
手を動かして学ぶ技術書のススメ 「Pythonで動かして学ぶ! Kaggleデータ分析入門」

翔泳社ブックアンバサダーに応募したところ運良く当選したので、「Pythonで動かして学ぶ!Kaggleデータ分析入門」の本を頂いた!!!!
ようやく写経&実行したりsubmitしたりなど、本の内容を一通り手を動かして読み込んだので本の感想を書いていく。
実務でいうと私は、データ分析が主務ではない。今まで、モバイルアプリを開発→インフラ設定・運用の開発のエンジニアをしているので専門外だ。
データ分析をするためのデータを送る実装をする業務は発生していたので、具体的にどんなデータがあるとよいのか、どういう型で送ればいいのかを気にしたことはあったが、集計したことはない。
全く分野外の人間が、Kaggleデータ分析入門を読むと、どんな知見を獲得できるのかがわかるまとめになるといいなと思う。
この本を手に取るまでの自分の状態について
○Kaggleについて知っていたこと
・Kaggleという競技らしい
・どうやら機械学習をして、わからないデータを埋めたりするらしい
・興味はあるが始め方がよくわからない。そもそもサンプルとかあるの?どうやって提出するの?
・チュートリアルがどこにあるのかがわからない。
・始めるのが億劫になっていた。
○自分の知識範囲とモチベーション
・仕事で分析業務を始めようかなとモチベーションが上がった状態になったが,そもそも何をどうやって取り組めばよいのかよくわからなかった。
仕事上だとSQLと考察を書き溜めるところが別の状態になっていて、数日たった自分がみると何をどう考えていたのか追えない状態だった。社内でJupyter Notebookでも分析ができる状態ができてきたので、試しにPythonをつかってSQLを回し、グラフを出したり分析をしたり、考えをまとめてみたいという気持ちがあった。
ただ、Pythonはあまり触ったことのない言語で、環境構築がちょっとめんどくさそうなので腰が重たい状態が続いていた。
この本で解決したい課題と期待したこと
○環境構築が楽なKaggle notebookで分析手法に慣れる
この本で紹介されるまで存在すら知らなかったのだが、Kaggle notebookは環境構築なしですぐに試せるということで、分析手法をすぐに体験できることを期待した。
○ 話題のKaggleという競技を知る
Kaggleと聞くが、具体的に何をしているのかを知らないので、競技の内容を実際に手を動かして提出までできるのが良い。また、サンプルとしてTitanicコンペとHousePricesコンペという2つのサンプルコンペを扱っているため、少なすぎず、多すぎず丁度いい分量だなと思った。
○Pythonでどうやって分析をするのか流れを知る
特にこれを勉強したいと思っていた。前の項目にも書いたが、自分が今知りたいことは、どうやって分析をするのかということだ。具体的な事例と、今後の勉強の仕方が書いてあれば、発展性があってよい。
○同僚のデータサイエンティストがどんな仕事をしているのかを知るキッカケにしたい
例えば自分がデータサイエンティストと一緒に仕事をすることになったときに、助かることや、困っていることは何かを知れば、よりよい仕事ができるようになると考えた。
データをただ集めるのではなく、集計しやすいようにするとか、どういう項目が必要になるかを考えたり、必要になったときにすぐに実装できるか拡張性を考えたりなど、他の人の仕事を知ることで自分の仕事が広がることは多い。
上記を理解できそうだったので読んでみることにした。
内容について
○目次
Prologe Kaggleで実践的なスキルを体験しよう!
