
音解析AIのためのDeep Learningの訓練データのアノテーションツールをElectron, React, Pythonを組み合わせて自作してみる

画像・動画のアノテーションツールは有料・OSSなど見つかりますが、訓練データ整形前は時間軸が異なる音のデータ(波形、スペクトログラムなど)に対して使いやすいツールが見つからないので自作してみようというものです。
Electron+React
そもそも何故ネイティブアプリなどではないかというと、Webサービスで使うReactコンポーネントを共用出来たらいいなということが出発点でした。
単なるWebアプリですとローカルのファイルが扱いにくい点と、Webサービスとして起動するのもなという点と、ハードウェアの都合からマルチプラットフォームがいいなという点からElectronを選択しました。
それに加えて、前述のWebサービス用に作成したReactコンポーネントのNPMパッケージを使えたらいいなということでReactとの組み合わせにしました。
Python
Pythonは単純にオーディオファイルの解析ライブラリ(librosaなど)が使いやすいのでElectronのメインプロセスから呼び出して使うという組み合わせにしました。当初はPythonのみでUIもJavaScriptを駆使して作ろうかと思いましたが、少し進めたら単純に面倒だと感じたのと、後からのメンテナンス性も考えて解析部分だけ使うことにしました。
逆にファイル読み込み後は全てJavaScript (TypeScript) で解析を実装しようかと少し進めましたが、そこまですることは無いなと思い直しました。
そして、解析部分のみPythonで実装することでDeep Learningのモデル構築の一部も共用出来ました。
全体構成

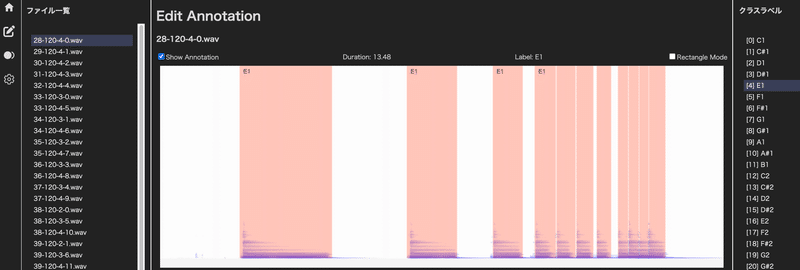
ある程度実装した状態
自作するとキーボードショートカット(操作性)や、範囲選択モードや矩形モードなど自由に作れるのがいいですね。

出来れば実現したい機能
オーディオインターフェイスの選択や入力・録音も試しましたが、レンダラープロセス上で実現しようと思ったらWeb Audio API (getUserMedia) の仕様に左右されてしまうので、オーディオインターフェイスの性能を使えないのが不満です。なので、メインプロセス経由で柔軟に出来るようにすれば使いやすくなるのではと考えています。
この記事が気に入ったらサポートをしてみませんか?