
Pythonを用いた機械学習7日目

ーー高校や大学を受験するとき、希望する学校の偏差値を調べたことがある。当時はなんとなく、偏差値50を超えたら高く、50以下であれば低いというようなざっくりとしたイメージだった。
分散や標準偏差を使うときに気をつけなければならないのは、単位を変えると値が大きく変わるところだ。単独では意味がなく、複数のデータを比べるときに分散や標準偏差を「標準化」(①)する。また、分散や標準偏差を求めるときには、データの分布(②)をイメージすることも大事である。
前回の学習内容はこちら。平均、分散、標準偏差についてまとめている。
1.標準化
・分散や標準偏差を用いるときに気をつけなければいけないのは、データの「単位」である。
例)身長データ「cm(センチメートル)」を二乗すると「㎠(平方センチメートル)」になる。
・身長データを用いるとき、単位を「cm(センチメートル)」とするか「m(メートル)」にするのかで分散や標準偏差の値が大きく変わる。
例)身長データ
↓ cm(センチメートル)
A:173, B:181, C:168, D:175, E:179
↓ m(メートル)
A:1.73, B:1.81, C:1.68, D:1.75, E:1.79
*分散の違いを確認するコード
>>> import numpy as np
a >>>
>>> a = [173, 181, 168, 175, 179]
>>> b = [1.73, 1.81, 1.68, 1.75, 1.79]
>>>
>>> print(np.var(a))
20.959999999999997
>>> print(np.var(b))
0.0020960000000000037
>>> ※varは分散を求める関数
・比べたいデータの単位は違うが、そのデータの散らばり具合を知りたい場合、それぞれの比率を揃える作業を行う。それを「標準化(Z スコア正規化)」という。
・データの平均を「0」、分散を「1」へと変換する。
*データを標準化するコード
>>> import numpy as np
>>>
>>> a = [173, 181, 168, 175, 179]
>>> b = [1.73, 1.81, 1.68, 1.75, 1.79]
>>>
>>> def standardize(x):
... return(x - np.mean(x)) / np.std(x)
...
>>> print(standardize(a))
