
手書き文字認識

古典的なMINSTのデータをfast.ai v1で試そうとしたが,バグがあったのでメモしておく.
path = untar_data(URLs.MNIST)
!ls {path}
で保存されたフォルダの中身をみてみると,testing training なっている.MNIST_SAMPLEやTINYと違う名前になっているようだ.
!mv {path}/testing {path}/valid
!mv {path}/training {path}/train
!ls {path}
で名前を変更すれば,あとは同じ手順を踏めばよい.MNISTで画像用の転移学習を奨めている記事もみかけるが,Jeremy Howardが言っているようにセンスが悪い.手書き文字なのでデータ増大にflipを使わないようにして,データを生成しておく.
tfms = get_transforms(do_flip=False)
data = ImageDataBunch.from_folder(path, ds_tfms=tfms)
data.normalize()
アーキテクチャ(モデル)は流行のDarknetで,0から9の10個のクラス分けをするように指示して,これも最近流行のone_cycle学習を10エポックくらい行ってみる.
learn = Learner(data, models.Darknet(num_blocks=[1,2,8,8,4],num_classes=10),metrics=accuracy).to_fp16()
learn.fit_one_cycle(10, wd=0.4)
結果は精度99.63%でhttps://benchmarks.ai/mnistによると,2014年あたりの世界記録のようだ.
Total time: 37:31
epoch train_loss valid_loss accuracy
1 0.155516 0.112672 0.965900
2 0.127156 0.219223 0.930600
3 0.105702 0.232880 0.925400
4 0.085650 0.051214 0.986000
5 0.067089 0.055709 0.982600
6 0.062929 0.066264 0.979300
7 0.050828 0.039139 0.988100
8 0.033654 0.023069 0.991800
9 0.017169 0.011623 0.996200
10 0.014438 0.011073 0.996300
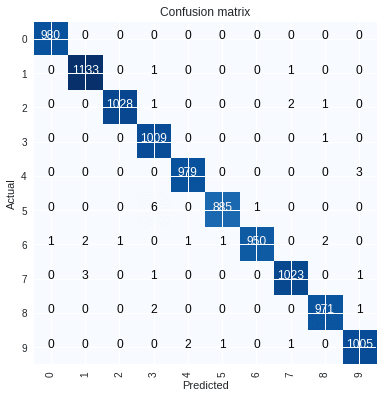
損出関数の値が悪かった9つのデータを表示して,混合行列を出力する.
preds,y,losses = learn.get_preds(with_loss=True)
interp = ClassificationInterpretation(data, preds, y, losses)
interp.plot_top_losses(9, figsize=(7,7))

interp.plot_confusion_matrix()
この記事が気に入ったらサポートをしてみませんか?