Chapter1 Kaggleとは
Chapter2 データ分析の手順、データ分析環境の構築
Chapter3 Kaggleコンペにチャレンジ①: Titanicコンペ
Chapter4 Kaggleコンペにチャレンジ②: House Pricesコンペ
Chapter5 さらなるデータサイエンス力向上のためのヒント
Appendix Kaggle Days Tokyo 2019レポート
○概要と切り口
そもそもKaggleとはなにかというところからスタート。
サンプルとしてTitanicコンペとHouse Pricesコンペの分析方法の紹介が掲載されている。
また、精度を上げる以外の分析視点も追記されていて、グラフでの可視化のやり方深堀りした分析のやり方が掲載されている。
後ろの章ではKaggle Days Tokyo 2019の参加レポートがまとめられていて、Kaggleという競技だけではなく、初期設定からコミュニティの紹介まで抑えた入門書。
読了後のデータ分析に対する解像度の上がり方について
タイタニックコンペの事例より、読了前と読了後どんな感じで考え方や進め方の整理が自分の頭のなかで行われたか可視化する。
※タイタニックコンペの特徴
乗客ごとに性別や年齢、乗船チケットクラスなどのデータが、生存したか死亡したかのフラグとともに与えられています。
生死に影響する属性の傾向をデータから分析して、生死がわからない(予測用に隠されている)乗客について、生死結果を予測することが目的です。
(4pより引用)
○データの概要を把握する
そもそも、どうやって概要を把握するかということ自体をわかっていなかっった状態だった。
この本は、次の一歩をどうすればいいのかわからない状態から、何をすればいいのかをガイドしてくれるので次を自分で予測しながら、読んでいくことにした。
Kaggleは競技なので、学習データとテストデータが存在する。それぞれの行数や列数を確認するところからはじまることを知った。
まず詳細を見るのではなく、全体の行列から確認するのが大事だなと改めて感じた。

統計量を見る項目では、pandsの関数のなかのdescribe()を知った。こういう本の中で出会わないとそもそもそういう関数があることを検索できない。
ここで以前かじった、統計学の知識が役になって嬉しくなった。
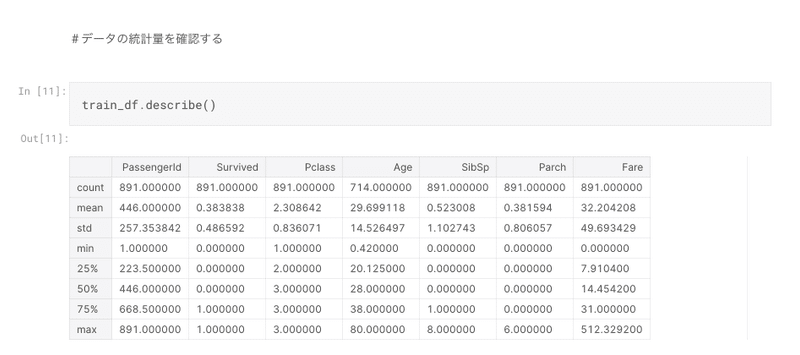
Pythonが書けるのに加えて、ライブラリを正しく使う+データを正しく読み取る知識がいるということを初っ端から痛感した。

この項目では、それぞれの列の概要を確認した。その列に、どの項目がどれだけ含まれているかを確認することができる。
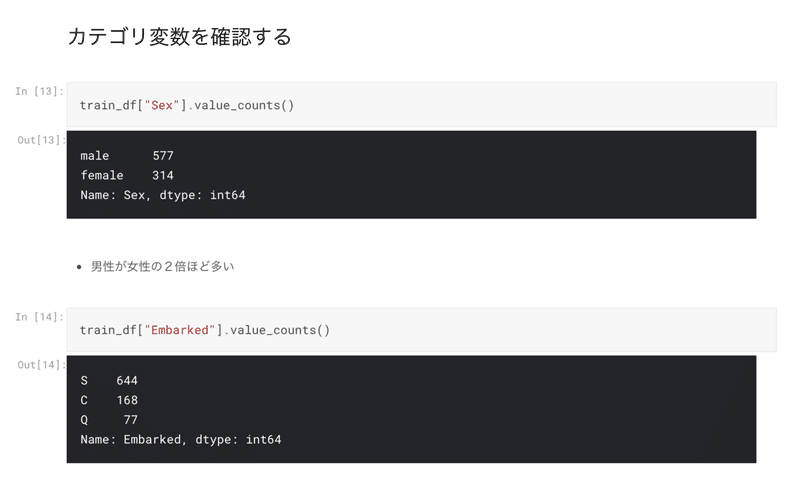
このタイタニックコンペの例だと、生存かどうかを予測するコンペなので、対象は人間だ。そう思うと、男女で違いがあるかは試そうと自分が思いつく可能性はある。
しかし、housepricesコンペの方では家の値段を予測するというコンペなので、対象となる要素が多く、データをよく理解しておかないとどこから見ればよいのかわからないとなる。
(Kagglerの皆さんは、一体どうやって決めているのだろう?)

