
読者の行動データを用いたnote記事レコメンドをリファクタリングした話

noteのMLチームで主にMLOps関係の開発をしている、むっそです。
先日「読者の行動データを用いたnote記事レコメンドのMLパイプラインツアー」という題材でMLパイプラインについてご紹介いたしました。
今回はnoteの読者の行動データを用いたnote記事レコメンドをリファクタリングした話をしたいと思います。
※前回の記事をまだ読んでいなくても、この記事は読めます!

AWS環境にてnoteユーザーの行動データを用いたnote記事レコメンド機能を提供しております。
リファクタリング前のAWSアーキテクチャ

行動データを用いたnote記事レコメンドのリファクタリングする前のアーキテクチャを大まかに分解すると、下記のプロセスを実行しています。
モデル学習/作成プロセス
モデルのバッチ推論プロセス
バッチ推論結果のDynamoDB登録プロセス
SQSを責任分界点として、SQSの左側(Consumer)がnoteリポジトリ、SQSの右側(Producer)がMLリポジトリという風にGitHubリポジトリが分かれています。
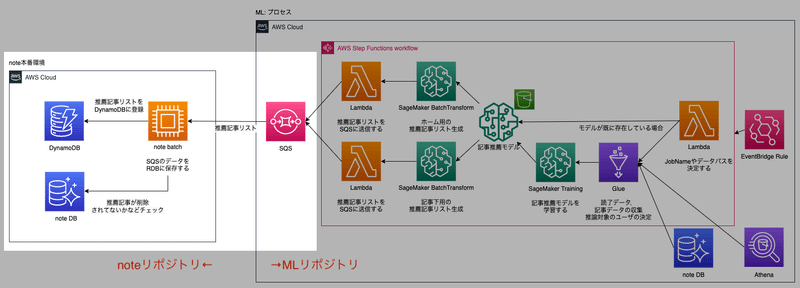
大体いい感じなのですが、プロセスの3.バッチ推論結果のDynamoDB登録プロセス(白くハイライトされているところ)をご覧ください。
noteリポジトリ側にあるbatchサーバーはSQSから下記のようなuser_idごとの推薦記事リストデータを受け取って、DynamoDBに登録する処理を実行しています。
{
"data":[
[user_id1, [推薦記事id1, 推薦記事id2, ... 推薦記事id100]],
[user_id2, [推薦記事id1, 推薦記事id2, ... 推薦記事id100]],
[user_id3, [推薦記事id1, 推薦記事id2, ... 推薦記事id100]],
...
]
}読者の行動データが使用できるnoteのユーザーは万単位でいるので、大規模なユーザーに対して推薦記事を登録していることになります。
上記のアーキテクチャでも機能はしているのですが、いくつか問題点があり、リファクタリングすることにしました。
ではここから「リファクタリング前の問題点」と「リファクタリング後のアーキテクチャ」について具体的に説明していきます。
リファクタリング前の問題点
1. noteリポジトリとMLリポジトリの責任分界点
noteリポジトリは主にRubyで実装されており、MLリポジトリでは主にPythonで実装されています。
パイプライン全体を改善したい場合には、RubyとPythonの両方が書けるエンジニアしか対応できないので、開発がやや難しくなります。
2. スケジュール駆動
noteリポジトリ側のbatchサーバーが1時間おきにSQSを見にいくというアーキテクチャになっており、SQSメッセージがない場合でもメッセージを取得しにいくという無駄な処理が発生しています。
またSQSに最新の推薦データが入ったとしても、noteリポジトリ側のbatchサーバーがSQSメッセージを取りに来るまでに待ち状態が発生します。そのため、即座に推薦記事結果をユーザーインターフェースに反映することができません。
3. 処理の失敗があまり想定されていない
内部的にリトライ処理はしているのですが、失敗したメッセージをどこかにキューイングしておく仕組みではないため、失敗したメッセージは実質無視されています。
4. スケールアップ構成
noteリポジトリ側はデカいインスタンスで一気にSQSのメッセージを吸い取ってDynamoDBに登録するようなアーキテクチャになっているため、単一障害点になっていました。処理の失敗があまり想定されていない実装になっています。
また細かい粒度でのパフォーマンスチューニングがしづらいため、ここを変更するのはちょっと怖い感じです。
リファクタリング後のAWSアーキテクチャ
上記のような問題点があったので、リファクタリングを行いました。

バッチ推論結果のDynamoDB登録プロセスの処理をリファクタリングしました。責任分界点だったSQSの次にLambdaを置いて、noteリポジトリ側のbatch処理は無くなってます。
その結果、下記の通りいくつか改善点が見込めます。

