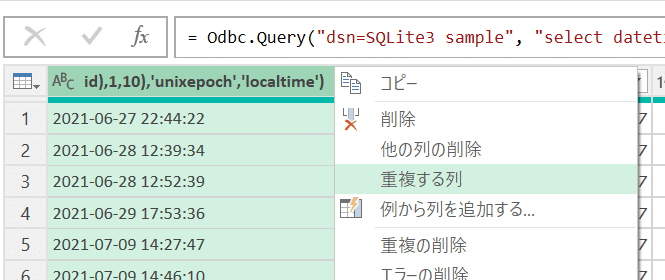
時間帯を表す列とは、たとえば朝8時に学習した履歴には「08」を、夜10時に学習した履歴には「22」を与える列である。この列は、先頭の列をコピーして整形することで作成する。先頭の列のヘッダーで右クリックし、「重複する列」を選択。
コピーされた列を選択肢、「変換」タブから「抽出」「範囲」を選択。
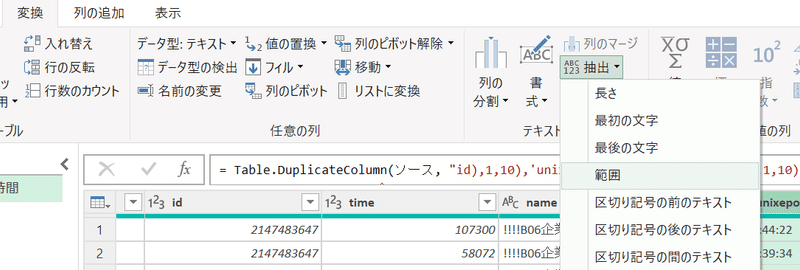
次のウィンドウで11、2を入力し「OK」クリック
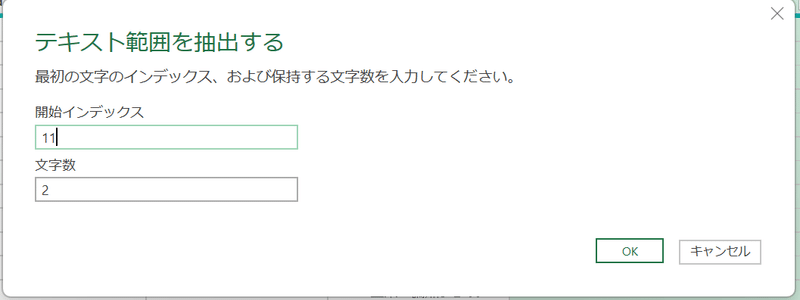
これにより、時間帯の情報のみを取り出せた。最後に列名を変更するため、ヘッダーをダブルクリックし、hourと入力しEnterキー押下。

次に、日付を表す列を作成する。これも時間帯と同様、先頭列を加工して作成する。最初の列を選択肢、「変換」タブから「抽出」「最初の文字」を選択、次のウィンドウで「10」と入力し「OK」をクリック。
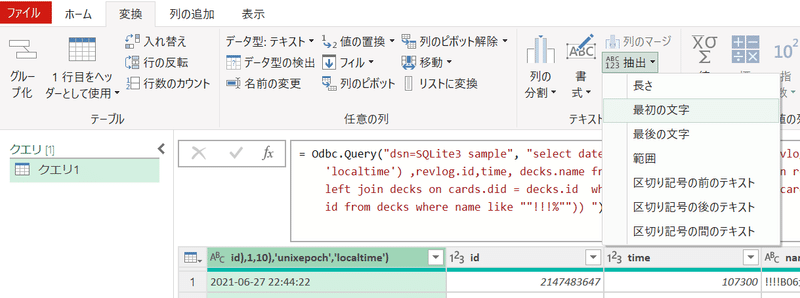
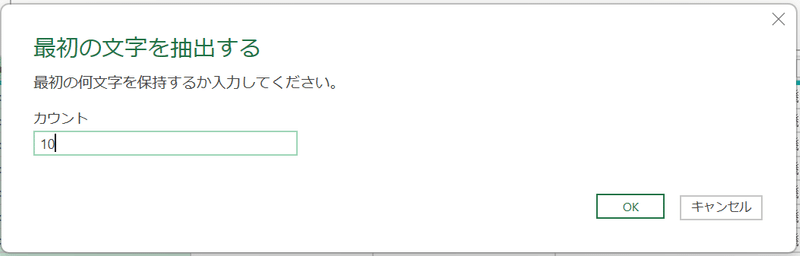
すると、日付の値のみとなる。
なお、日付を抽出するにあたって、Select文と当該ステップの両方の手順で日付データを抽出しており、もっと簡単な方法があるかもしれない。
次に、現在文字列として扱われているこの列のデータ型を日付型に変更する。列名の左の「ABC」と書かれたところをクリックし、「日付」を選択。すると日付型に変更される。
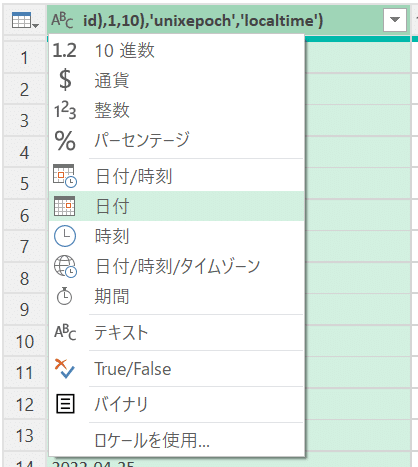
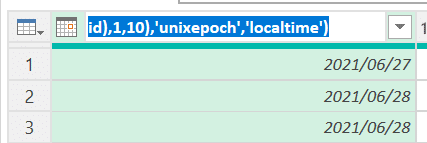