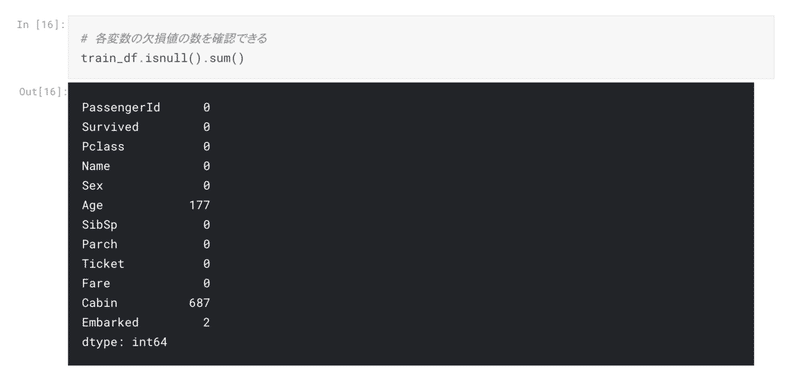
欠損値がある場合、どうやって穴埋めするのだろうと疑問に思っていたが、ただ平均をとって穴埋めをするのではなく、そのグループごとに分けて穴埋めをするなど、欠損値の扱い方に関してもいろいろな工夫ができることを学んだ。
○データを可視化する
ここが一番楽しみなところだった。
ここで大事なのはただ可視化するだけではなく、なぜ可視化するのか、何を明らかにしたくて、どうやってそれをわかりやすく図をして表現をするか選択することだと思う。

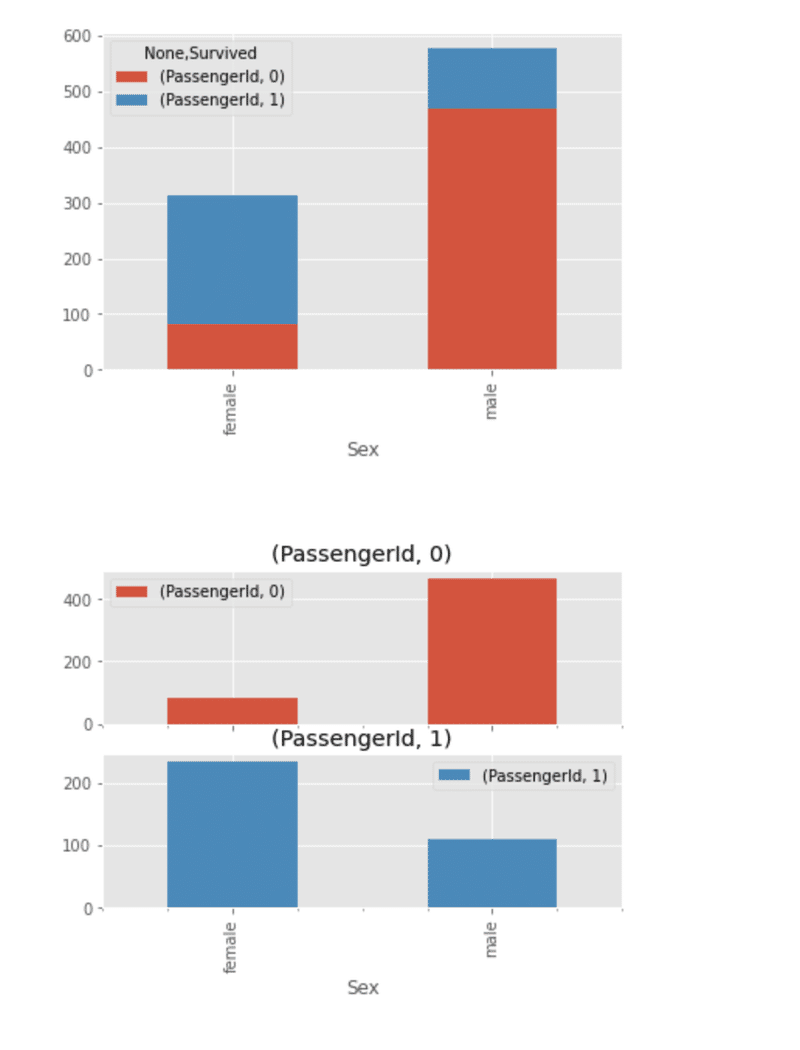
検証:乗船港によって生存数が異なるか(積み上げグラフ)
↓
結果と次の仮説の想起:乗客のタイプや状態になにか違いがあるかも
検証:性別やチケットの階級について可視化する(積み上げグラフ)
↓
結果と次の仮説の想起:女性の方が男性よりも生存率が高く、チケットの階級が高いほど生存率が高い
優先的に救助されたかも?