リファクタリング後の改善点
1. MLチームのみで改善が完結する
以前はnoteリポジトリとMLリポジトリの責任分界点が微妙だったことで、パイプライン全体を改善したい場合には、RubyとPythonの両方が書けるエンジニアしか対応できない状態でした。
しかし、今回のリファクタリングでMLチーム側の環境で機能改善が完結するので、改善活動がしやすくなりました。
2.イベントドリブン
noteリポジトリ側のbatch処理が1時間おきにSQSを見にいくというスケジュールドリブンなアーキテクチャに関しては、SQS + Lambdaの構成にすることでイベントドリブンなアーキテクチャになりました。
SQSに届いたメッセージはすぐLambdaが起動してDynamoDBに登録されるので、推薦記事結果をすぐにユーザーへ提供することが可能になりました。
3. 失敗を想定したアーキテクチャ
SQS + Lambdaの構成にする場合、基本的には処理の失敗を考慮してDLQ(デッドレターキュー)を設定することが基本なので、失敗したジョブやメッセージについてはDLQに貯められてDLQの再処理を実行することができます。
下記の記事のようにDLQにメッセージが入ったことを検知してアラートを出す仕組みもあるので、とりあえず失敗してもやり直せるという安心感が生まれました。
4. スケールアウト構成
SQS + Lambdaの構成はスケールアウト構成になっているので、「もう少し同時実行数上げれそうだなぁ」と思ったら、Lambdaの同時実行数を上げれば良いです。
「ちょっと処理が重くてタイムアウトが発生しそうだなぁ」って時はLambdaのメモリサイズを増加したり、SQSから受け取るメッセージ数を減らすといった細かいチューニングがしやすくなります。神です。
Lambdaはどんな実装になったのか
SQSの次にLambdaを置くことでイベントドリブンな感じにしましたが、実際のLambdaのコードの雰囲気を下に書いてます。
雰囲気だけを感じてください(Just feel it!!)
def lambda_handler(event: Dict[str, str], context: Dict) -> None:
# SQSイベントを受け取る
logger.info(event)
try:
recom_items = []
with pymysql.connect(**mysql_info) as conn:
for message in event["Records"]:
body: Dict[str, str] = json.loads(message["body"])
# RDS Proxyからユーザー情報を読み取り、SQSイベントと照合する
for sqs_message in body["data"]:
user_id, note_ids = sqs_message
recommended_items = select_from_rds(conn, user_id, note_ids)
insert_item = {
"user_id": user_id,
"recommended_note_ids": recommended_items,
}
recom_items.append(insert_item)
# DynamoDBに記事レコメンド結果を格納する
DynamodbRecommendedNotes.bulk_update(recom_items)
except Exception as e:
logger.error(str(e) + '\n' + traceback.format_exc())
raise eSQSイベントを受け取って、メッセージをもとにRDS Proxyからユーザー情報を読み取り、DynamoDBに記事レコメンド結果を格納しています。
AWSアーキテクチャ図だけ見ると小難しそうに見えるのですが、こうやってLambdaのコードを見てみると割とシンプルに見えるなぁと思います。
Lambdaを利用することでコードをシンプルにしやすいのが良いですね。
実際に作ってみた感想
全体アーキテクチャに関する感想
責任分界点の決定は重要
MLOpsとはDevOps
スケジュール駆動 vs イベント駆動
オーケストレーション vs コレオグラフィ
単体のデカインスタンス vs 大量のミニインスタンス
1.責任分界点の決定は重要
リファクタリング前のアーキテクチャではSQSのProducer(生産者)をMLリポジトリ側、SQSのConsumer(消費者)をnoteリポジトリ側という感じにしていました。
しかし、MLチームが改善活動をしやすくするためにリファクタリング後のアーキテクチャではDynamoDBの登録をMLリポジトリ側、DynamoDBの検索をnoteリポジトリ側という責任分界点にした方がうまく機能しそう、ということで改善しました。
このような「どこを責任分界点とするのか」という話はどのようなシステムでもありそうですよね。
・APIを作る側が基盤チーム、APIを利用する側がビジネス開発チーム
・DBを作って登録する側が基盤チーム、DBを利用する側がビジネス開発チーム
みたいに決めて、どこを責任分界点にすればみんながハッピーになれるのかというのは早めに計算して決め切るのが重要なポイントかと思いました。
可能であれば、複数開発言語を用いないような環境や、複数リポジトリを跨いだりする手間のないようなシステム構成がやりやすいと思います。
コンウェイの法則とかそういう話も入ってくるのかなと思います。要件やチーム組織次第で最適解は変わってくると思うので、皆様もいい感じに頑張ってください。
2.MLOpsとはDevOps
私は前職とかでメインはバックエンド/サーバーサイドらへんが中心だったので、MLエンジニアというとなんか高度なアルゴリズムや論文などを読んで実装しなきゃならないみたいなイメージがありました。