[-0.48053723 1.26687088 -1.5726673 -0.0436852 0.83001885]
>>> print(standardize(b))
[-0.48053723 1.26687088 -1.5726673 -0.0436852 0.83001885]
>>> 1〜4行目:NumPyをインポートして、集合a、集合bを定義する。
5行目:「def」キーワードを使って、standardizeという関数を定義する。
6行目:戻り値指定。平均を求める「mean」関数を、標準偏差を求める「std」関数で割った値を返す。(=標準偏差)
8行目:先で定義したstandardize関数を使って、集合aのデータを標準化した値を表示する。
10行目:先で定義したstandardize関数を使って、集合bのデータを標準化した値を表示する。
余談)入試などに用いられる偏差値は、平均点を50、分散を10にすることで満点の違いや分布の偏りにかかわらずにデータを比較するための指標である。
2.データの分布
(1)分散や標準偏差をもちいるときは、データの分布をイメージすることが重要である。分散や標準偏差が同じでも、データがどのように分布しているか考えないと、その解釈が大きく変わるからだ。機械学習で分析を行う場合も、グラフなどでデータを可視化してどの分布が適切か判断する。身長のように連続したデータを扱うときは「度数分布表」をもちいる。
*度数分布表の例

*ヒストグラム
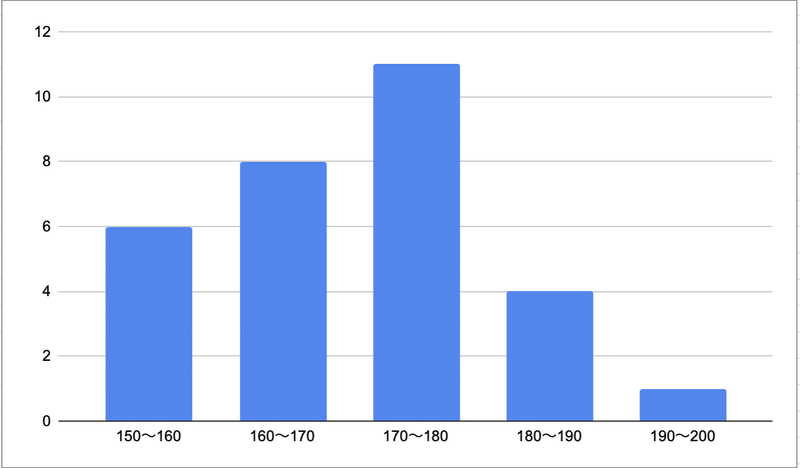
身長、テストの点数や自然界の植物などの分布は平均付近のデータが一番多く、平均から離れるほど数が減っていく山のような形をしている。このような分布を「正規分布(ガウス分布)」という。
(2)正規分布の場合の平均からのデータのばらつき
データが正規分布になっている場合、平均からその標準偏差でどのくらい離れているかわかると、その領域に入るデータが全体の何%くらいあるのかを大体把握できる。
○平均(μ)から±標準偏差1つ分・・・データの約68%
○平均(μ)から±標準偏差2つ分・・・データの約95%
○平均(μ)から±標準偏差3つ分・・・データの約99%
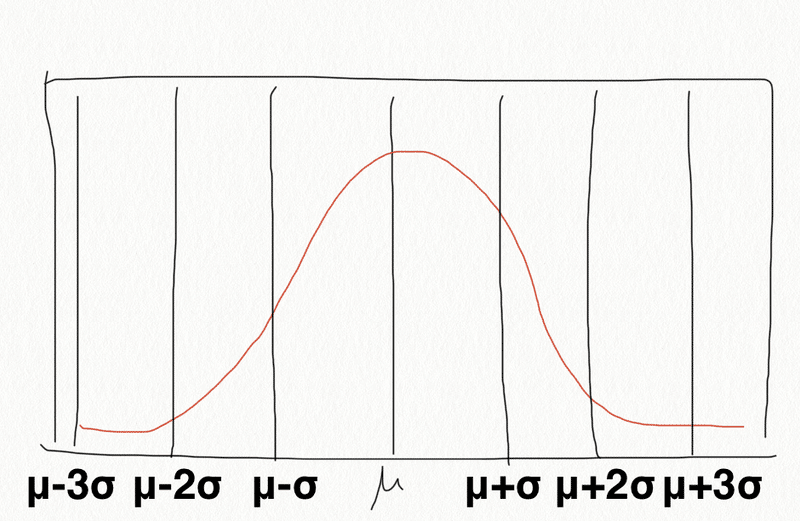
(いきなり手書きですみません。。)
これがわかると、「偏差値が70を超えると、全体の上位2.5%くらい」のようにデータの中におけるおおよその位置がわかる。
