
国土数値情報のバス停留所データの整理方法を公開します!

はじめに
2023年4月、2022年の国土数値情報バス停留所データが公開されました。それ以前のデータとしては2010年のデータが公開されて以来なので、およそ12年ぶりとなります。バスのGISデータというと近年整備が進んでいるGTFSがあります。GTFSは交通機関のGISデータに特化したフォーマットということで経路番号やダイヤを載せられるようになっていたりととてもうまくできています。一方で各事業者ごとに整備されているということもあり、品質にばらつきがあったり全国を網羅していなかったりというのが現状です。
品質が一定程度保たれていおり全国を網羅しているという点では国土数値情報にも有用性がありそうです。ただしこのデータもフォーマットの制約のためか、ちょっとおかしなカラム構成になっていて扱いにくい状態なのです(後述)。そこで今回はこのデータを扱いやすい形式に変換する方法をスクリプトとともに公開します。
この記事では主にPostgreSQLとそれに付属する地理拡張ツール、PostGISを使います。PostGISはOSによってインストール手順が異なりますので公式サイトのインストール手順などを参考にしてみてください。
国土数値情報とは
国土数値情報とは、国土交通省が運営する国土計画の策定や実施の支援のために整備されたデータです。国土数値情報ダウンロードサイト(以下、このデータおよびダウンロードサイトを国土数値情報と呼びます。)では地形、土地利用、公共施設などの国土に関する基礎的な情報をGISデータとして無償で入手することができます。
データの課題と整理方針
配布されているシェープファイルの中身を見ると、"p11_003_01"のカラムにカンマ区切りで複数のバス系統名が入っています。このままだと、たとえば、A系統に所属する一連のバス停を抜き出したい場合にA系統、B系統、C系統から単純にフィルターをかけ選択する、ということができません。

そこで今回は上記ファイルを以下の方針で整理することにしました。
レコードには事業者名、バス系統名、バス停留所名、バス区分コードのカラムをもたせる
1つのバス停留所に複数のバス事業者あるいはバス系統が乗り入れている場合、それらは別々のレコードとして登録する
ここからは整理方法を順を追って説明していきます。
実行環境
今回は以下のツールを使いました。各ツールの設定方法などは公式ドキュメントなどを参考にしてください。今回の記事は基本的なSQLとGISの知識があると各ステップで何をやっているかわかると思います。
Ubuntu 22.4
PostgreSQL 14.9
PostGIS 3.4
shp2pgsql
QGIS 3.28
整理手順
バス停データを入手
まずは国土数値情報ダウンロードサイトのバス停留所のページから任意の都道府県のデータをダウンロードします。この時、形式はシェープ・geojson形式のものを選んでください。今回は例として茨城県のデータを使うことにします。
茨城県のデータを入手すると以下のような構成になっています。
P11-22_08/
├── KS-META-P11-22_08.xml
├── P11-22_08.cpg
├── P11-22_08.dbf
├── P11-22_08.geojson
├── P11-22_08.prj
├── P11-22_08.shp
└── P11-22_08.shxPostgreSQLの準備
ここでPostgreSQLにDB名をmydb、スキーマ名をksjとしてデータベースの準備をしておきましょう。ここではPostGIS拡張もDBに作成しておきます。
psqlまたはpgAdminなどのDBクライアントから以下のSQLを実行します。
create database mydb;
create extension postgis;
create schema ksj;shp2pgsqlでPostgreSQLにデータを取り込む
shp2pgsqlはシェープファイルをPostgreSQLに取り込むためのコマンドラインツールです。PostGISに付属していますので、特別インストールなどは必要ありません。
ダウンロードしたファイルに対して、ターミナルで以下のコマンドを実行します。P11-22_08.shp は茨城県のシェープファイルです。他県のファイルを実行する場合はファイル名を変更してください。
shp2pgsql -W CP932 -s 6668:4326 -D -I P11-22_08.shp ksj.bus_stops_raw > ksj.bus_stops_raw.sql上記のコマンドを実行するとksj.bus_stops_raw.sqlというファイルが生成されます。このファイルを以下のコマンドでPostgreSQLに取り込みましょう。mydbにksj.bus_stops_rawテーブルが作成されます。
psql -U postgres -d mydb -f ksj.bus_stops_raw.sql取り込んだデータを確認する
シェープファイルのデータがテーブルに取り込まれたはずなので、確認してみます。
select * from ksj.bus_stops_raw;
無事、バス停留所ひとつひとつの属性情報が取り込めたようです。しかしここで冒頭述べた問題、データフォーマットに起因するであろう不自然なカラム構成に直面します。バス系統名がひとつのカラムにカンマ区切りで複数入っているのです。しかも国土数値情報のバス停留所のページの属性情報についての項を読むと、バス系統名の入っているカラムは35列分あるとのこと(shp属性名がカラム名。バス系統はP11_003_01~35、とある)。バス事業者の区分を表すバス区分コードも同様のようです。このままではちょっと使いにくそうです。
バス系統名とバス区分コードを整理する
今回は冒頭で述べた通り、以下の方針で整理することとします。
レコードには事業者名、バス系統名、バス停留所名、バス区分コードのカラムをもたせる
1つのバス停留所に複数のバス事業者あるいはバス系統が乗り入れている場合、それらは別々のレコードとして登録する
さっそくテーブルを作り替えます。まずは問題のバス系統名、バス区分コードをバラして新しいテーブルに投入することにします。同時にカラム名もわかりやすくしておきましょう。以下のSQLを実行してください。
drop table if exists ksj.bus_stops;
create table ksj.bus_stops as
select
p11_001 as bus_stop,
p11_002 as operator,
unnest(
regexp_split_to_array(p11_003_01, ',') || regexp_split_to_array(p11_003_02, ',') || regexp_split_to_array(p11_003_03, ',') || regexp_split_to_array(p11_003_04, ',') || regexp_split_to_array(p11_003_05, ',') ||
