「Aidemy データ分析コース」の振り返りと作成物についてまとめました

目次
自己紹介とプログラミング学習のきっかけ
Aidemyの学習振り返り
作成物について
終わりに
自己紹介とプログラミング学習のきっかけ
「プログラミングを学習して未経験からエンジニアに!」とか、
「プログラミングを学習して独立を目指す!」
というような話題がホットですよね。
ですが悲しいかな。
私は情熱を持ってプログラミング学習をスタートした訳ではないんです。
そんな私のプログラミング学習のきっかけをお話しします。
私はとある電子部品メーカーで働く一人のサラリーマンです。
大学は化学を専攻していたのですが、現職では回り回って電子部品の開発をしています。
そんな私は仕事の関係で、システム関係の業者とやりとりすることが増えました。
これまで全く触れたことのない分野でしたが、ああでもないこうでもないと試行錯誤しながら業者とやりとりをしていたわけですね。
そんな中、私は思うわけです。
「あーコレ私にプログラミングの知識があった方が話が早いな」と。
システムの仕様は私が考えるものの、実際のコーディングだとかが完全に業者任せ。
実際に動かすとエラーが多かったりで、なんとも効率が悪い・・・
といった事情から、プログラミングを触ってみるかと考えたわけです。
プログラミング的な思考を身につけたかったというのも理由にあります。
そんなこんなで、「なんか仕事に活かせるかなー」程度の軽い気持ちでスタートしたんですね。
とりあえず将来腐らなそうな領域のAIに注目して、AIに特化したAidemyさんのお世話になる。というのが学習を始めた経緯です。
独学も視野に入れたんですが、Aidemyさんで学んだ方が手っ取り早いかなと考えました。
プログラミングスクールってその必要性の是非が分かれると思うんですが、まぁ「目的」とか「かけられる時間」とか「理解力」とかは人それぞれ違うんでね。
みなさんいい大人なんで、各々で必要性を判断すれば良いんじゃないでしょうか。
私は「時間をお金で買った」と思ってます。
Aidemyの学習振り返り
Aidemy データ分析コースでの学習内容を以下にまとめます。
よくある入門書にある内容を、わかりやすくまとめてある感じでした。
私の場合は特に躓いた所はなかったですが、Aidemyさんのテキストをみて、自分の理解が合っているかを他のサイトさんで調べて確認したりしてました。
プログラミング初学者の方でも、基礎から学ぶことができるのは非常に良い点かなと。
逆に既にプログラミングの前提知識がある方からすれば、少し退屈だったりするかもしれません。
受講者のレベルに応じてカリキュラムを少し変えることができると良いんですけどね。
難しいのだと思いますが。
1 Python 入門
【内容】
文字の出力、変数の概要、条件分岐、ループなど、「Python」
の基本的な使い方の習得
2 Numpy
【内容】「NumPy」を用いた効率的な科学技術計算の習得
3 Pandas
【内容】「Pandas」を用いた数表や時系列データの計算の習得
4 Matplotlib
【内容】 「matplotlib」 を用いたデータの可視化。
折れ線グラフ、円グラフ、ヒストグラム等や 3D グラフを作成
の習得
5 データクレンジング
【内容】CSV データの扱い方や欠損値の処理、OpenCV を
用いた画像加工の方法の習得
6 データハンドリング
【内容】 Python を用いてテキストや .csv を始めとするビジネスデータの収
集・加工・結合・マスター化等を通じて「意味あるデータ」に
整形する技能の習得
7 機械学習概論
【内容】 教師あり学習や教師なし学習、各アルゴリズムなどを網羅的に
整理・理解する
8 教師あり学習(回帰)
【内容】 数値予測などを行う「回帰」モデルの実装方法を習得
9 教師あり学習(分類)
【内容】画像や文章などをカテゴリ分けする「分類」モデルの実装方法を習得
10 教師なし学習
【内容】正解ラベルが付いていないデータセットを使って機械学習モデルを作る手法
クラスタリングや主成分分析といったアルゴリズム
の手法の習得
11 時系列分析
【内容】トレンドを除去しながら数値予測を行う手法に習熟し、時系列分析を実装する技術を身に付ける
12 機械学習におけるデータ前処理
【内容】実務で必須となる前処理をスマートに実装するためデータ前処理
13 ディープラーニング基礎
【内容】深層学習(ディープラーニング)のアルゴリズムの詳細と実装について。
14 自然言語処理
【内容】文章を数値に変換する手法を学び、教師あり学習(分類)を使ってカテゴリ分類に挑戦
15 株価予測
【内容】自然言語処理と時系列分析を用いて、株価の予測を行う
複数の情報をかけ合わせて 1 つの予測値を導出する方法を習得する
16 タイタニック号
【内容】1912 年に発生したタイタニック号沈没事故のデータを用い、生存率の予測を行うでも通用するデータ分析能力を身につける
学習したデータ分析の技術について復習し、kaggleでも通用するデータ分析能力を身につける
作成物について
「データ分析コース」を一通りこなして、作成したものを簡単に紹介します。
私が作成したものは「映画レビュー分類」のコードです。
なおこちらのコードについては、Aidemyとは別で機械学習参考書を使って学習した際に、書いたコードをアレンジしたものです。
以下紹介する「映画レビュー分類」には自然言語処理の一分野である「感情分析」の手法を使用しています。
機械学習のアルゴリズムを使用し、レビューの書き手の意見を肯定的/否定的に分類します。
私がプログラミング学習を始めたきっかけは本業で活かすという点なのですが、この自然言語処理は本業で使うわけではないです。
じゃあなぜ自然言語処理を作成物に選んだかというと、学習を始めた当初とは私の業務内容が少し変わったためです。
そこで本業ではなく、副業の方で活かせそうな自然言語処理についてスキルアップしたいと感じ、勉強することにしました。
その点は悪しからず。
実行環境
python 3.6.9
scikit-learn 0.17.1
jupiter notebook 2.2.6
大まかな流れは以下です。
1.モジュールなどのインポート
2.データの取得と確認
3.データの前処理
4.データの分割
5.ベクトル化とラベル変換
6.TF-IDFを使った単語の重み付け
7.機械学習モデルのトレーニングとテスト
8.結果のまとめと考察
今回は既存のデータセット「IMDb(インターネット・ムービー・データベース)」を使用しています。
このデータセットは「肯定的」あるいは「否定的」に分類される50000件の映画レビューから構成されています。
