応答時間・精度・マシンパワーのトレードオフ【AIサービス実行インフラ】

はじめに
運用しやすいAIサービスを作るためには精度だけを高めるのではなく、応答時間とマシンパワーのバランスをとることが必要であることを示します。
レイテンシー・精度・マシンパワーの関係
レイテンシとマシンパワーの関係
「時間 = 量 / 速さ」のアナロジーより、以下の式が成り立ちます。
応答時間[s] ⤴ 計算量[IPS] / マシンパワー[IPS/s] ・・・ A
※計算量の単位は仮にIPS(Instructions Per Second)としましたが、計算量を表現できる単位なら何でもよいです。特定環境での実行時間[s]など。
※ ⤴ は単調増加の意。一般的な数学表記法ではなく、本記事独自のものです。=や∝だと厳密性に欠けるので、代わりに簡潔な表現として定義しました。この例では、計算量が増えると応答時間が長くなる、マシンパワーが上がれば応答時間は短くなる、程度の意味です。
この式が意味するところは、計算量が同じならばマシンパワーを大きくすればより少ない時間で計算が終わるということです。
例えば、CPUのスレッド数(マシンパワー)を2倍にすれば、処理時間は約半分で計算できます。
(なお、現実の処理には並列処理できない部分が存在するので単純に処理時間が半分にはなりませんが、アダマールの公式を使うとシステムの並列度も考慮して推定できます。)
精度と計算量の関係
機械学習モデルの精度と計算量には、経験的に以下の式が成り立ちます。
精度 ⤴ 計算量[IPS] ・・・ B
※精度は正確度・適合率・再現率など使える指標が様々ありますが、簡単のため一括りに「精度」としました。
この式が意味するところは、計算量を大きくすれば精度を高めやすいということです。
例えば、画像認識モデルは画像サイズが大きいほど認識精度を上げやすいです。 画像サイズが大きい、つまり解像度が高いほど認識対象の細かな部分を表現できるためです。ただし画像サイズが大きいほど計算量は増えるので、たとえば画像サイズを大きくして1辺を2倍にすると、ピクセル数つまり計算量は4倍になります。
精度・マシンパワー・応答時間のトレードオフ
式「A」「B」より、以下の式が得られます。
精度 ⤴ マシンパワー×応答時間
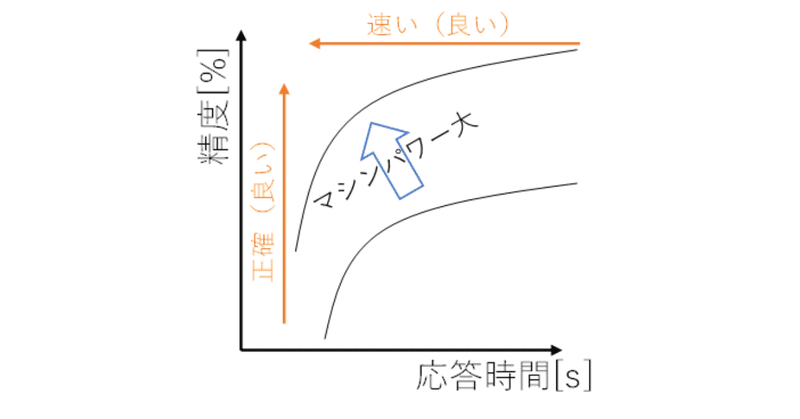
図にすると以下のような関係です。
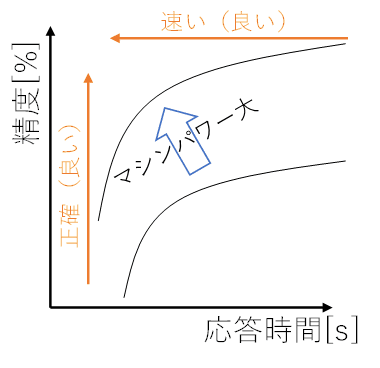
ポイントは以下の点です。
座標の左上に近いほど、「精度が高く」「応答時間の短い」良いモデルであることを意味します。
精度と応答時間はトレードオフの関係にあります。精度を上げようとすると応答時間が長くなってしまい、応答時間を短くしようとすると精度が下がってしまいます。
マシンパワーの大きいマシンで推論する場合、プロットは左上にシフトして、精度・応答時間は高性能になることが期待されます。
トレードオフの例
以下はYOLOv8の精度・応答時間のトレードオフの例です。
参考 https://github.com/ultralytics/ultralytics

