
インタビュー調査の文字起こしから、QDAソフトを使ったグラウンデッド・セオリー・アプローチによる分析まで

大学や大学院で研究しているうちに、「質的研究」をすることになった、という方もいらっしゃると思います。
その中でも特に、インタビュー調査から「グラウンデッド・セオリー・アプローチ」を使うことになったけど、やり方が全然分からない、という方もいらっしゃるのではないでしょうか。
こうした研究方法について詳しい書籍もありますが、かなりアナログな方法を紹介していたりして、今の時代に適していないものもあります。
今回は、2021年度に私が取り組んだ修士論文のために用いた、インタビューの文字起こしから、質的研究の専用ソフトであるQDAソフトを用いた分析方法までを簡単にご説明します。
これから卒論や修論を書く学生の方。
インタビュー調査を分析しなければならないけど方法が分からない方。
研究方法について学びたいという方。
グラウンデッド・セオリー・アプローチってどんなものなのか見てみたい方。
そんな方々の参考になれば幸いです。
インタビュー調査の文字起こし
まずは、インタビュー調査の録音データが必要です。
インタビュー調査の方法については省略しますが、インタビューガイドの用意、相手へのアポイントメント、所属機関による倫理審査などをクリアする必要があります。
最近はオンラインでのインタビューも可能ですし、Zoomのレコーディングなどを活用することもできます。
Wordを使った自動も文字起こし
文字起こしには、Wordの「ディクテーション」機能を使うのがおすすめです。
精度もかなり高く、設定をすれば句読点も打ってくれます。
Wordの「ホーム」タブから「ディクテーション」を選び、下の方に出てくるウインドウの歯車マークから、話し手の言語と句読点挿入、「機密の語句」の設定ができます(後者の設定は不要です)。
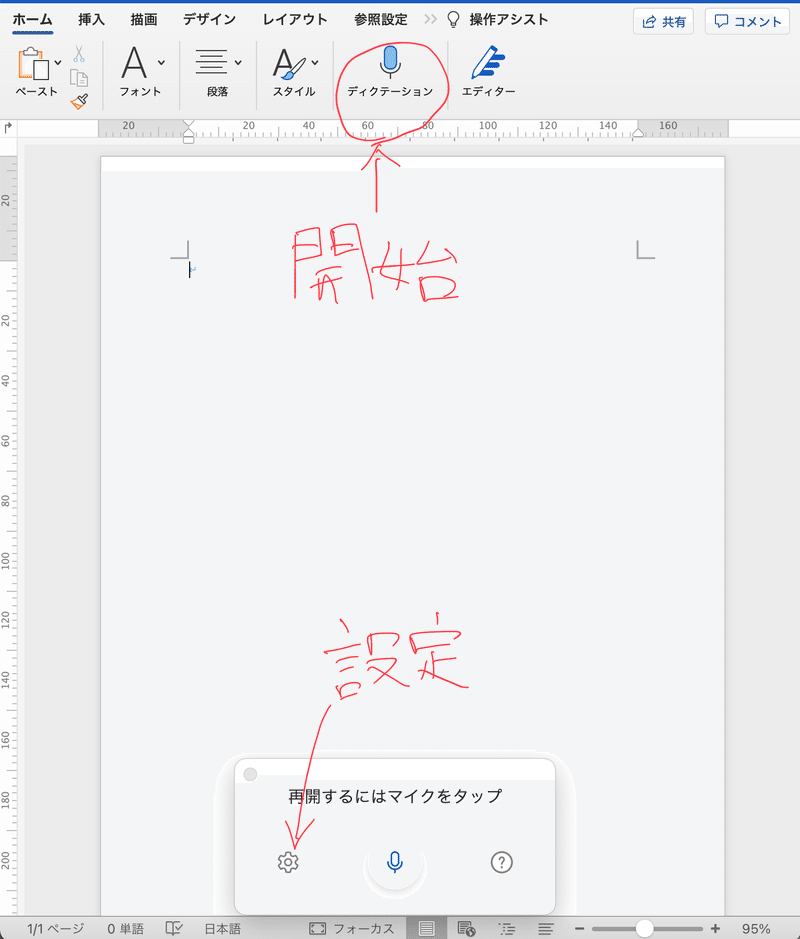
ここで下のウインドウの真ん中のマイクボタンを押せば書き起こしを開始してくれます。
一番簡単なのは、PC以外の機器で録音を再生して、PCのマイクで拾ってもらう方法です。