このデータは星1〜星10までの10段階評価となっており、星6以上が「肯定的」という分類になっています。
1.モジュールなどのインポート
機械学習に必要なモジュール、ライブラリ、パッケージを有効にします。
##モジュールの導入
import os
import sys
import tarfile
import time
import pyprind
import pandas as pd
import numpy as np
import seaborn as sns
from sklearn.model_selection import cross_val_score
import matplotlib
import matplotlib.pyplot as plt
from scipy.stats import skew
from scipy.stats.stats import pearsonr
from scipy import stats
from scipy.stats import norm
from sklearn.preprocessing import StandardScaler
from IPython import get_ipython
get_ipython().run_line_magic('matplotlib', 'inline')
from pandas import ExcelWriter
from math import sqrt
from scipy.stats import norm, skew
from scipy.special import boxcox1p
from sklearn import preprocessing
from sklearn.model_selection import train_test_split
plt.style.use('bmh')
from nltk.corpus import stopwords
from nltk.stem import PorterStemmer
from nltk.tokenize import TweetTokenizer
import string
import re
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer2.データの取得と確認
既存のデータセット「IMDb(http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz)」を取得します。
##データセットの取得とデータ処理前の確認 #データセット取得
source = 'http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz'
target = 'aclImdb_v1.tar.gz'
def reporthook(count, block_size, total_size):
global start_time
if count == 0:
start_time = time.time()
return
duration = time.time() - start_time
progress_size = int(count * block_size)
speed = progress_size / (1024.**2 * duration)
percent = count * block_size * 100. / total_size
sys.stdout.write("\r%d%% | %d MB | %.2f MB/s | %d sec elapsed" %
(percent, progress_size / (1024.**2), speed, duration))
sys.stdout.flush()
if not os.path.isdir('aclImdb') and not os.path.isfile('aclImdb_v1.tar.gz'):
if (sys.version_info < (3, 0)):
import urllib
urllib.urlretrieve(source, target, reporthook)
else:
import urllib.request
urllib.request.urlretrieve(source, target, reporthook)
if not os.path.isdir('aclImdb'):
with tarfile.open(target, 'r:gz') as tar:
tar.extractall()<データセットをDataFrame形式に変換>
個々のテキストファイルを読み込み、dfというDataFrameオブジェクトに追加して一まとめにしています。
また行の順番をシャッフルしておきます。
その後一度データをcsvファイルとして保存しておきます。
#データセットの変換
basepath = 'aclImdb'
labels = {'pos': 1, 'neg': 0}
pbar = pyprind.ProgBar(50000)
df = pd.DataFrame()
for s in ('test', 'train'):
for l in ('pos', 'neg'):
path = os.path.join(basepath, s, l)
for file in os.listdir(path):
with open(os.path.join(path, file),
'r', encoding='utf-8') as infile:
txt = infile.read()
df = df.append([[txt, labels[l]]],
ignore_index=True)
pbar.update()
df.columns = ['review', 'sentiment']
#行のシャッフル np.random.seed(0)
df = df.reindex(np.random.permutation(df.index))ここでデータの中身を見てみます。
#データの確認
df.info()
print("Total Samples for Positive Sentiments: ",len(df[df["sentiment"]==1]))
print("Total Samples for Negative Sentiments: ",len(df[df["sentiment"]==0]))
