読者の行動データを用いたnote記事レコメンドのMLパイプラインツアー

noteにてMLチームに配属されたむっそです。
入社して約3ヶ月くらい経ちましたが、楽しい仲間たちとワイワイ開発やっています。
今回はnoteのMLチームが作っているシステムっていまいち想像つかないよねぇという声(幻聴)がどこからか聞こえた気がしたので、
どんなMLシステムを作っているのかを「MLパイプラインツアー」と題して順を追って紹介していきたいと思います。
はじめに
noteでは、ユーザーの皆様がスキになれるような記事を探し出して、たくさんレコメンドしております。この「スキになれるような記事をレコメンドする」というのがすごく厄介で、いろんな基準があるわけですね。
たとえば、以下のような感じで「noteユーザーがスキになりそうな記事をレコメンドする」仮説をいくつか立てることができそうです。
過去に読んだ記事と近い内容の記事であれば、スキになってくれるだろう
noteでスキをした記事から同じ要素やキーワードを探し出して多く当てはまる記事であれば、スキになってくれるだろう
ユーザーの属性情報と近い他のユーザーが読んだ記事であれば、スキになってくれるだろう
いろいろと考えられそうですね。時間や人がいれば考えられる仮説を片っ端から試したい気分ですね。
仮説であげたようなレコメンド案もありますが、noteではユーザーの行動データをベースに記事を推薦するシステムを一部の機能で採用しています。今回はそのMLシステムの紹介をしていこうかと思います。
MLシステムを紹介するにあたって、「AIエンジニアのための機械学習システムデザインパターン」という良書もあります。noteのシステムのアーキテクチャはこの本で紹介されているデザインパターンの中で言うとどのパターンなのかも後ほど説明します。
※この本を読んでなくてもこの記事は読めます。ご安心ください。
(あとステマじゃないですよ)
読者の行動データを用いたnote記事レコメンドとは
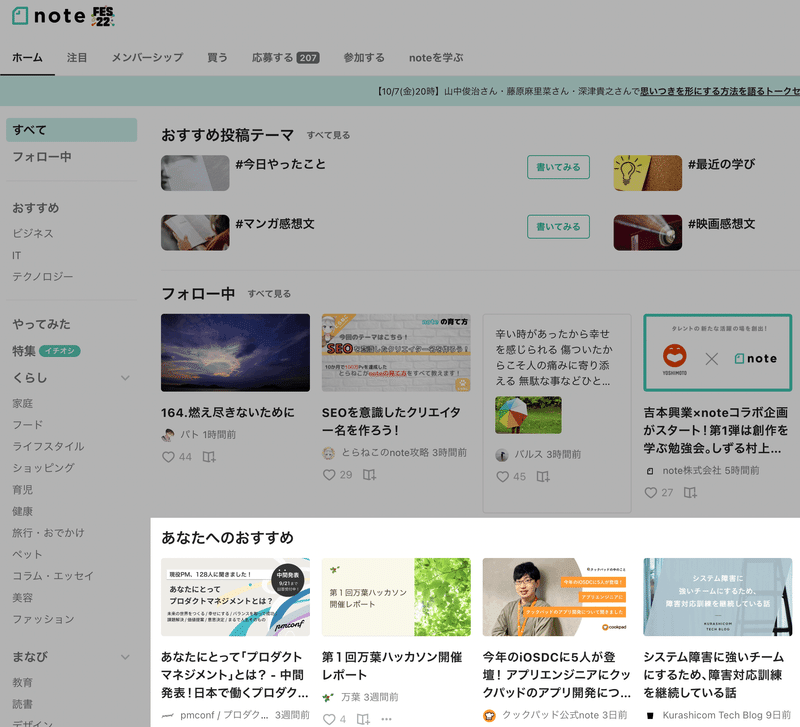