特別な設定がなくてもどんどんディクテーションしてくれますが、ディクテーションしている間は静かにしていないといけないのが難点です。
その他にも、同じPCで音声を流して、それをWordで聞き取ることでディクテーションする方法もあります。
Macでの使用法については、この記事が参考になります。
この記事ではGoogleドキュメントを使っていますが、現時点ではWordの方が句読点を打ってくれるので、優秀だと思います。
今回はテストとして、以上の方法で私のstand.fmでの配信を文字起こししてみました。
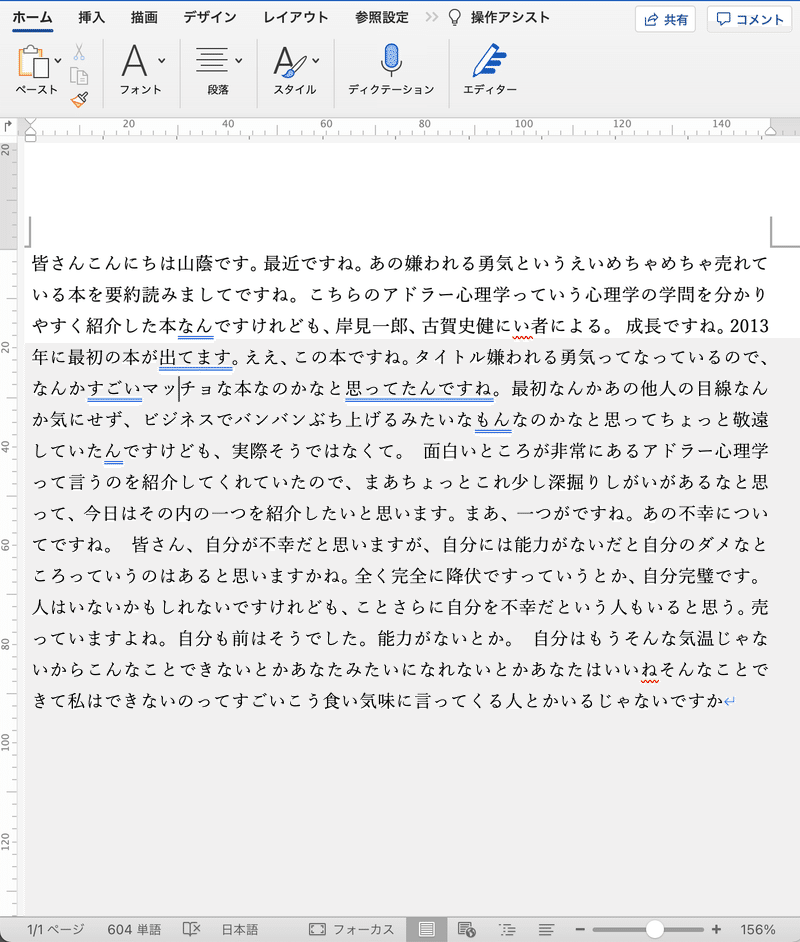
文字起こしの微修正
自動の文字起こしでもかなり優秀ですが、固有名詞や句読点、「あの」などの言葉をとったりする必要があります。
ここからは手作業で修正していきます。
録音を流して、違うなと思ったところで一時停止して、該当箇所を修正します。

またインタビュー対象者の名前など、隠す必要がある固有名詞は、このタイミングで匿名化するといいと思います(「Aさん」などに置き換える)。
Wordの置換機能を使うと楽ですが、そもそもの認識精度が完璧ではないので、最終的には全て目を通して確認する必要があります。
この作業は専用のソフトを使わなくても、再生・停止さえできれば大丈夫です。
私は以前有料のソフトを買っていたので、それを使用して修正を行いました。
再生速度変更や再生・停止をキーボードショートカットでできるので、非常に楽です。
無料期間もあったと思うので、一時的に使えればいい人は、その期間だけ使うのもありだと思います。
ここまで来れば、文字起こしは完成です。
QDAソフトを使った分析の方法
ここからは、質的研究の専用ソフトであるQDAソフトを用いた分析方法を紹介します。
質的研究自体は、専用のソフトがなくても、手書きやwordを使ってやることもできますが、所属機関にあるなどQDAソフトがある場合は使ってみるといいと思います。
高価なので学生が個人で買うのはおすすめしませんが、大学の先生が貸してくれる場合もあるので、聞いてみるといいと思います(私も指導教員から借りました)。
