裁量トレードおじさん、botterを目指す

来年の目標はbotterになることです。
ということでpython非学者である私があーだこーだしてなんとかpythonを学習し、botを頑張って作るまでの学習記録として書いていきます。
pineおよびlite scriptはできるため、まったくゼロからコードを書くというわけではありませんが、それでもやることは多く苦難の道のりとなりそうです。
n日目という表現をしていますが、のんびりとある程度学習しつつ区切りの良い所でまとめているだけです。実際の学習日数ではありません。
無教養なためムズそうな横文字表記やコード記述のセオリーなどは無視します。本職が見たら血管切れそうな内容になるかもしれません。
適当なタイミングで更新していきます。
一日目
pythonを書くこと自体は特に何かインストールせずともメモ帳で書けばいいらしい。
しかしそれを実行するためには色々しないといけない。
んでその色々の部分をまとめてくれてるパッケージをまずインストール。
ディストリビューションとか言うらしいけど何を言ってるのかさっぱりわからん。日本語で話せや。
とりあえず今のところの認識は「書いたpythonのコードを実行してくれる便利なやつ(実質必須)」です。
なんかだいたいみんな使ってるからという理由でこれはanacondaを選択。
メモ帳で書いてanaconda prompt(windowsのコマンドプロンプトのanacondaバージョン)で実行。がたぶんデキる男の行きつく先な気がする。のだけれど、さすがにメモ帳に書いて保存→promptで実行→エラーのループを何十回も繰り返したら頭おかしくなっちゃう。
そしてメモ帳じゃどうも殺風景だしいいもんないかなってことで調べた結果、コード書いてついでにそのまま実行できる何かがあったのでインストール。
「テキストエディタ兼書いたコードそのまま実行してくれるスグレモノ」って認識。一々別ウィンドウ開いてコマンド打ってっていう手間省ける。
とりあえずこれで書く準備は整った。
必要なものがあれば順次入れていけばいいだろうの精神。
二日目
とりあえずコード書いてみる。
関数とか引数とかなんか専門用語みたいなやつあるけど、細かいのは後回し。教師じゃないんだから。
でも一応最低限は知っておかないといけないのでちょっとおべんつよした。
基本構文:
変数名 = 関数(引数)
以上。これだけ覚えておけば半年くらいは楽しめそう。
名札が変数名、なんかゴニョゴニョするのが関数、ゴニョゴニョする対象が引数。
それらをまとめて変数って呼ぶ。
違ってたらそのうち訂正する。まあこんなもんでええやろ。
というわけで早速書いてみた。
なるほど pic.twitter.com/S14J5ve7HD
— ₍₍⁽⁽壇上.rar.exe₎₎⁾⁾ (@lasthopelonger) November 29, 2022
この前一人で騒いでたのはこれです。
「身長165cm以下は人権ない」っていうのをコードにしたもの。
でも今考えたら以下って<=だったね。<だと未満や。
細かいことは置いておいて。
if文はpineでも使ってたのでほぼその通りに書いてみたらちゃんとできた。えらい。
height_borderが人権ラインの身長
your_heightがあなたの身長
ifは「もし」
なので
「もし君の身長が人権ラインより高ければ、『人権あり』と書き出す」
「上の条件に当てはまらない場合、君の身長が人権ラインより低ければ、『人権なし』と書き出す」
というコード。
これに何の意味があるかって?ないよそんなもの。
自分が言いたいことをコードにできるかどうかが重要。
三日目
計算するにはまず演算子を知らねば始まるまい
ということでおべんつよ
複雑なものは後回しにしておいて、使いそうなものだけざっくりと洗い出す。