以下のことがわかります。
青い実線がYOLOv8の様々なサイズのモデルの性能を示しています。
「n」(nano)サイズは応答時間が速い代わりに精度が低く、「x」(X large)サイズは応答時間が遅い代わりに精度が高いことがわかります。
YOLOバージョンが上がるたびにグラフが左上へシフトしていて、全体的な性能が改善していることがわかります。
グラフには記載がないですが、もしこの環境よりマシンパワーの高いハードウェア・設定で実行すれば、グラフはさらに左上にシフトすると思われます。
マシンパワー別 実行インフラの選択肢
AIサービスにおいてマシンパワーを考慮する必要があるのは、マシンパワーが小さいほどマネージドレベルの高い、低コストで運用の楽な実行インフラを選択できるためです。
マシンパワーごとに以下のような実行インフラの構成が考えられます。

※Azure Container Instancesは「GPU コンテナーグループ」機能でGPUが利用できますが、プレビュー版であり、仮想ネットワークへのデプロイも利用できないので想定しませんでした。(2024/01/23)
参考 https://learn.microsoft.com/ja-jp/azure/container-instances/container-instances-gpu
※Azure AI Vision(OCR、顔認識機能などが利用できる)のようなクラウドサービスを利用する選択肢もありますが、自社開発した任意のモデルを利用することはできないので除外しました。
「クライアント側で推論」は過去記事が参考になるかもしれません。
主要な選択肢は、FaaS・CaaS・IaaSで、経験的には以下のような判断基準になると思われます。
テーブルデータのような小規模の推論が必要な場合 → 1スレッド程度のFaaS
4K程度の画像を5秒程度で処理する場合 → 複数スレッドが利用できるCaaS
それ以上のマシンパワーが必要な場合 → GPUの利用できるIaaS
備考:インフラのマネージドレベル
マネージドレベルが高いほど、インフラの管理などをクラウドベンダーにお任せできて運用が楽になるため、なるべくマネージドレベルの高いインフラを使いたい事情があります。

精度・マシンパワー・応答時間のバランス
必要なマシンパワーが小さいほどマネージドレベルの高い魅力的なインフラを選択できることがわかりました。しかし、精度と応答時間が良い方が、AIサービスは魅力的になります。
そこで、実際のAIサービスでは、精度・マシンパワー・応答時間の現実的なバランスを探す必要があります。
精度
高いほど良いですが、精度を高めると応答時間が遅くなり、 大きなマシンパワーが必要になりがちです。 そこで、ユーザ体験の低減が少ない範囲でどの程度まで精度を落とせるかを考える必要があるかもしれません。
例えば…
専門家が介在せずにエンドユーザーがクリティカルな判断に使うなら、精度99%が必要かもしれません。
人間の補助程度の用途であれば、精度80%でも有用かもしれません。
応答時間
どの程度までの遅延が許容できるかを考える必要があります。
AIサービスの利用手順によって、大きく変わってくる部分でしょう。
例えば…
推論を開始してから画面に表示されるまでユーザが待機するなら、応答時間は数秒以内にする必要があるでしょう。
アプリケーションに入力してから、バックグラウンドで推論処理して、ユーザーが後でまとめて結果を確認するなら、応答時間は60秒以上も許容できるかもしれません。
まとめ
精度・マシンパワー・応答時間にはトレードオフがあり、マシンパワーが低ければ運用コストを抑えられます。そのため、全体のバランスを見てちょうど良いマシンパワーに収まるような精度と応答時間を要件定義する必要があります。
サービスの要件定義では精度と応答時間を求めすぎないようにすることで、運用のしやすいサービスに仕上げることができるでしょう。
この記事が気に入ったらサポートをしてみませんか?