次に、当該列の列名をシンプルにする。列のヘッダー部をダブルクリックし、「date」と入力しエンターキーを押下。
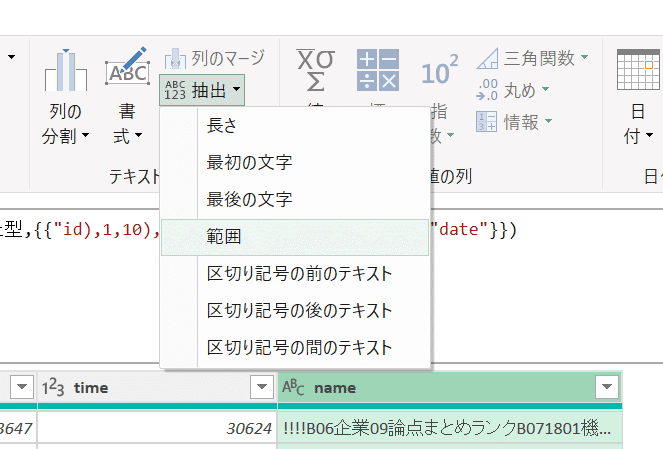
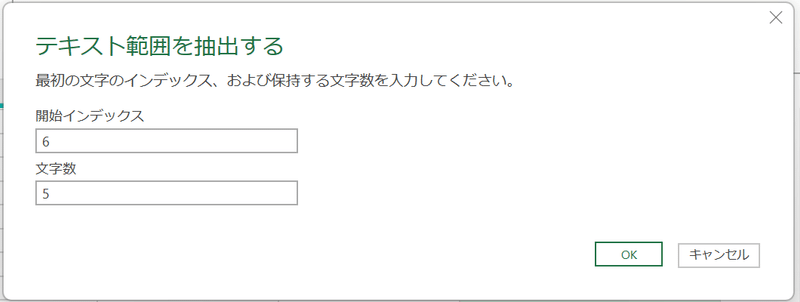
最後に、name列から集計する単位となる科目名を取り出す。Deckの設定により異なるが、ここでは、先頭から6文字目からの5文字を取り出す。「編集」タブから「抽出」「範囲」をクリックし、「6」「5」を入力し「OK」。これで、科目名だけが抽出される。
最後に、「クエリの設定」で名前を適当なものに変更する。

これはPowerピボット等の操作画面表示される。
以上で終了である。最後に「ホーム」タブから「閉じて読み込む」「閉じて次に読み込む」を選択する。

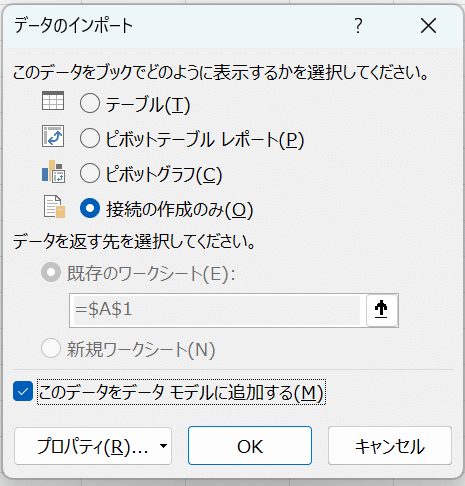
ここでPowerクエリエディタウインドウが終了となるが、最後に「データのインポート」で「接続の作成のみ」を選択し、「このデータをデータモデルに追加する」にチェックを入れる。
「接続の作成のみ」とすると読み込まれたデータはワークシート上に読み込まれない。個人規模の学習データでは問題ないが、場合によっては100万行以上の履歴データを扱う場合に、ワークシートの仕様上104万行までしか扱えない制約があるが、これを選ぶことで回避できる。また、データモデルに追加することで、Powerピボットの機能で当該データを処理できることとなる。
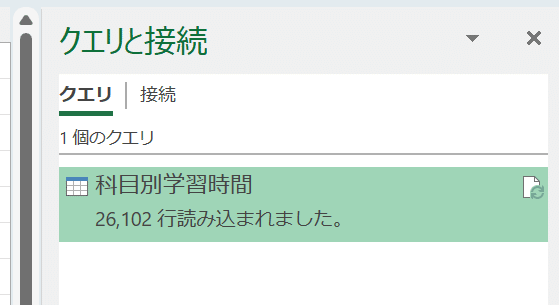
「クエリと接続」欄に、上で変更したクエリ名(ここでは「科目別学習時間」)が表示される。
