
好みの音声ファイルを利用する音声自動生成のOpenVoiceの使い方

GitHubのトレンドに、OpenVoiceという音声自動生成のコードがありましたので紹介します。

OpenVoiceでは、ユーザが使用した短い音声ファイルから、感情表現(cheerful,sad, angryなど)を伴った音声を作成することができます。
今回は、Google ColabからGradioを立ち上げる流れになります。
Google Colabでは、A100を利用しており、各種リソース状況は以下ですので、A100ではなくても良いかと思います。

では、Google Colabで以下を実行しますと、今回の成果物が出来ます。
!git clone https://github.com/myshell-ai/OpenVoice.git
%cd OpenVoice
!pip install -r requirements.txt
!python -m openvoice_app --share実行しますと、Runnning on public URLというところのhttpsリンクをクリックしますと初期画面が出てきます。

使用方法は、下記画面をベースに簡潔に説明します。
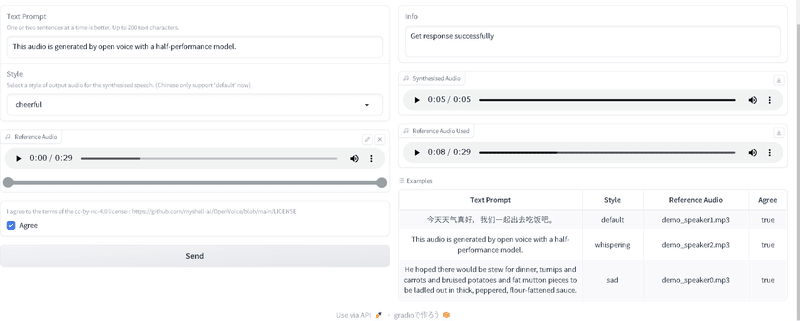
Text Promptには、読み上げさせたいテキストを書きます。マルチリンガルに対応しているそうですが、デフォルトでは、中国語と英語となります。
Styleでは、読み上げさせたいときの感情を選択します。

Reference Audioは、ベースとなる音声となります。今回は、固定されていますが、/content/OpenVoice/openvoice_app.pyの下記行を修正すれば、他のベースとなる音声でも対応可能です。

次に、Agreeにチェックを入れて、Sendを押しますと音声ファイルが作成されます。
左側の、Synthesised Audioが、作成されたファイルとなります。
所感としては、OpenVoiceというネーミングが良いです。
また、短い時間で音声ファイルを作成できるのは進歩しているという感じがします。
今後、ベースとなる音声ファイルから文章を読み上げるような感じになっていくのだと思うと、少し味気なくなります。
音声生成のビジネス活用としては、オーディオブック、映画、アニメ業界に影響を及ぼして、今までは最初から最後まで人に読んでもらう必要がありましたが、最初のサンプリング音声だけでオーディオブック、アニメの音声を作成する流れが予想されます。
この記事が気に入ったらサポートをしてみませんか?