今回使用しているバージョンは、MAXQDA Analytics Pro 2020 (Release 20.4.1)です。
バージョンが変わると動作が変わると思いますので、参考までにご覧ください。
データの取り込み
まずは、先ほど文字起こししたWordファイルを、QDAソフトがあるパソコンに、メールやUSBメモリなどを使って移動します。
QDAソフトを開き、「新規プロジェクト」をクリック。
左上の「インポート」のタブから、「テキスト、PDF、表」をクリックして、持ってきたWordファイルを選択します。
すると、以下のような状態になると思います。
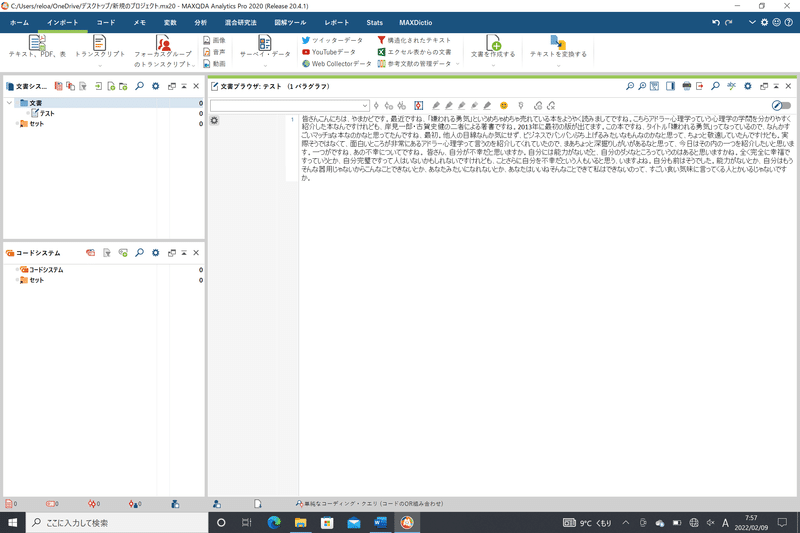
左上の「文章システム」の中に、「テスト」というファイルが入っていることが分かるでしょうか。
これが、今インポートしたwordファイルです(複数文章をインポートすると、ここが増えていきます)。
今回はテストのため、1つの短い文章でやってみます。
切片化(文章を内容ごとに切り離す)
ここから分析のための作業に入っていきます。
分析の方法には様々なものがありますので、詳しくは文献を用いて確認してください。
私が今回使用したのは、以下の文献で説明されている、いわゆるストラウス派のグラウンデッド・セオリー・アプローチです。
まずは、文章を内容ごとに切り離す「切片化」という作業を行います。
インタビューの文字起こしは、話し言葉なので、長い文章がだらだらと続いてしまっていることがあります。
そのため、内容ごとに改行して、切り離された一つの切片が、一つの意味を持つようにします。
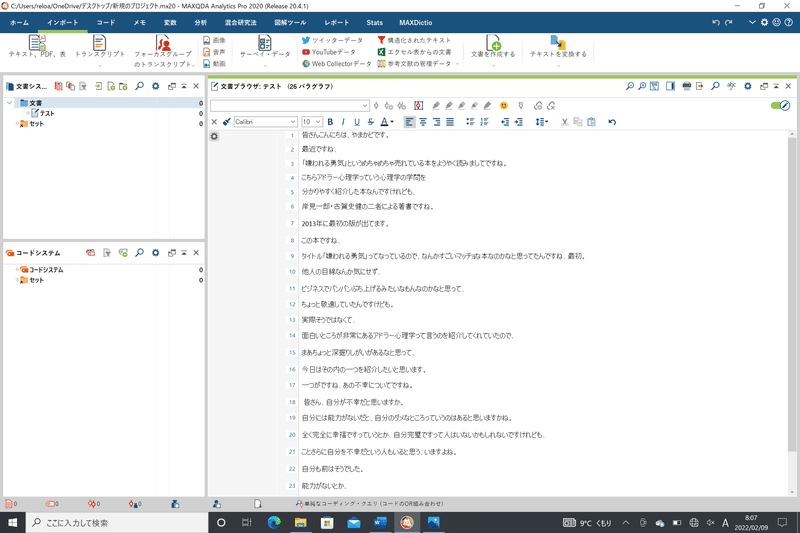
必ずしも句読点で区切る必要はありません。
話し言葉は文法も正しいとは限らないし、一文が長くなる傾向があるからです。
コーディング(切り離した切片に名前をつける)
前項で作成した切片に対し、それを代表するような名前を付けていきます。
切片の行番号を右クリックして、「選択されたセグメントにメモを挿入する」を選択します。
現れたウインドウに、この切片から分かることを書いていきます。