結果:

細かいところは置いておくとして、とりあえずこの程度知っておけば中学生レベルまでの計算はできるはず。あとは努力。
算術演算子は普通の計算で使うやつ。数字と数字をあれこれみたいな。
関係演算子は二つの要素の関係性出すやつ。条件文とか書くときに使いそう。
論理演算子はまあ見たまま。
代入演算子は正直使いどころがパッと思いつかないので全部「=」だけ使ってゴリ押しする可能性大。どうせそれでもいけそうだし。
というわけでホモの欲張りセットで適当に書いてみよう。
a = input("身長(cm)")
b = input("体重(kg)")
x = float(a)*0.1
y = float(b)
bmi = y/(x**2)
if x >=180 and bmi<=25:
print("結婚しよ")
else:
print("人権なし")
はい。できました。
まずは身長と体重をinput関数で入力。
このままだとstr(文字列)で処理されてしまうので、数値だよってのを教えるためfloatにする。
身長はBMI計算時にメートル換算する必要があるのでcm表記の1/10して単位を合わせてあげるよ。
どうせなので健康のためにBMIも出せるようにしてあげよう。
そんで「身長180cmかつBMIが25以下の人は結婚しよってなる。それ以外は人権なし」というのをandを使用した条件文で記述。
結果:
短小包茎おじさん... pic.twitter.com/Pm5K0gT9Mv
— ₍₍⁽⁽壇上.rar.exe₎₎⁾⁾ (@lasthopelonger) December 5, 2022
こうなる。
年収の項目も入れて、and条件に加えればどんどん条件を絞っていけるぞ。やったね。でも最終的に「人権なし」で埋め尽くされる可能性もあるので妥協は必要。はっきりわかんだね。
四日目
関数をちょっと覚える作業。
とは言うものの関数はとんでもなく種類が多いため、まるまる覚えるのは大変。
なので以下のプロセスで進めていく予定。
①リファレンスを読む
②pineと共通または類似する関数をフィルタリングする
③頻出するコードをまとめる
いずれにせよいくつかの関数はちゃんと覚えなきゃいけないのだけれど、とりあえず最低限の組み込み関数だけは押さえておき、あとは必要な時が来た際に調べて補完していくスタイル。

で、とりあえず出したのがコチラ。
任意の値を入力できるようにするinput関数をはじめとして、その他細々とした計算に使用する一部の関数はpineと共通して存在するためこの辺は簡単。
ボリバン計算とかで使う標準偏差などについては数学の計算に特化したモジュール(関数とかの辞書的なやつ)を入れればできるようになるらしいので、もし今後他にも何らかの操作で躓いた場合は最初にモジュール探しから始めるのもアリかもしれない。
そうすればわざわざ自分で関数を作る必要がなくなるので少しは楽になるはず。
よく使う関数とはいっても、まだどんな関数があるのかよくわかっていないため、入力した値がどの型なのかを判別するtypeと値を指定の型に変換する各関数、そしてファイルなどを開くopenと最後に計算した数値を確認するためのprintを最優先に覚えておけばあとはどうにかできそう。
inputはstr型で判断されるそうなので、「数値入力はinput→floatまたはint」といった感じで脳死コンボに繋げておけば楽そう。
ある程度のパターンはあるはずなので、関数を覚えるのと同時にそのパターンも習得していきたい。
五日目
組み込み関数だけでもできることはあれど、やはり幅は少ない。
文章のように入力できるだけのただの電卓になってしまう。
いずれ通る道でもあるし、せっかくなら先人の知恵を利用してしまおう。