regexp_split_to_array(p11_003_06, ',') || regexp_split_to_array(p11_003_06, ',') || regexp_split_to_array(p11_003_07, ',') || regexp_split_to_array(p11_003_08, ',') || regexp_split_to_array(p11_003_10, ',') ||
regexp_split_to_array(p11_003_11, ',') || regexp_split_to_array(p11_003_12, ',') || regexp_split_to_array(p11_003_13, ',') || regexp_split_to_array(p11_003_14, ',') || regexp_split_to_array(p11_003_15, ',') ||
regexp_split_to_array(p11_003_16, ',') || regexp_split_to_array(p11_003_16, ',') || regexp_split_to_array(p11_003_17, ',') || regexp_split_to_array(p11_003_18, ',') || regexp_split_to_array(p11_003_20, ',') ||
regexp_split_to_array(p11_003_21, ',') || regexp_split_to_array(p11_003_22, ',') || regexp_split_to_array(p11_003_23, ',') || regexp_split_to_array(p11_003_24, ',') || regexp_split_to_array(p11_003_25, ',') ||
regexp_split_to_array(p11_003_26, ',') || regexp_split_to_array(p11_003_26, ',') || regexp_split_to_array(p11_003_27, ',') || regexp_split_to_array(p11_003_28, ',') || regexp_split_to_array(p11_003_30, ',') ||
regexp_split_to_array(p11_003_31, ',') || regexp_split_to_array(p11_003_32, ',') || regexp_split_to_array(p11_003_33, ',') || regexp_split_to_array(p11_003_34, ',') || regexp_split_to_array(p11_003_35, ',')
) as route,
unnest(
regexp_split_to_array(p11_004_01, ',') || regexp_split_to_array(p11_004_02, ',') || regexp_split_to_array(p11_004_03, ',') || regexp_split_to_array(p11_004_04, ',') || regexp_split_to_array(p11_004_05, ',') ||
regexp_split_to_array(p11_004_06, ',') || regexp_split_to_array(p11_004_06, ',') || regexp_split_to_array(p11_004_07, ',') || regexp_split_to_array(p11_004_08, ',') || regexp_split_to_array(p11_004_10, ',') ||
regexp_split_to_array(p11_004_11, ',') || regexp_split_to_array(p11_004_12, ',') || regexp_split_to_array(p11_004_13, ',') || regexp_split_to_array(p11_004_14, ',') || regexp_split_to_array(p11_004_15, ',') ||
regexp_split_to_array(p11_004_16, ',') || regexp_split_to_array(p11_004_16, ',') || regexp_split_to_array(p11_004_17, ',') || regexp_split_to_array(p11_004_18, ',') || regexp_split_to_array(p11_004_20, ',') ||
regexp_split_to_array(p11_004_21, ',') || regexp_split_to_array(p11_004_22, ',') || regexp_split_to_array(p11_004_23, ',') || regexp_split_to_array(p11_004_24, ',') || regexp_split_to_array(p11_004_25, ',') ||
regexp_split_to_array(p11_004_26, ',') || regexp_split_to_array(p11_004_26, ',') || regexp_split_to_array(p11_004_27, ',') || regexp_split_to_array(p11_004_28, ',') || regexp_split_to_array(p11_004_30, ',') ||
regexp_split_to_array(p11_004_31, ',') || regexp_split_to_array(p11_004_32, ',') || regexp_split_to_array(p11_004_33, ',') || regexp_split_to_array(p11_004_34, ',') || regexp_split_to_array(p11_003_35, ',')
) as category,
geom
from ksj.bus_stops_raw;上記のSQLではカラム名を以下のように変更しています。

ここでidも振っておきましょう。
alter table ksj.bus_stops add column id serial;
alter table ksj.bus_stops add primary key (id);これでテーブルは完成です!