ここの方法には様々な流派がありますが、今回私が参考にした文献では、一つの切片に対して「プロパティ」と「ディメンション」を付けます(この辺りは流派によって異なりますし、詳細は文献を確認ください)。
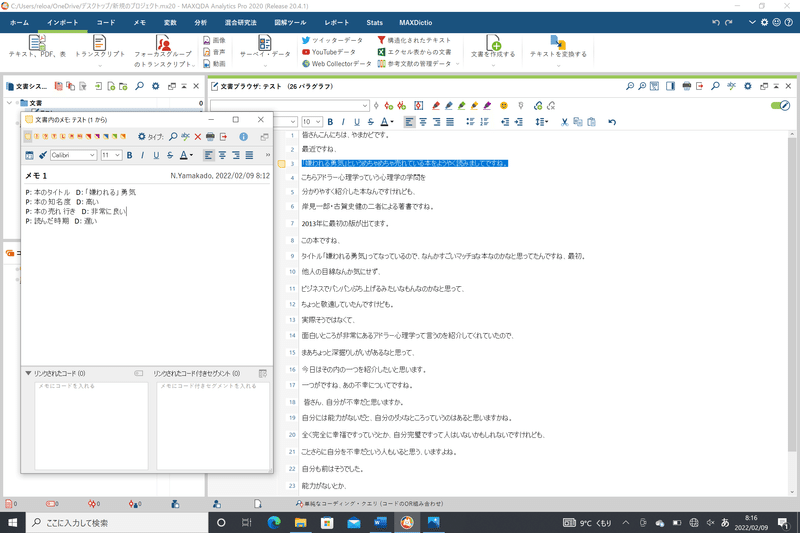
私の場合は、「プロパティ」をP、「ディメンション」をDとして、略してメモに記入していきました。
今度は、今のメモを参考にしながら、この切片を代表する名前を付けます。
行番号を右クリック、「新しいコードで」を選択。
現れるウインドウの一番上の空欄に、名前を付けます。
後々コードをたくさん付けていく時には、色を使い分けると整理しやすいです。
例えば、話者の考えは青、行動は黄色、その他は赤、などです。
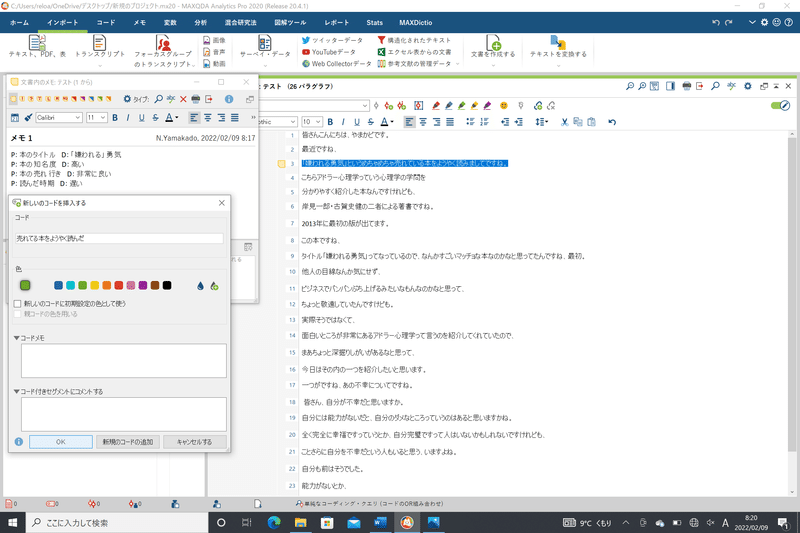
これによって、左下の欄に作成したコードが表示されていきます。
他の切片に対しても繰り返して、このコードをたくさん作っていきます。
コードをカテゴリー化する
このようにしてたくさんのコードができたら、今度はこれをグループに分けていきます(カテゴリー化)。
作成したコードは、左下の「コードシステム」にどんどん貯まっていきます。
それらのコードの中から、名前付けるときに用いた「プロパティ」と「ディメンション」を見ながら、共通点があるコードをまとめていきます。
やり方の例としては、1つ大きいくくりのコードを作成します(コードシステムの欄を右クリック→「新しいコード」から)。
そして、その大きいコードにまとめたいコードをドラッグして、大きいカテゴリーの上で離します。
そうすると、以下の画像ように階層ができます。
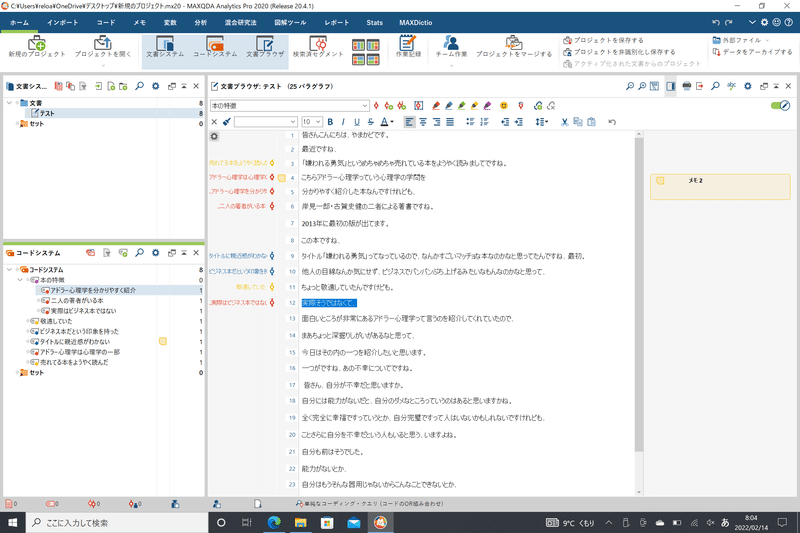
今回の場合は、「本の特徴」の下に3つのコードを含めてみました。
この親コードをたくさん作って、たくさんのコードを整理していくことになります。
その後の流れ
その後は整理されたコードを使って、分析結果を図で表すことになります。
ここからは研究によって方法が全然異なると思いますので、詳細は割愛します。