というわけでライブラリやモジュールといったものを入れたり使ってみる。
ライブラリは「自動車整備キット」の名札がついてるクソデカい箱。
その中にパッケージと呼ばれる「ネジ箱」や「工具箱」が入っている。
工具箱の中にはモジュールと呼ばれる小さな箱があり、たとえば「ドライバー」や「レンチ」といった具合に仕分けされている。
そしてさらにそのモジュールの中に実際に使用するプラスドライバーだったり精密ドライバーだったりの工具、つまり関数が収められている。
とりあえず今の電卓を関数電卓くらいのレベルに引き上げるためには、数学計算をするための何かしらを用意しなければならない。
幸いpythonには「math」というモジュールが標準装備されているため、特に何かインストールする必要もなくこれを利用できる。
ただしpythonという相棒に対して「math取ってくれ」とお願いしなければ、mathに搭載されている関数をそのまま記述したところでわかってくれない。
ツールはあっても取りに行く指示を出さなければずっとその場に立っている。プログラムというのは常に受け身なのだ。
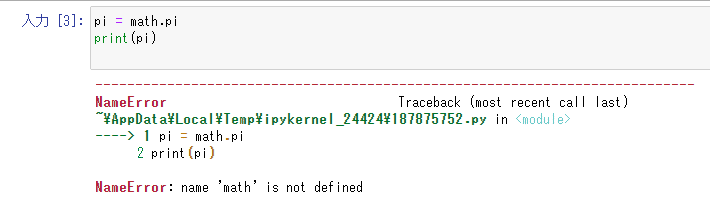
なので、そのお願いするコードをまず記述する。
方法は簡単。「import」の後に必要なモジュール名を記述する。
import math
pi = math.pi
print(pi)ついでに円周率を出すmath.pi関数でテスト。
結果は以下。

やればできるじゃないか。ちゃんと適切な指示を与えれば動いてくれる有能君になってくれた。
もうちょっと高度なものも計算したければstatisticsモジュールも持ってこさせればいい
import math
import statistics
data = [1, 2, 3]
dev = statistics.pstdev(data)
print(dev)このようにリスト化させた数値の標準偏差を求めるには「統計」のツールボックスであるstatisticsの方が最適な場合もある。適材適所。
これを発展させればボリンジャーバンドも使用できるようになる。やったね。
いずれ使用するであろうデータ分析や計算に特化したライブラリもせっかくなので入れてしまおう。
デフォルトでは入っていなくても簡単に探してインストールしてくれる。便利。というわけでやってみる。
インストールは「!pip install」でいけるので、まずは計算に必要と予測されるライブラリのnumpyを。
!pip install numpy
そういえば最初にインストールしてたんだった。
じゃあデータ分析に便利そうなpandasや
!pip install pandas
こっちも終わってた。なんかマストっぽそうだったのでAnacondaインストールした日についでに入れてたかもしれない。まあいいや。とりあえずこんな感じで入れておけば使えるということで。
とりあえずちゃんとインストールできているのか見てみよう。
まずはさっきのモジュールと同じく呼び出すために「import」を使う。
で、その後にそのライブラリに含まれる関数を使うけれど、その際は「ライブラリ名.関数」みたいに書かなきゃいけないので、一々「pandas.なんとか」みたいに書いてるとクッソ長くて手が疲れる。
なのでimportの段階でニックネームを勝手につけれる。pandasはだいたいpdらしいのでpdを使うことにしよう。numpyはnp。
その後はバージョンチェックするための関数(?)を使う。
もちろん書き出すためのprintも忘れず。
import pandas as pd
print(pd.__version__)
ちゃんとインストール出来てたっぽいのでpandasの関数を読み込んでバージョン表示してくれた。
せっかくなので変なニックネームつけても怒らないかも試してみよう。