検証:年代ごとの生存率の確認
年齢は連続値のため、ヒストグラムを作成する
↓
結果と次の仮説の想起:
10歳以下の子供は、他の年齢層と比較して生存率が高い
もしかしたら優先的に救助されたかも?
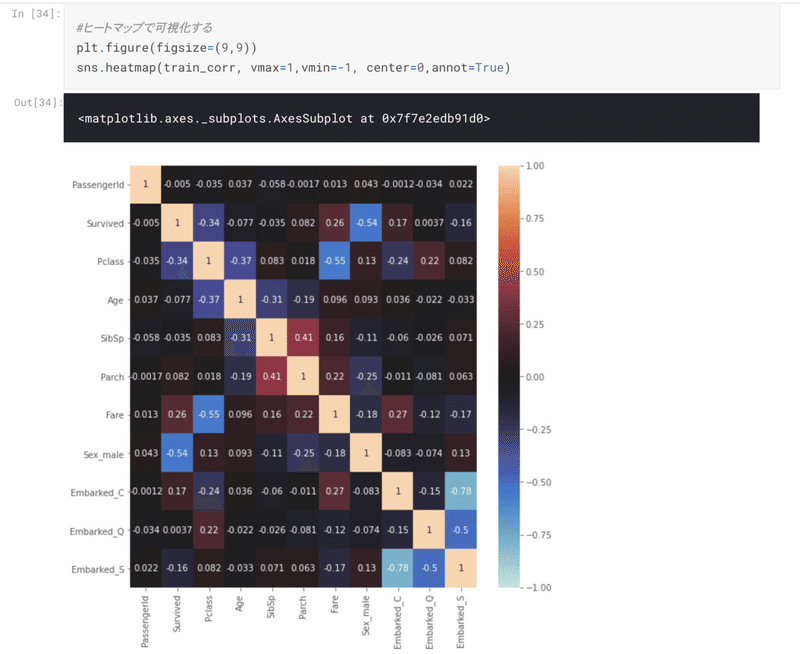
検証:変数間の相関の分析のためにヒートマップを作成
↓
結果と次の仮説の想起:
男性の方が生存率が低く、女性の方が生存率が高い傾向にありそう
チケットの階級が高いほうが生存しやすそう
年齢はSurcicedと相関がないようだが、生存に関係がないとは限らない
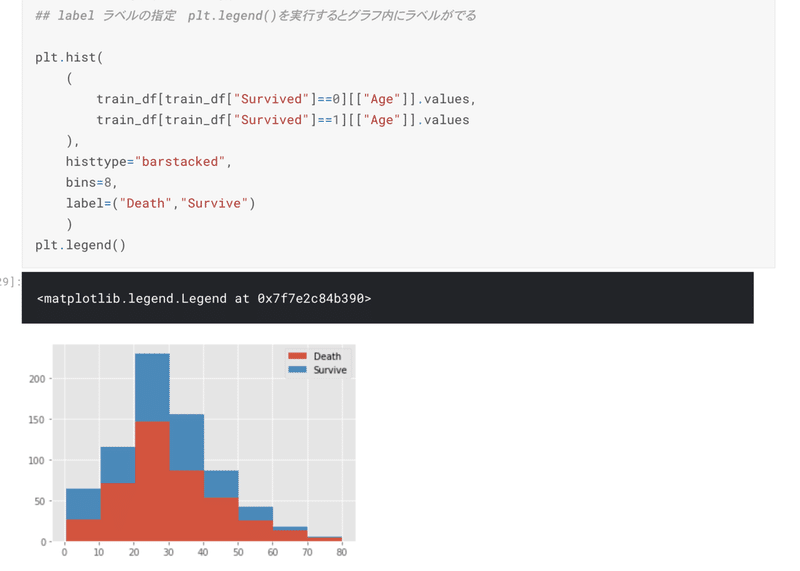
どうやって、何を読み取って仮説を立てるのかが知りたいことだ。
本の内容から、このヒストグラムから、どういうことが読み取れるかが本文中に記載してあるのが大変勉強になった。
○前処理・特徴量の生成
この本を読むまでは、前処理ってデータの型を整えたりするだけなのかなと思っていたが、全然違った。むしろここが一番難しいのではないかと思う。
前の段階で分析した結果を用いて、新しい行を加えたり、モデルを作るのに不必要と思われるものを削除したりと大事な段階であると理解した。
今回注目するデータは
Fare(チケット料金),Name(名字、敬称、名前),Parch(乗船している親や子供の数),SibSP(乗船している兄弟や配偶者の数)とされている。
おそらく、注目するデータはその前の調査で、変数の中でどれを選べば答えに辿り着けそうかを調査すると思うのだが、本ではそれが省略されていた。
他の変数はなぜ選ばなかったのかという理由があればもっと良かったと思う。
本番のKaggleでは自分でどの変数に着目するかを探し出さなければならないのだ。どうすれば探し出せるかまでは、書いてなかったので自分で他の人のkaggle notebookを見ることで発見していくしか無いのだろう。
○Fareの欠損値の穴埋めの例
これは一つのみ欠損があったので、チケットクラスごとの平均を出して埋める方法を使っていた。
○年齢の欠損を敬称で埋める
まさか敬称(Mrとか)で年齢の欠損で埋めれるとは思わなかった。欠損を埋めるために使えるものは何でも使うという気持ちが大事だと思った。
敬称を使うにあたって本文中では、
敬称ごとの生存率の違いについて確認する
↓
年齢・性別ごとの生存率と同様に傾向になる。
年齢は欠損値の多いデータですので、これらの敬称のデータが年齢の補完として効果的な変数となる可能性がある
と、どうやって補完するのがよいのか考え方が書いてあり、参考になった。

○家族の人数についての新しい変数をデータから作成する
与えられた既存のデータから、新しい列を作るという発想を持っていなかったので、ここの項目も勉強になった。