print("Total Samples which do not have reviews: ",len(df[df["review"]==None]))
print(df["review"].iloc[0])
####実行結果
<class 'pandas.core.frame.DataFrame'>
Int64Index: 50000 entries, 11841 to 2732
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 review 50000 non-null object
1 sentiment 50000 non-null int64
dtypes: int64(1), object(1)
memory usage: 1.1+ MB
Total Samples for Positive Sentiments: 25000
Total Samples for Negative Sentiments: 25000
Total Samples which do not have reviews: 0
My family and I normally do not watch local movies for the simple reason
that they are poorly made, they lack the depth, and just not worth our time.
<br /><br />The trailer of "Nasaan ka man" caught my attention, my daughter
in law's and daughter's so we took time out to watch it this afternoon.
The movie exceeded our expectations. The cinematography was very good,
the story beautiful and the acting awesome. Jericho Rosales was really
very good, so's Claudine Barretto. The fact that I despised Diether
Ocampo proves he was effective at his role. I have never been this touched,
moved and affected by a local movie before. Imagine a cynic like me
dabbing my eyes at the end of the movie? Congratulations to Star Cinema!!
Way to go, Jericho and Claudine!!
positive/negativeのレビューが25000件ずつで、欠損しているレビューもないので補完の必要はないですね。
もし欠落がある場合は、バイアスがかかってしまうので欠損値の削除したり、代表値で埋めたりする処理を行う必要があります。
また、htmlタグなどが含まれているので、これは事前に除去する必要があります。
3.データの前処理
<前処理用関数の定義>
今回データ前処理用に作成した関数は以下の通りです。
簡単にですが解説していきます。
def process_string(text):
#urlの除去
text = re.sub(r"https:\/\/.*[\r\n]*","",text)
text = re.sub(r"www\.\w*\.\w\w\w","",text)
#htmlタグの除去
text = re.sub(r"<[\w]*[\s]*/>","",text)
#ピリオド等の除去
text = re.sub(r"[\.]*","",text)
#トークン化
tokenizer = TweetTokenizer(preserve_case=False,strip_handles=True,reduce_len=True)
text_tokens = tokenizer.tokenize(text)
#Porterステミング
porter_stemmer = PorterStemmer()
#ストップワードの除去
english_stopwords = stopwords.words("english")
cleaned_text_tokens = []
for word in text_tokens:
if((word not in english_stopwords) and
(word not in string.punctuation)):
stemmed_word = porter_stemmer.stem(word)
cleaned_text_tokens.append(stemmed_word)
#リストを結合
clean_text = " ".join(cleaned_text_tokens)
return clean_text・URLやhtmlタグ、ピリオドなどの削除
→レビューにはhtmlタグやURLに関わる記号が含まれています。
これらは感情分析をするのにノイズになるので除去しています。
このコードについては、正規表現についての私の理解が浅いので、
公式文書等を参考にしています。
・トークン化
→文章を空白文字で区切ることで、ここの単語に分割しています。
・Porterステミング
→ステミング (stemming) はこのような語形変化を取り除き、
同一の単語表現に変換する処理です。
ここでは各単語をそれぞれの原型に変換しています。
・ストップワードの除去
→ストップワードとは、
多くの文章で使われるありふれた単語のことです。
これらは文章の分類にほとんど役立たないことが多いので今回は
除去します。
例としては、「is」「and」「like」など。
日本語の場合では、「です」「ます」「は」などです。
<データの前処理>
作成した関数で前処理を行います。
#全てのテキストに前処理
df["review"] = df["review"].apply(process_string)
#csv保存
df.to_csv("imdb_reviews_cleaned.csv")
df = pd.read_csv("imdb_reviews_cleaned.csv")
4.データの分割
今回は
①トレーニングセット (training set)
②バリデーションセット (validation set)
③テストセット (test set)
の3つに分割しました。
バリデーションセットは、ハイパーパラメータを調整するための、分類器のパフォーマンス測定に使います。