今回はnumpyでやってみる。
「xのt乗」を計算する「.power」を使ってやってみよう。
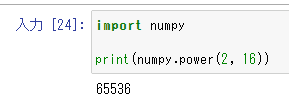
まずは正式名であるnumpyの場合。もちろん2の16乗である65536が出力された。ロングフリーズ。
では次はasを使用して渾名をつけて呼んでみよう。
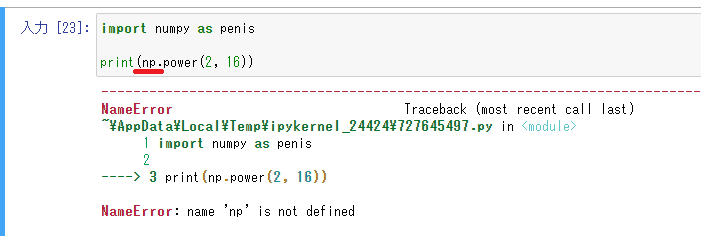
penisと自分でニックネームをつけたのに通称のnpを呼んじゃ「誰ですかそれ?」ってなる。そりゃ当然。
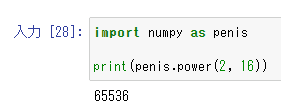
penisと呼ぶなら最後までpenisで統一しろという意思を感じる。漢だね。
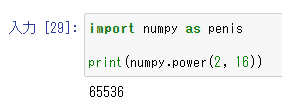
ちなみにあくまでもニックネームなので、もちろん本名を呼べば答えてくれる。だーまえとクラスのみんなに呼ばれていても前田君だということはちゃんと弁えている。
ライブラリやモジュールをどんどん追加できればそれまでできなかったことを簡単かつ膨大に処理できるようになる。このようなライブラリを探すのもpythonのおべんつよをするには必要なセンスかもしれない。
そして恐らくではあるが、デキる人は自分の専門性に合わせてこのライブラリすらも作ってしまうのだろう。恐ろしきエンジニア達よ。
六日目
とりあえずライブラリというツールが利用できるようになったので、ローソク足でも出してみよう。
①どこかしらからローソク足の元となるOHLCデータを調達する。
②どうにかしてそれをローソク足に形作る。
という2つのステップをとらなければならない。
まず①からだが、ccxtというライブラリを使えば簡単に取引所のデータが取得できるらしい。
ということでまずはccxtを!pipでインストール。
あとその上位互換を目指しているpybottersもいずれ必要になるのでインストール。
次に取得した情報をグラフにする前段階、ちゃんと形の整ったリストにしたいのでpandasを用意。
②の機能が備わってるライブラリであるmplfinanceをインストール。
準備は整った。
とりあえずこれからやる作業にはこの二つのライブラリを使うので、先に
import ccxt
import pandas as pd
import mplfinance as mpfを忘れずにくっつけておく。
ccxtやpybottersで使える取引所は結構あるけれど、どれが対応しているのかはドキュメントと睨めっこ。
今回はbinanceのデータでやってみよう。
APIを取得するわけなのだけれど、APIは二種類。パブリックとプライベート。パブリックはユーザーに共有されている情報(ローソクだったり出来高だったり板だったり)、プライベートはログインした自分だけが取り扱える情報(残高だったり注文情報だったり)くらいの認識。うっかりプライベートAPIを他人に教えちゃうとそりゃもうなんでもやり放題になっちゃうので気をつけよう。過去には配布したbotのソースコード内にビットコインを盗むコードが仕込まれていた事件もあったとかなかったとか。
とりあえず今回はローソク足情報が欲しいだけなのでパブリックAPIで処理できる内容。誰でも安心。
それぞれの取引所ごとに一々専用の関数など用意してないので、「どの取引所で使う関数なのか」を先に定義する(オブジェクト生成とかいうやつ)
import ccxt
import pandas as pd
import mplfinance as mpf
bi = ccxt.binance() これで「bi.なんとか」と書けば「binanceのデータをあーだこーだするんやぞ」っていう関数になる。