しかし、このようなリファクタリングをしてみて、システムをどのようにユーザーに提供するべきか、開発・運用の保守性をどうやって高めるか、テストやログ出力はちゃんとやっているかという話はMLシステムにも当然必要なんだよなぁということを強く感じれました。
MLOpsで大事なことは、ちゃんとDevOpsをしていくことなんだなと気づくことができました。
3.スケジュール駆動 vs イベント駆動
深夜のバッチ処理などはスケジュール駆動なアーキテクチャがふさわしいです。しかし、スケジュール駆動のアーキテクチャのシステムが多くなってくるといくつか問題が生じるポイントがあるのかなぁと思います。
たとえば以下のような事項です。
毎分ポーリングするような前提でアーキテクチャを考えてしまうとLambdaよりEC2を採用だ!という結論になってしまいがち。その結果、管理コストが増えてしまう
指定した時間にならないと推論結果がデータベースに反映されないというシステムだとユーザー体験に影響を与える可能性がある
要件によって取るべきアーキテクチャは決めていきたいですが、基本的にイベント駆動なアーキテクチャを採用していければなぁと感じました。
4.オーケストレーション vs コレオグラフィ
マイクロサービスでワークフローを構築する際にいくつかパターンがあります。
Step Functionのような全体ワークフローの指揮者が、LambdaやSageMakerなどの各種サービスを制御するパターン(オーケストレーション)
SQS/Lambdaのようにイベントのpubsubによってサービス間の結合をして全体ワークフローの指揮者のような存在がいないパターン(コレオグラフィ)
オーケストレーションパターンであれば、複数サービスが紐づいているワークフローでも監視がしやすく、管理の煩雑さに悩むということは減りそうです。コレオグラフィパターンであれば、全体フローの管理は煩雑になるかもしれないですが、Step Functionのようなワークフロー定義を管理する必要がなく、機能変更などを疎にしやすいアーキテクチャになるメリットがあります。
どのようなアーキテクチャパターンがみんなにとって幸せなのかというのは全体システムの要件定義やシステム設計段階でちゃんと考えておきたいところですね。
5.単体のデカインスタンス vs 大量のミニインスタンス
大量のメッセージをキューイング/処理して、失敗したメッセージがあれば簡単に再処理実行したいという場合は、Lambdaみたいな小さいインスタンスを利用して同時並列性が高くなるような仕組みを使った方が良さそうです。
画像の加工などの重たいデータ処理の場合は、SageMaker Processing/EC2のようなデカインスタンスのマシンパワーで殴るみたいにした方が良さそうです。しかしながら、大きいタスクでも分割してLambdaで処理できるレベルにブレークダウンするということもできると思います。
Lambdaは昔に比べてかなりアップデートされているので、使えるユースケースは増えています。私自身はシステム設計の初めの段階でLambdaが使えるユースケースかな?と考える思考回路になってます。
どのAWSサービスを使ったら良いのかは結構悩みどころですが、システム設計段階で色々調査しておいた方がいいなと思いました。
実装のしやすさに関する感想
RDS Proxyはエポックメイキング
用意されたLambda Layersを使うとラク
負荷に関するパラメータチューニングはムズイ
1.RDS Proxyはエポックメイキング
RDS + Lambdaという構成は昔はアンチパターンとされてました。
しかしながらRDS ProxyというサービスがあるおかげでLambdaの同時実行処理やコネクションに関する心配が減りました。
しかもRDS Proxyの使い方は簡単で、RDSエンドポイントをRDS Proxyが提供するエンドポイントに変えるだけなので、めっちゃ使いやすいです。
エポックメイキング!
2.用意されたLambda Layersを使うとラク
ライブラリインストールや環境構築はいつの時代も煩わしいですね。
Lambdaの場合だとよく使われるライブラリ(numpy, pandasなど)はLambda Layersで簡単に扱えるようになっています。
機会があればぜひ使ってみることをおすすめします。
3.負荷に関するパラメータチューニングはムズイ
「エイヤッ」で本番環境デプロイをしてしまうと、本番環境負荷周りで失敗しまくる可能性があるので、本番環境に近い環境で負荷試験をしてちゃんと構成を考えていきましょう。(反省)
というか人間は失敗する生き物なので、失敗を前提としたアーキテクチャにしておくのが良さそうです。
うまくやらないとLambdaのスロットリングが多発して数回リトライしてもDLQに入ってしまうなどが起きてしまいます。
(私の失敗を受け入れてくれたDLQには感謝してもしきれない、DLQありがとう)
DynamoDBの書き込みキャパシティの調整、Lambdaの同時実行数やタイムアウト、SQSメッセージのバッチ数の最適解などチューニングすべきポイントはあるのでメトリクスを見ながら、ちゃんと考えていきたいと思いました。
あとがき
今回はすごい大規模リファクタリングをしたという感じではないのですが、こういう改善活動を通じて全体アーキテクチャを設計する重要性などを学べたので良い経験になりました。
またnoteは大規模に記事/画像データを持っている会社なので、たくさんのデータに触れることができます。この環境で機械学習の改善ができるというのは、エンジニアとして幸せなんだろうなぁとしみじみ思いました。
いろんな職種でカジュアル面談などもやっていますのでご興味を持っていただけたら嬉しく思います。
読んでいただきありがとうございました。
この記事が気に入ったらサポートをしてみませんか?