ログイン状態のnoteのトップページでは、上記の画面のような感じで、いくつか記事がレコメンドされています。
私はテック記事とか日常っぽい記事を読んでいるため、私のホーム画面や記事詳細画面あたりでは、そういうカテゴリーの記事が割とレコメンドされています。
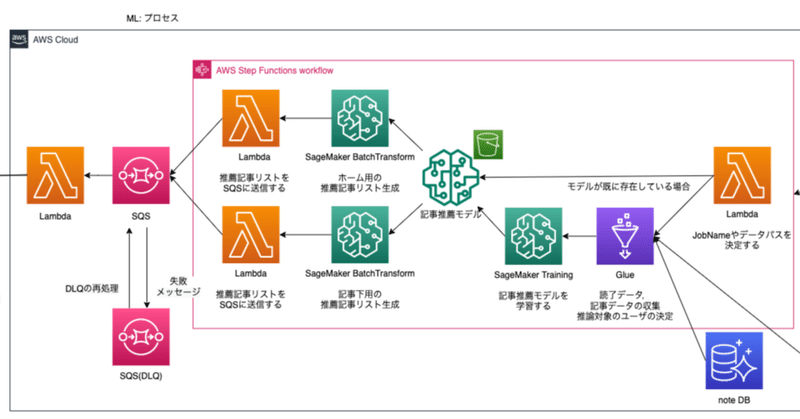
AWSアーキテクチャ
全体的なアーキテクチャはこんな感じです。むずそうに見えると思いますが、ぼちぼち適当に説明するので大丈夫です(多分)
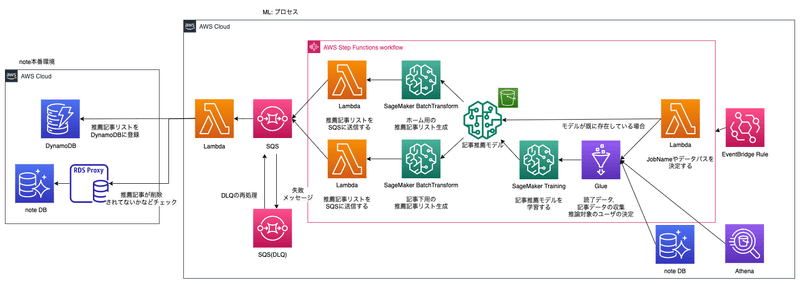
noteのアーキテクチャを、先ほど紹介した「AIエンジニアのための機械学習システムデザインパターン」という本で言えば、以下が当てはまります。
モデルロードパターン:
機械学習モデルはS3に保存してあり、SageMakerのBatch Transformで起動するDockerコンテナにロードして推論する
バッチ推論パターン:
EventBridgeの定期実行により、対象のデータ群に対してバッチ推論を実行する。
MLパイプラインツアー はっじまるよー
上図のAWSアーキテクチャを3つの要素に分割して紹介します。
1.モデル学習/作成プロセス
2.モデルのバッチ推論プロセス
3.バッチ推論結果のDynamoDB登録プロセス
DynamoDB登録後はAPIやフロントエンド側で利用されてますが、今回はMLパイプラインの話に絞って紹介していきます。
超抜粋したコードも載せておりますが、雰囲気でこんな感じの実装なのね、というのを掴んでもらえればと思います。
1.モデル学習/作成プロセス

モデル学習/作成プロセスは3つのステップで進んでいきます。順を追って内容を説明していきますね。
1.1 Step Functionsが目覚める
1.2 Glueで記事推薦モデルや推論に必要な情報を抽出
1.3 SageMaker Training Jobでモデルをトレーニング
1.1 Step Functionsが目覚める
EventBridgeの定期実行でStep Functionsが目覚めます。何時に目覚めるかって?それは秘密ですよ...?