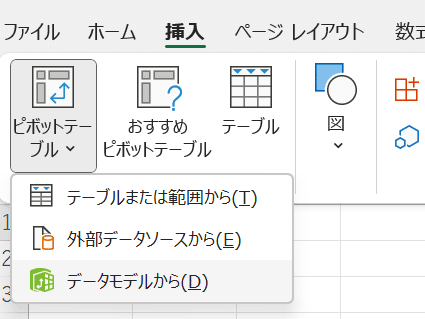
Powerピボットの設定
データモデルからピボットテーブルを作成する。「挿入」タブから「ピボットテーブル」「データモデルから」を選択。ピボットテーブルを作成したシートを選択して「OK」クリック。
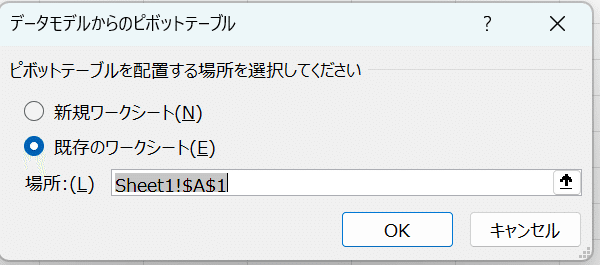
「ピボットテーブルのフィールド」が表示される。上で設定したクエリ名を展開すると、列名が表示されていることがわかる。
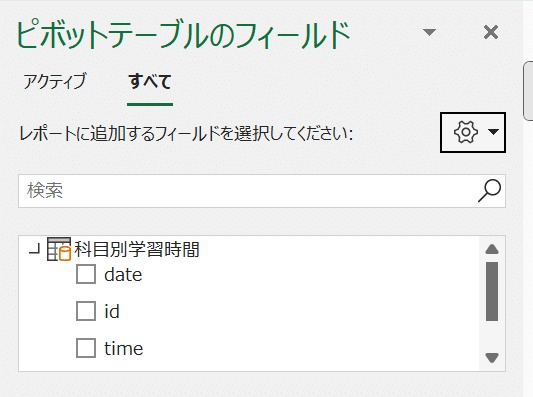
ここで、dateをフィルターに、nameを行に、hourを列に、timeを値に持っていく。
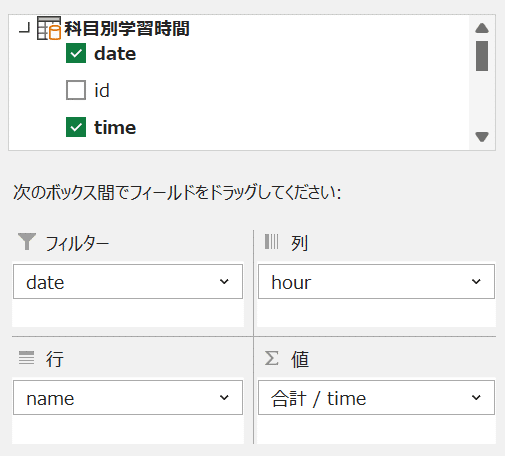
すると、集計表が表示される。
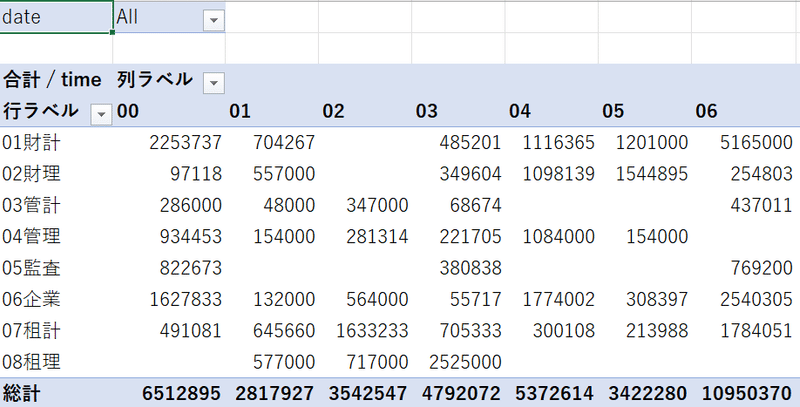
しかし、ミリ秒単位なので分かりづらい。ここで、メジャーを作成することとする。メジャーとはPowerピボットにおいて自分で設定できる計算式である。クエリ名で右クリックし、「メジャーの追加」を選択。
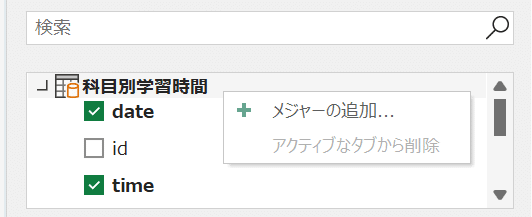
メジャーの名前は適当なものを指定し、数式には以下を記入する。
=sum([time])/1000/60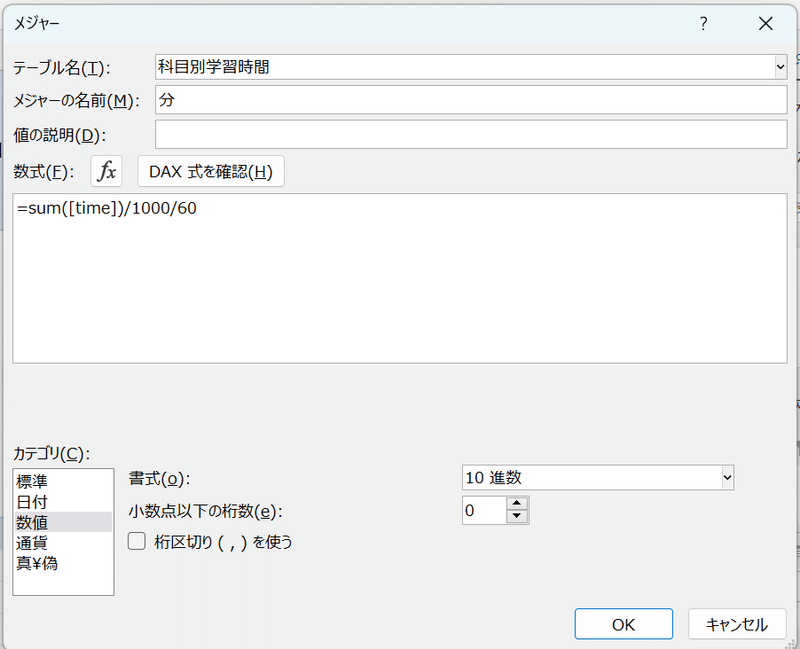
作成したメジャーがクエリの最後に表示されるので、timeと入れ替えて値欄に指定する。
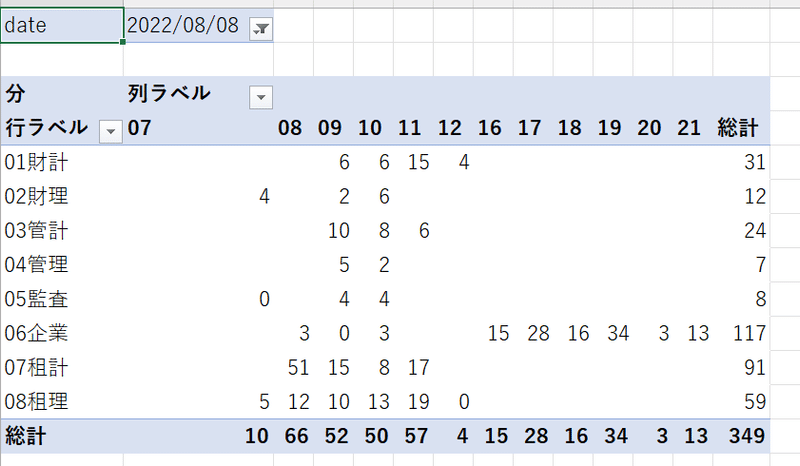
すると、集計表が分単位で表示される。