一方、テストセットは、学習後の分類器のパフォーマンスを確かめるためだけに使用します。
##データの分割
from sklearn.model_selection import train_test_split
review_train, review_test, labels_train, labels_test = train_test_split(df["review"], df["sentiment"], test_size=0.1, random_state=0)
review_train, review_valid, labels_train, labels_valid = train_test_split(review_train, labels_train, test_size=0.1111, random_state=0)
#pandasに変換
review_train_df = pd.DataFrame()
review_train_df["review"] = review_train
review_train_df["sentiment"] = labels_train
review_valid_df = pd.DataFrame()
review_valid_df["review"] = review_valid
review_valid_df["sentiment"] = labels_valid
review_test_df = pd.DataFrame()
review_test_df["review"] = review_test
review_test_df["sentiment"] = labels_test5.ベクトル化とラベル変換
<ベクトル化>
機械学習においては、文章や単語などのデータは事前に数値に変換しておく必要があります。
今回はBoWモデルを使用しました。
BoWモデルは、テキストを数値の特徴ベクトルとすることができます。
イメージとしては以下です。
・文章全体から、単語のようなトークンからなる語彙を作成。
・各文章の単語毎の出現回数を含んだ特徴ベクトルを構築。
基本的には一つ一つの文章が長く、かつたくさんの文章が存在すれば単語の生の出現度は低くなり、ベクトルのほとんどが0となるため、この特徴ベクトルは「疎ベクトル」とも呼ばれます。
つまりは、「どの単語が含まれているか」という点に注目しているのが、bag-of-wordsという考え方です
#ベクトル化
vectorizer = CountVectorizer()
feature_matrix_train = vectorizer.fit_transform(review_train_df["review"].tolist())
feature_matrix_valid = vectorizer.transform(review_valid_df["review"].tolist())
feature_matrix_test = vectorizer.transform(review_test_df["review"].tolist())<ラベル変換>
各レビューはpositive/negativeのラベルがつけられています。
これを機械学習モデルに使用できるようにするため、数値ラベルに変換します。
#ラベル変換
label_encoder = preprocessing.LabelEncoder()
label_matrix_train = label_encoder.fit_transform(review_train_df["sentiment"])
label_matrix_valid = label_encoder.fit_transform(review_valid_df["sentiment"])
label_matrix_test = label_encoder.fit_transform(review_test_df["sentiment"])
6.TF-IDFを使った単語の重み付け
TF-IDF は 単語の重要度 を測るための指標の1つで、TFとIDFの積です。
TF(Term Frequency): ある文書における 単語の出現頻度
IDF(Inverse Document Frequency): 逆文書頻度。
何をするのかざっくりと言うと、
「頻繁に出てくる単語 or 頻繁に出てこない単語 を、重要な単語だとする」
と言う処理です。
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_vectorizer = TfidfVectorizer()
feature_matrix_train = tfidf_vectorizer.fit_transform(review_train_df["review"].tolist())
feature_matrix_valid = tfidf_vectorizer.transform(review_valid_df["review"].tolist())
feature_matrix_test = tfidf_vectorizer.transform(review_test_df["review"].tolist())
dt_train_df = pd.DataFrame.sparse.from_spmatrix(data = feature_matrix_train, columns = vectorizer.get_feature_names())
dt_valid_df = pd.DataFrame.sparse.from_spmatrix(data = feature_matrix_valid, columns = vectorizer.get_feature_names())
dt_test_df = pd.DataFrame.sparse.from_spmatrix(data = feature_matrix_test, columns = vectorizer.get_feature_names())
7.機械学習モデルのトレーニングとテスト
今回は6種類のモデル(ナイーブベイズ、決定木、k近傍法、ロジスティック回帰、サポートベクターマシン、ランダムフォレスト)でトレーニングとテストを行っています。
<ナイーブベイズ>
#ナイーブベイズ
from sklearn.naive_bayes import BernoulliNB
model_nb = BernoulliNB()
model_nb.fit(feature_matrix_train, label_matrix_train)