一人分の分析ができたら、ここからはひたすら同じことの繰り返しになります。
インタビュー調査→文字起こし→分析、それを受けて次のインタビュー・・・という流れが理想です。
実際には、学生の場合時間の制約があるので、どこまで理想的な方法でできるかは分かりません(私も全てのインタビュー調査が終わってから分析を始めました)。
しかし、こうした流れを理解した上で取り組むことが必要だと思います。
参考:私の修士論文
参考までに私の修士論文では、分析の結果を一番大きくまとめた「現象」が1つ、その次に大きなくくりの「カテゴリーグループ」が5つ、最小単位の「カテゴリー」が31個を採用することになりました。
しかし、研究の途中で使わなくなったり、まとめてしまったコードを含めると、943個を作成していました。
全てのコードに丁寧なプロパティとディメンションを付けていた訳ではないですが、結構大変でした。
これだけ付けることが正しいのかは分かりませんが、とりあえず付けて使う・使わないは後で判断、ということでもいいのかなと思います。
研究方法はしっかり勉強して使おう
以上でインタビュー調査の文字起こしから、QDAソフトを用いたグラウンデッド・セオリー・アプローチによる分析の方法までを簡単にご説明しました。
今回の記事では、いくつかのソフトを用いて研究を円滑に進める方法をご紹介しました。
実際に研究する際には、分析の方法についてはしっかり学んだ上で取り組んでいただければと思います。
研究方法の意味が分かっていないで、ソフト周りの知識だけが頭でっかちになってはいけません。
また研究方法の選択も重要です。
今回紹介したグラウンデッド・セオリー・アプローチ以外にも様々な研究手法がありますし、グラウンデッド・セオリー・アプローチの中にもいくつかの流派があります。
ぜひ研究の幅を広げて、分析に挑戦してみてください。
今回はかなりニッチな話題でしたが、一人でも「役に立った!」という方がいれば幸いです。
最後までお読み頂き、ありがとうございました。
最後までお読みいただき、ありがとうございました。 私の積読増殖(そして読書)のために、サポートいただけると嬉しいです!