(3)その他の分布一覧
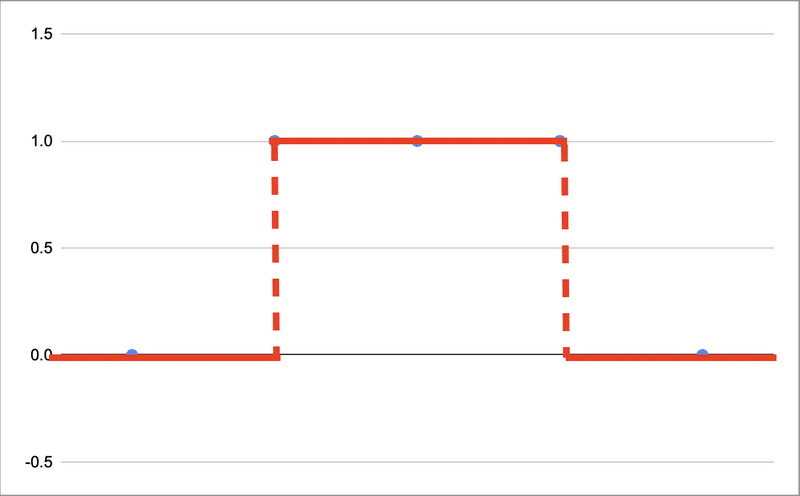
・一様分布(uniform distribution)・・・離散型、および連続型確率分布の一つで、確率密度関数が常に一定の値をとる分布のこと。
・二項分布(Binomial Distribution)・・・互いに独立したベルヌーイ試行をn回行ったときに、ある事象が何回起こるかの確率分布のこと。例えば、「コインを投げたときに表が出るか裏が出るか」などを表した確率分布である。(ベルヌーイ試行とは、試行結果が成功か失敗かの2通りしかない試行をさす。)
↓コインを10回投げて表の出る回数と確率
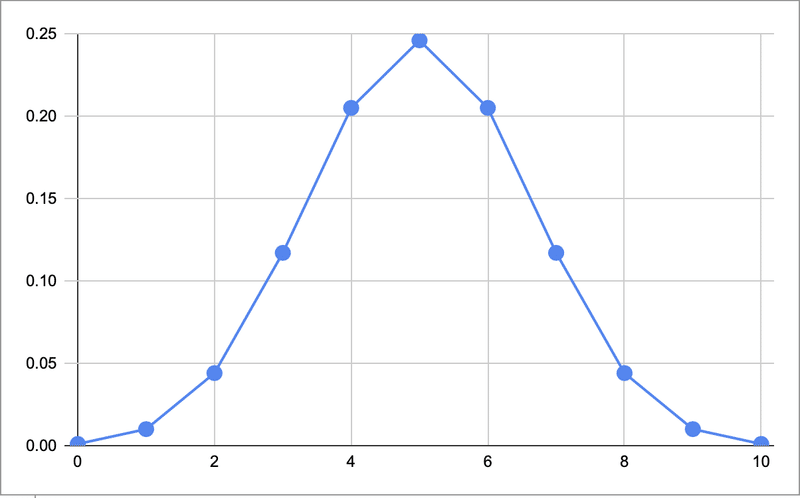
・ベルヌーイ分布(Bernoulli distribution)・・・ベルヌーイ試行によって得られる確率分布。n = 1 の場合の二項分布に等しい。
・指数分布・・・連続型確率分布の一つ。機械が故障してから次に故障するまでの期間や、災害が起こってから次に起こるまでの期間のように、次に何かが起こるまでの期間が従う分布である。
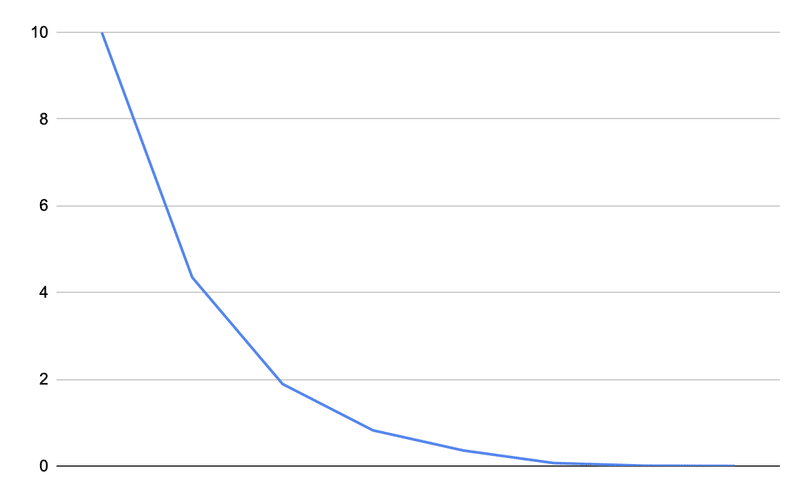
・ポアソン分布・・・離散型確率分布の一種で、二項分布を変形させた分布。ポアソン分布は、繰り返し回数nが極端に大きく、確率pの値が極端に小さい現象に対してよく当てはまる。
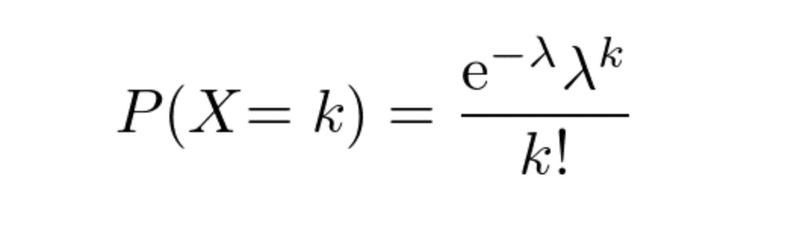
※eはネイピア数(=2.7182818・・・)
例)エクセル統計開発者のKさんのもとには、1時間あたり平均5通のお問い合わせメールが届きます。1時間にお問い合わせメールが届く数がポアソン分布に従うとすると、終業時刻までの1時間の間にお問い合わせメールが1通も届かない確率はいくらでしょうか。
λ=5、k=0となる。
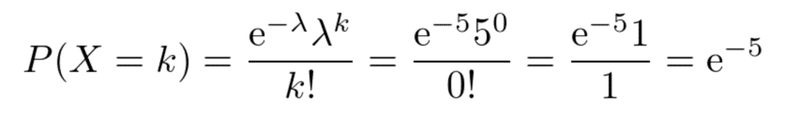
eはネイピア数(=2.7182818・・・)のため、計算すると、0.0067・・・となる
このサイトにすごく分かりやすくまとめられていました。例題もここから出ています。
データの分布をイメージするのに苦労した。指数に関する基本的な数学知識の復習ができた。
次回は、Pythonはひとまず隣に置いて、数学知識を中心に学習を進めていく。
よろしければサポートお願いします。いただいたサポートを皆さんに還元していきたいと思っております。