y_pred_nb = model_nb.predict(feature_matrix_valid)
accuracy_train_set = model_nb.score(feature_matrix_train, label_matrix_train)
accuracy_valid_set = model_nb.score(feature_matrix_valid, label_matrix_valid)
print("Naive Bayes Model, Accuracy (Train Set) : ", accuracy_train_set)
print("Naive Bayes Model, Accuracy (Valid Set) : ", accuracy_valid_set)
##実行結果
Naive Bayes Model, Accuracy (Train Set) : 0.900475
Naive Bayes Model, Accuracy (Valid Set) : 0.8488<決定木>
#決定木
from sklearn.tree import DecisionTreeClassifier
maximum_tree_depth= 13
model_dt = DecisionTreeClassifier(max_depth=maximum_tree_depth)
model_dt.fit(feature_matrix_train,label_matrix_train)
y_pred_dt = model_nb.predict(feature_matrix_valid)
accuracy_train_set = model_dt.score(feature_matrix_train, label_matrix_train) #get accuracy on train set
accuracy_valid_set = model_dt.score(feature_matrix_valid, label_matrix_valid) #get accuracy on valid set
print("Descision Tree Model, Accuracy (Train Set) : ", accuracy_train_set)
print("Descision Tree Model, Accuracy (Valid Set) : ", accuracy_valid_set)
##実行結果
Descision Tree Model, Accuracy (Train Set) : 0.808775
Descision Tree Model, Accuracy (Valid Set) : 0.7416<k近傍法>
#k近傍法
from sklearn.neighbors import KNeighborsClassifier
number_of_neigbors = 3
minkowski_power = 2
model_knn = KNeighborsClassifier(n_neighbors=number_of_neigbors, p =minkowski_power)
model_knn.fit(feature_matrix_train, label_matrix_train)
y_pred_knn = model_nb.predict(feature_matrix_valid)
accuracy_train_set = model_knn.score(feature_matrix_train, label_matrix_train)
accuracy_valid_set = model_knn.score(feature_matrix_valid, label_matrix_valid)
print("K Nearest Neighbors Model, Accuracy (Train Set) : ", accuracy_train_set)
print("K Nearest Neighbors Model, Accuracy (Valid Set) : ", accuracy_valid_set)
##実行結果
K Nearest Neighbors Model, Accuracy (Train Set) : 0.884375
K Nearest Neighbors Model, Accuracy (Valid Set) : 0.778<ロジスティック回帰>
#ロジスティック回帰
from sklearn.linear_model import LogisticRegression
l2_norm = 0.4
l2_norm_inverse = 1/l2_norm
maximum_iterations=4000
model_lr = LogisticRegression(C=l2_norm_inverse,max_iter=maximum_iterations)
model_lr.fit(feature_matrix_train, label_matrix_train)
y_pred_lr = model_nb.predict(feature_matrix_valid)
accuracy_train_set = model_lr.score(feature_matrix_train, label_matrix_train)
accuracy_valid_set = model_lr.score(feature_matrix_valid, label_matrix_valid)
print("Logistic Regression Model, Accuracy (Train Set) : ", accuracy_train_set)
print("Logistic Regression Model, Accuracy (Valid Set) : ", accuracy_valid_set)
##実行結果
Logistic Regression Model, Accuracy (Train Set) : 0.948275
Logistic Regression Model, Accuracy (Valid Set) : 0.8926<サポートベクターマシン>
#サポートベクターマシン
from sklearn.svm import LinearSVC
l2_norm = 2.1
l2_norm_inverse = 1/l2_norm
maximum_iterations=4000
model_svm = LinearSVC(C=l2_norm_inverse,max_iter=maximum_iterations)