この集計表のセルを右クリックし、「更新」を選択するとSQLiteからその時点のデータが抽出され、Powerクエリで整形され、Powerピボットで集計されることになる。
なお、Ankiを立ち上げている場合は一度Ankiを終了させる。
補足
学習管理のあるべきKPIとは
ここまで、時間帯別に学習時間をリアルタイムに補足する方法について説明してきた。これは、あえてビジネスの文脈で捉え直すと、資格試験合格のためのKPIとして<時間帯別の学習時間>を採用しているからである。
たとえば一日の学習時間を計測する学習者が多い。一日の学習時間だけであれば上記のような面倒な手順(といっても一度設定すればよいだけだが)を取る必要はなく、Ankiであれば標準機能(統計)を用いればよい。しかしこれには以下のような難点があると思っている。
標準的な一日あたりの学習時間が設定しづらい
修正のタイミングが遅い
一点目については、学習に専念できる方にとっては問題ないかもしれないが、社会人の学習者を念頭におくと、たとえば平日は3時間、休日は8時間、などと曜日によって違う値を設定するだろう。さらにどうしてもしなければならない残業、家族がいれば家族の対応など管理が困難な要素があるため、平日3時間など固定的にKPIの値を設定すれば達成が難しくなるケースも多くなり、状況に応じて設定すれば管理の手間がかかる。こうした点で適切な指標ではないのではないか。
二点目については、一日の終りに学習時間の測定を終え、設定した時間に満たなかったときに、スマフォをいじってしまったな等課題を洗い出して翌日での修正を図るが、これではその日のよくない状況はもう取り返しがつかない。振り返りの頻度が一日の最後一回だけでは課題修正が遅延するのである。
KPIの適切な設定の難しさについては、管理会計論が教えるところでもある。