いよいよローソク足を出すのだけれど、関数である以上引数も何かしらある。
引数は、
①通貨ペア
②時間足
③取得開始時刻
④取得本数
⑤その他パラメーター
となっているので、これに合うようにしてみよう。
import ccxt
import pandas as pd
import mplfinance as mpf
bi = ccxt.binance()
ohlcv = bi.fetch_ohlcv(symbol="BTC/USDT",
timeframe = "1d",
since=None,
limit=None,
params={})情報取得系は「fetech_」でやれるっぽい。ohlcvを抽出する関数を使い必要な情報を出す。
ためしにprintで出してみる。
holy shit.
リスト化された生情報がそのまま出てきてしまった。こんなの読んでいたら日が暮れてしまう。
ので、次はこのリストをちょっとキレイにする。
import ccxt
import pandas as pd
import mplfinance as mpf
bi = ccxt.binance()
ohlcv = bi.fetch_ohlcv(symbol="BTC/USDT",
timeframe = "1d",
since=None,
limit=None,
params={})
df = pd.DataFrame(ohlcv)
print(df)ここでpandasの出番。
DataFrameによってリストをexcelみたいな形に整えてくれる。
一旦確認してみよう。

有能。
最後に記述してある情報は「500行×5列のデータフレームやぞ」って親切に書いてくれています。デキる相棒はかゆい所に手が届く。
じゃあここからそれぞれの列のデータを別個に分割する。
import ccxt
import pandas as pd
import mplfinance as mpf
bi = ccxt.binance()
ohlcv = bi.fetch_ohlcv(symbol="BTC/USDT",
timeframe = "1d",
since=None,
limit=None,
params={})
df = pd.DataFrame(ohlcv)
df.columns = ["Time","Open","High","Low","Close","Volume"]
Open = df["Open"]
High = df["High"]
Low = df["Low"]
Close = df["Close"]
print(Open)
print(High)
print(Low)
print(Close)一応ちゃんとできているかprintで確認。
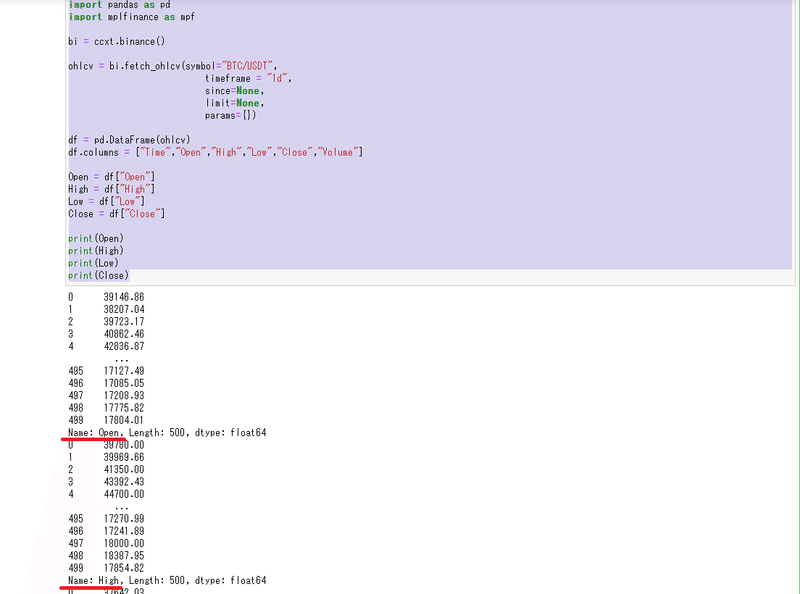
ちゃんと個別の列のデータが表記されているので成功。やったぜ。
さて、ここで問題発生。立て続けに発生したので一旦列挙。
①取得した時間データはUnix time
②ついでにtypeで出てきた形式はSeries
③mpfでローソク足出すには時間のデータを「時間データ且つインデックス」にしなければならない
この3つの問題を解決しなければ先へは進めない。
ので、順にやっていく。
まずはUnix timeとかいうわけわからん数字を人間が読める時間という単位に換算しなければならない。
ので、dfの情報を追加で書き換える。
df["Time"] = pd.to_datetime(df["Time"],unit="ms")ようは「dfの"Time"部分をdatetime(人間が読む時間データ)に換算するよ。unixデータはミリ秒表記なのでオプション引数はmsだよ」ということである。