タイタニック号の遭難のような事態において、家族は一緒に行動している可能性があります。そのため、1人か、それとも動線家族がいるかは生存に影響する可能性があるため,alone(1なら1人、そうでなければ0)として変数に加えておきます。
(119pより引用)
このように、データだけではなく、この事件がおきた顛末や、起きたときに起こりうる状況を想像して、別の視点が無いかを探す必要もあることが勉強になった。
モデリングを行う
ここは全くの専門外。モデリングをするということ自体が初めてで、理解が追いついていないがまとめていく。

○どの機械学習手法を選ぶか決める
タイタニックコンペの例ではLightGBMという決定木系の機械学習手法を用いて予測していく例だった。ということは、他にも企画学習手法があるんだろうなと言うことを察したが、理解する前にとりあえず写経して予測をためしてみることにした。
習熟してくると、それぞれのコンペや内容にふさわしい手法が選べるようになるのだろう。
もう一つのサンプルコンペとして挙げられていた、HousePricesの例では、まず先にベースラインを作成して、予測値を作ってから精度を向上させていくようにしていた。
○いろんなハイパーパラメーターを試す
ハイパーパラーメーターってなんぞ・・・という感じでとりあえず写経した。モデルの挙動を設定するための値の事らしい。
もう一つのサンプルコンペとして挙げられていた、HousePricesの例では複数のハイパーパラメーターを同時に変更することが必要だから、最適化用のライブラリが紹介されていた。
前半のタイタニックコンペで手動で設定して大変だということがわかってから、後半のHousePricesコンペで自動化する方法が紹介されていて、発展性があってよかった。
わからなかったところ
○なぜそれを調べようとおもったのかという過程をもっと書いてほしかった。
仮説をたてる→実際にデータを見るのが流れだと思うが、なぜそれを調べようと思ったのか、それは定石なのかがわからなくて困った。
特に3章の前処理
・特徴量の生成のところでは、唐突に敬称を使うとでてきて、写経をしていると、なぜこれが必要なのかがわからないまま次に進み、最後に種明かしされているような感じだった。
仮説→だからこれを調べてみるがもっとあると良かったと思う。
○Pythonのドキュメントを紹介したほうが発展性があっていいかも
今回はできるだけ知らない関数は公式ドキュメントをみようという感じで写経しながらnotebookに試して書くことができた。もっとこういう便利な関数やオプションがあるよなどを紹介するといいかもしれない(が紙の本の都合上そこまで書くと膨大になるからやっぱりKaggle notebookの方でリンクを貼るとかのほうがいいのかも・・・)。