Step FunctionsのはじめにLambdaがいますが、この子は後段のSageMakerのジョブ名を決めたり、モデルが既に作成済みだったら学習フェーズをスキップするなどを決定します。
1.2 Glueで記事推薦モデルや推論に必要な情報を抽出
もし記事推薦モデルが今まで作られてなかったら、Glueでモデル学習に必要なデータなどを揃えてあげます。
記事推薦モデルを作るときに用いる情報や基準はあまり深く書けないかもしれないですが、大体以下のような情報を使用します。
ユーザーが読了した記事情報
みんなからおすすめされてそうな記事(推薦リスト候補)
上記のようないくつかの情報をSQLに落とし込んで、noteのRDSやAthenaなどにクエリを投げて、モデル学習に必要なデータをpickle化してS3に置いていきます。
1.3 SageMaker Training Jobでモデルをトレーニング
Glueで抽出したpickleをSageMaker Training Jobで使用してモデルをトレーニングします。Bayesian Personalized Ranking(BPR)を用いてモデルを学習させます。
import joblib
from implicit.bpr import BayesianPersonalizedRanking
MODEL_PATH = '/opt/ml/model/bpr_note.joblib'
model = BayesianPersonalizedRanking(**hyper_params)
model.fit(training_data)
with open(MODEL_PATH, 'wb') as f:
joblib.dump(model, f, compress=3)処理について簡単に言うと、まずはユーザーIDとnote記事に関する読者の行動データを表す行列をBPRのモデルに学習させます。
そして、この後の推論フェーズの時に、推論したいユーザーIDとnote記事に関する読者の行動データを学習済みモデルに食わせれば、ユーザーごとにどの記事を読んでくれそうかレコメンドできるようになります。
こう書くのは簡単なのですが、SageMaker Training Jobは独特のお作法があったりして結構仕様を理解しながら紐解かないといけない感じですね。
たとえばDockerコンテナ内で作成したモデルをコンテナ内の/opt/ml/modelに置いておけばSageMaker側でS3にアップロードしてくれます。
SageMaker Training Jobの仕様を読み解きつつStep Functionsからどのようなパラメータを受け取っているのかを理解するのがMLパイプラインツアーのポイントです。
SageMaker Training Jobに関しては、Zennに良さげな記事がありました。
私も絶賛勉強中です。頑張ります。
Bayesian Personalized Ranking(BPR)をもっと知りたい方へ
2.モデルのバッチ推論プロセス

2.1 SageMaker BatchTransformで一気に変換
「1.3 SageMaker Training Jobでモデルをトレーニング」で作成したモデルを使用して推論エンドポイントを作ります。
SageMaker BatchTransformの仕様上、/invocations(推論時にたたかれる)と/ping(ヘルスチェック)の2つのエンドポイントを使えるようにしておかなきゃならん感じですね。
from flask import Flask
app = Flask(__name__)
@app.route('/ping', methods = ('GET',))
def ping():
# for health checking
return '200 OK'
@app.route('/invocations', methods = ('POST',))
def estimate():
data = request.get_data(as_text = True)
user_ids = [int(value) for value in data.strip().split(',')]
return jsonify({'model': MODEL_NAME, 'data': Estimator.estimate(user_ids)})Use Your Own Inference Code with Batch Transform(AWS公式)
バッチ推論の結果、最終的には下記のようなデータが生成されます。
そして、ユーザーごとの推薦記事リストの作成が完了します。
{
"data":[
[user_id1, [推薦記事id1, 推薦記事id2, ... 推薦記事id100]],
[user_id2, [推薦記事id1, 推薦記事id2, ... 推薦記事id100]],
[user_id3, [推薦記事id1, 推薦記事id2, ... 推薦記事id100]],
...
]
}3.バッチ推論結果のDynamoDB登録プロセス
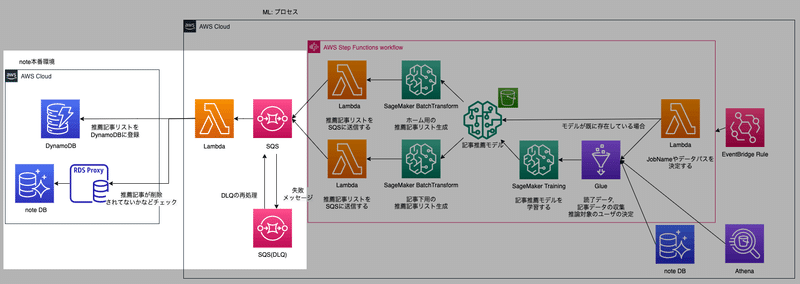
3.1 DynamoDBに推薦記事リストをぶっこむ
「2.1 SageMaker BatchTransformで一気に変換」で作られたデータはSQSに送信されて、LambdaからDynamoDBに投入されます。
読者の行動データが使用できるnoteのユーザーは万単位でいるので、大規模なユーザーに対して推薦記事を登録していることになります。
実はこの部分は私が最近リファクタリングした部分なので、いずれリファクタリングした時の技術的な学びや感想を記事に書こうと思っています。お楽しみに。
あとがき
MLパイプラインツアーいかがでしたでしょうか。
かなりむっその脳内変換が入っていて簡略化しすぎたかもしれないですが、「noteのMLチームのシステムって凄そうやん」って思ってくれたら泣いて喜びます。
この記事読んでいただきありがとうございました。
この記事を読了したという情報はしっかりロギングさせていただいたので、あなたにもっと面白い記事を提供しちゃいたいと思います。
この記事が気に入ったらサポートをしてみませんか?