そしてmpfでグラフとして出力するためには最初の時間のデータがindex形式でなければならない。めっちゃ細かいけどこの部分はprint関数で出力しただけでは区別がつかないので、いざ出力という段階で初めて気づく。ここを乗り越えるのに3時間かかった。

typeでprintするとこういう形式が出てくる。Seriesは「pandasで使用する一次元のリストデータだよ」って言ってるだけ。なのでリストの中身の数値自体の形式が何かは教えてくれていない。
餅は餅屋、こういうのはpadas君に直接聞いた方がいいのだ。
というわけで聞いてみた。「.dtype」で列の中身のデータ型を覗いてみよう。

なるほど、datetime64というものになっている。つまり時間のデータにはなっているということだ。
これで②は解決された(解決していたけど確認にクッソ時間がかかった)。残るは③だ。
の前にこのままグラフ出力しようとしたらどうなるだろうか。試してみよう。
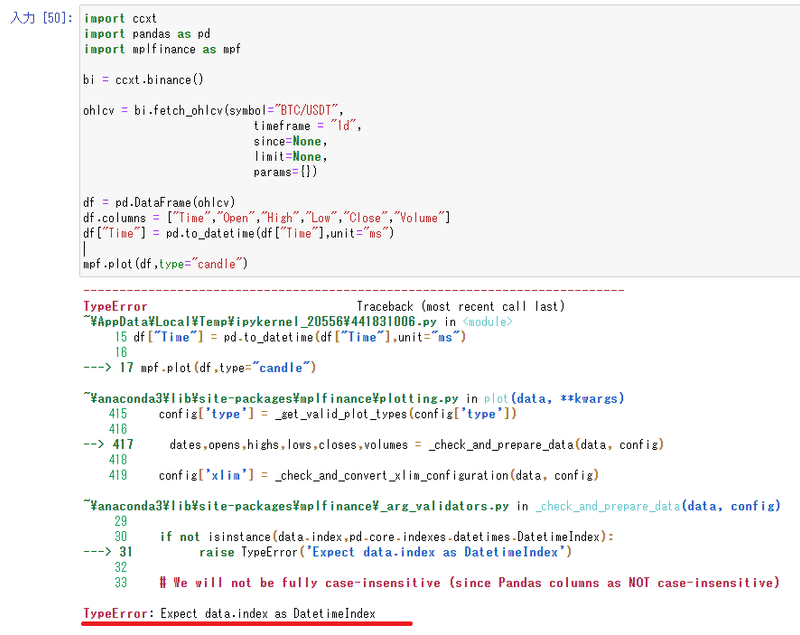
はい、こうなるのだ。
つまり時間の列をインデックスにしろとほざいている。
ちなみに最初に出たエラーがこれだったので、実際の作業では時系列的には一番最初にこれが出た形になっている。
そのくらい空気を読めやと言いたいところではあるが、変な所でカタブツなのもまた憎めない奴よ。
というわけで最後のステップで"Time"の列をindexにする。
必要なのは「.set_index」そのままの名前である。
サクッと追加してしまおう。

set_indexのオプション引数であるinplaceはTrueにすることによって元のdfそのものを書き換えることになる、つまり上書きされることになるので今後何かしらの不便を感じる可能性がある場合は、新しくdfを作った方がいいかもしれない。今回は特に不都合もないのでそのままTrueで続行。
そして例によって型式チェック。今回はtypeで問題ナシ。
結果としては「dfの"Time"列はインデックスであり(インデックスなければエラーが返ってくるはず)、その型式はDatetimeIndexだよ」という返答だったのでノルマ達成だ。
それでは最後にいよいよチャートとご対面といこう。
最初にfetchで呼び出した時に1d、つまり日足と指定してあるため出てくるのは日足のはず。
ローソク足の本数は指定していないため、最大値500本のうち表示できる限りを詰め込んでくれるはずだ。
ではいってみよう。
import ccxt
import pandas as pd
import mplfinance as mpf
bi = ccxt.binance()
ohlcv = bi.fetch_ohlcv(symbol="BTC/USDT",
timeframe = "1d",
since=None,
limit=None,
params={})
df = pd.DataFrame(ohlcv)
df.columns = ["Time","Open","High","Low","Close","Volume"]
df["Time"] = pd.to_datetime(df["Time"],unit="ms")
df.set_index(df["Time"],inplace=True)
mpf.plot(df,type="candle")ドキドキ
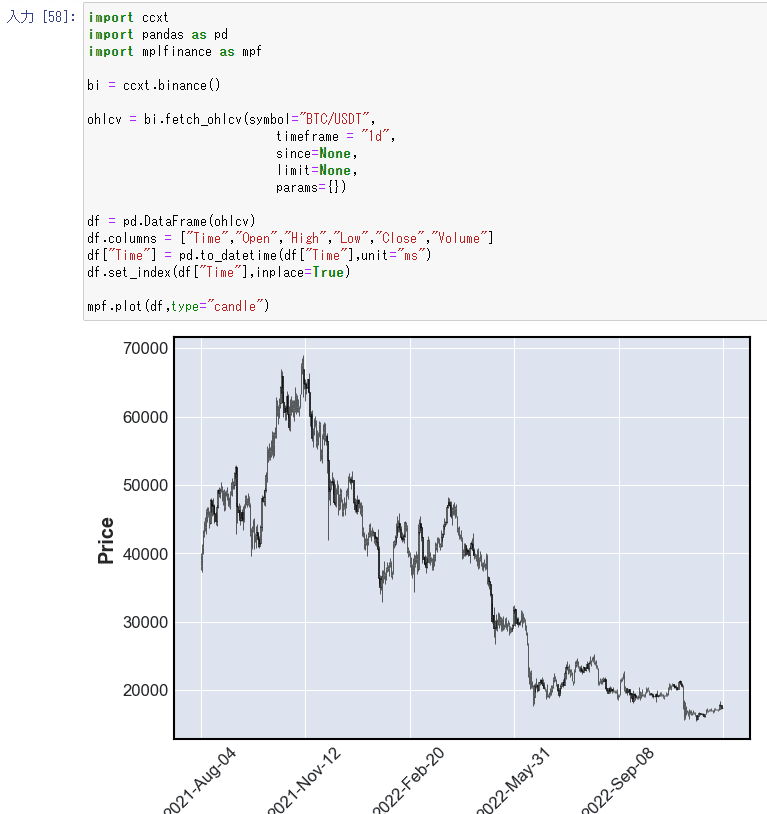
射精の瞬間である。ローソク足がついに描画できた。
細かい範囲指定だったりはやっていないが、形になっただけでも大きな進歩だ。
3つのライブラリの機能を余すところなく使い、自力で達成できた喜びはひとしおなのでしばらくはこの喜びをかみしめたい。
この記事が気に入ったらサポートをしてみませんか?