こうした点から、時間帯ごとの学習時間(たとえば50分)をKPIとすることのメリットが浮かび上がるのではないか。時間帯という枠での学習時間であれば管理不可能性の余地は少なくなるだろう。一時間毎、もっと言えば随時の学習時間計測はモチベーションを高く維持することに役立つだろう。
科目別勉強時間のバラツキ平準化
また、今回作成した集計表は、時間帯別に加えて科目別にも集計している。これは、もともとは結城浩氏の「色つき星取表」に影響を受けたアイデアである。
プロジェクトごとに着手したがんばりに応じて色を付けるとともに、着手したプロジェクトを端に移動することで、未着手のプロジェクトが洗い出されるという考え方である(野口悠紀雄氏の押し出しファイリング法に似ている考え方である)。
この考え方は資格試験の学習にも役立つだろう(プロジェクトが科目に相当する)。第1章では、「<科目>の枠で学習しない」ということを述べたが、科目毎に実績を測定するのはこれに反するように見えるが、そうではなく、むしろ科目の偏りを防止するための工夫である。
我々はついつい苦手科目・得意科目の意識に囚われ、苦手科目のビハインドを得意科目でフォローするような戦略を立てがちであるが、おそらくはそうではなくて、どの科目も平均的に学習する、正確に言うとどの科目も優先度Aの学習要素を確実に得点できるようにする、というような学習戦略が望ましいと思われる。とくに苦手科目の意識がある場合は学習から避けがちである。日単位で科目別に学習時間を計測することは学習時間の平準化に役立つのである。
この場合はPowerピボットの列を上記で説明したhourでなくてdateを使えばすぐに可視化できる。
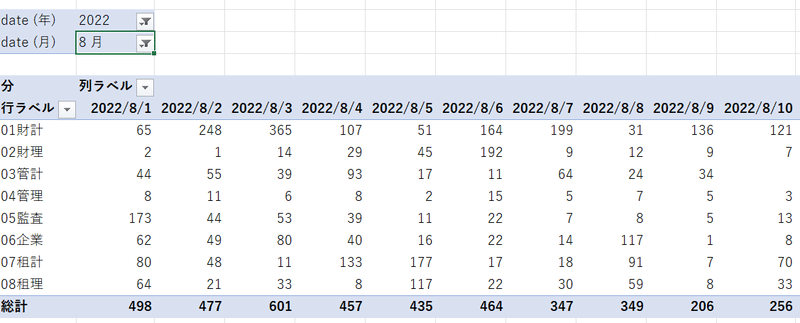
以上、参考になれば幸いです。
この記事が気に入ったらサポートをしてみませんか?