○モデルをつくるという挙動がよくわからなかった
いちばん大事なところだと思うが、これが理解できていない。前処理をして、学習データと検証データにわけて、モデルをつくり検証データで正解が多かったモデルで予測データをつくるという流れはなんとなくわかったが、
どういう仕組みで、なぜLightGBMを利用したのかというのが理解しきれなかった。
まとめ
知らないPythonのライブラリの関数をドキュメントを見ながら写経したので読み終えるまでに、めちゃくちゃ時間がかかった。
この本で解決したい課題と期待したことは達成できたか
○環境構築が楽なKaggle notebookで分析手法に慣れる
→これはだいぶnotebookが楽だということがわかった。ショートカットキーを覚え始めた。今度、Dockerを学ぶがてら、自分のJupyter Notebookの設定を作ってみようかなとモチベーションにつながった。
○ 話題のKaggleという競技を知る
→2つ提出してみて、競技の流れを知ることができた。UIや使い方、どこを見るといいのかまでわかったので、今後自分でやりたいと思ったときに腰が重くならなくてすむ。
○Pythonでどうやって分析をするのか流れを知る
→3章10項目目の精度以外の分析視点が特に勉強になった。
グラフの中に、2つのグループで色を変えて可視化するなど、そういう関数があること知らなかったので勉強になった。
○同僚のデータサイエンティストがどんな仕事をしているのかを知るキッカケにしたい
→これは、前処理が一番大変何じゃないかと感じ取れたことが一番の進捗だと思う。たとえばデータを送る時に、どういう形式で送るのが楽だろうということを考慮に入れたり、どんなデータが必要かをこちらから尋ねるなど行動したほうがいいのではないかという意識を変えることができた。
Pythonでデータを分析して考えるのも大事だが、そもそものデータ自体の理解やバックグラウンドの理解がないといい分析や予測はできないのだなと痛感した。これは、総合格闘技すぎる・・・難しい。
自分のやってきた分野とは全く違う分野の入門書ではあったが、興味があったので無事に読了できた。今後データを扱う分野で仕事をしてみたいなと思っていたので、データ自体の理解や、それが起きた背景も知る必要があることを学べてよかった。
翔泳社ブックアンバサダーに運良く当選して、この本を読めるチャンスを頂けたことを嬉しく思う。どうもありがとうございました。
エンジニアとして働いている成長記録やおもしろいと思ったこと色々書いていこうとおもいます 頂いたご支援は、資料や勉強のための本、次のネタのための資金にし、さらに面白いことを発信するために使います 応援おねがいします