整理後のテーブルを確認する
テーブルの中身を見てみます。
select * from bus_stops;バス停留所名、事業者名、バス系統名、バス区分コードがひとつづつのカラムに分かれて入りましたね!

各カラムのユニーク値の数も取得してみましょう。
select count(distinct id) as id, count(distinct operator) as operator, count(distinct route) as route, count(distinct bus_stop) as bus_stop from ksj.bus_stops; 
レコードの数としては22,988件あるようですが、バス停留所としては6,604ヶ所のようです。同じ地点に複数の系統が乗り入れている場合には別々のレコードとして整理しているので、うまくできていそうです。
シェープファイルに出力する
PostgreSQLからファイルにエクスポートして変換を終わりとしましょう。最初にシェープファイルをインポートしたshp2pgsqlにはエクスポートの機能、pgsql2shpもついています。ターミナルで以下のコマンドを実行してください。(各種オプションは適宜読み替えてくださいね)
pgsql2shp -u postgres -P postgres -f bus_stops.shp mydb "select * from ksj.bus_stops"bus_stops.shpというシェープファイルが出力されれば完了です。
可視化してみる
最後に出力したシェープファイルを確認してみましょう。QGISでバスの停留所をプロットしてみます。せっかくなので整理した系統名で色分けすることにします。なお本題とは離れるので詳しい方法は述べません。QGISの詳しい使い方を知りたい方はGIS実習オープン教材QGISビギナーズマニュアルなどをご覧になってください。
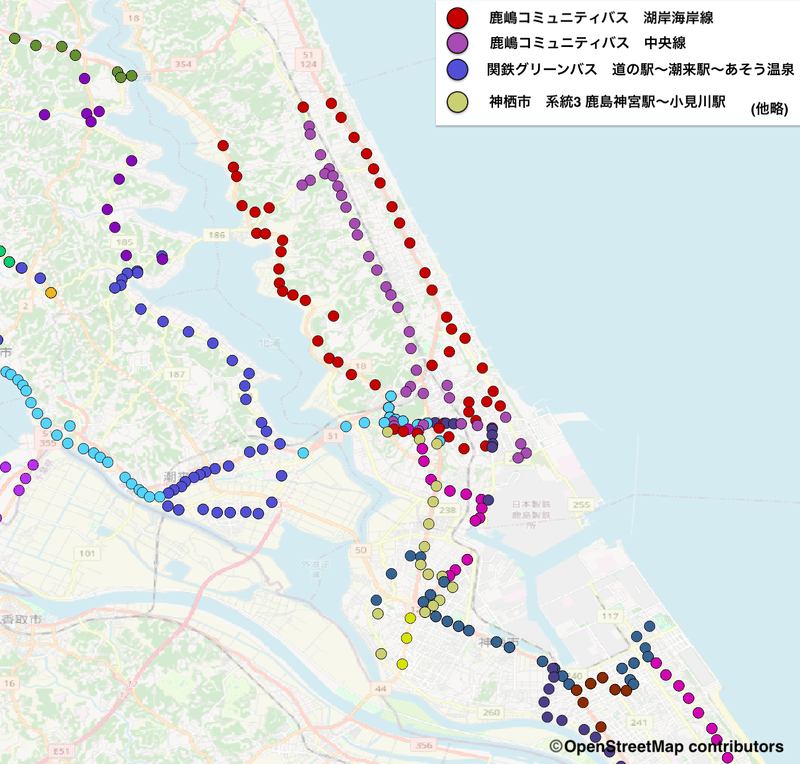
「国土数値情報(バス停留所データ)」(国土交通省)を元にLocationMind株式会社作成
きれいに系統ごとにバス停留所が色分けされましたね!
さいごに
今回は国土数値情報のバス停留所データの整理手順を紹介しました。さらなるデータの整備と利活用が広がるとうれしいです。ぜひ活用してみてください!
データの出典
この記事で取り扱ったデータは以下のとおりです。
出典:「国土数値情報(バス停留所データ)」(国土交通省)(2023年10月取得)