model_svm.fit(feature_matrix_train, label_matrix_train)
y_pred_svm = model_nb.predict(feature_matrix_valid)
accuracy_train_set = model_svm.score(feature_matrix_train, label_matrix_train)
accuracy_valid_set = model_svm.score(feature_matrix_valid, label_matrix_valid)
print("Support Vector Machine Model, Accuracy (Train Set) : ", accuracy_train_set)
print("Support Vector Machine Model, Accuracy (Valid Set) : ", accuracy_valid_set)
##実行結果
Support Vector Machine Model, Accuracy (Train Set) : 0.9675
Support Vector Machine Model, Accuracy (Valid Set) : 0.8952<ランダムフォレスト>
#ランダムフォレスト
from sklearn.ensemble import RandomForestClassifier
estimators = 100
forest_depth = 25
model_rf = RandomForestClassifier(n_estimators=estimators,
max_depth = forest_depth)
model_rf.fit(feature_matrix_train, label_matrix_train)
y_pred_stacked = model_rf.predict(feature_matrix_valid)
accuracy_train_set = model_rf.score(feature_matrix_train, label_matrix_train)
accuracy_valid_set = model_rf.score(feature_matrix_valid, label_matrix_valid)
print("Random Forests ML Model, Accuracy (Train Set) : ", accuracy_train_set)
print("Random Forests ML Model, Accuracy (Valid Set) : ", accuracy_valid_set)
##実行結果
Random Forests ML Model, Accuracy (Train Set) : 0.93935
Random Forests ML Model, Accuracy (Valid Set) : 0.84048.結果のまとめと考察
<グラフ化>
モデル毎のリストを作成しています。
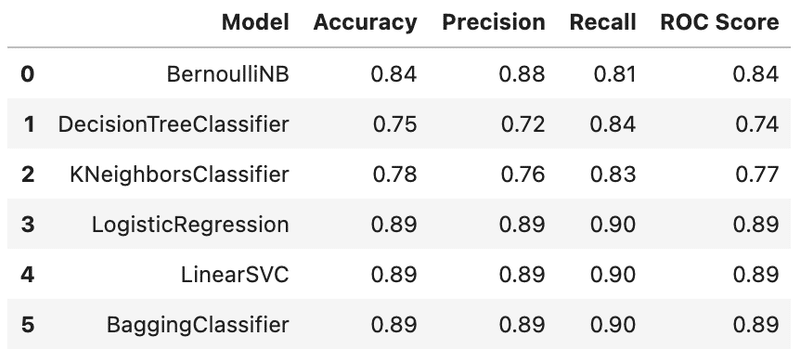
正解率 (Accuracy)・適合率(Precision)・再現率(Recall)・ROCスコアをモデル毎に算出し、表にしています。
グラフは(横軸:偽陽性率、縦軸:真陽性率)としています。
from sklearn.model_selection import train_test_split #split data into train,test sets
from sklearn.metrics import plot_confusion_matrix, plot_roc_curve, plot_precision_recall_curve
from sklearn.metrics import precision_score, recall_score
from matplotlib import pyplot as plt
#モデル毎のリストを作成
ml_models_list = [model_nb, #ナイーブベイズ
model_dt, #決定木
model_knn, #K近傍法
model_lr, #ロジスティック回帰
model_svm, #サポートベクターマシン
model_bc, #ランダムフォレスト
]
models = []
accuracies = []
precisions = []
recalls = []
roc_scores = []
from sklearn.metrics import roc_auc_score
for model in ml_models_list:
accuracy = model.score(feature_matrix_test, label_matrix_test)
y_pred = model.predict(feature_matrix_test)
model_name = type(model).__name__
models.append(model_name)
accuracies.append(accuracy.round(4))
precisions.append(precision_score(label_matrix_test,y_pred).round(4))
recalls.append(recall_score(label_matrix_test,y_pred).round(4))
roc_scores.append(roc_auc_score(label_matrix_test,y_pred).round(4))
fig, axes = plt.subplots(nrows=3, ncols=2, figsize=(17,30))
for model, ax in zip(ml_models_list,axes.flatten()):
plot_roc_curve(model,feature_matrix_test,label_matrix_test,ax=ax)
ax.title.set_text(type(model).__name__)
plt.tight_layout()
plt.show()
results = pd.DataFrame({"Model" : models, "Accuracy" : accuracies, "Precision" : precisions, "Recall" : recalls, 'ROC Score' :roc_scores})
results
<実行結果>
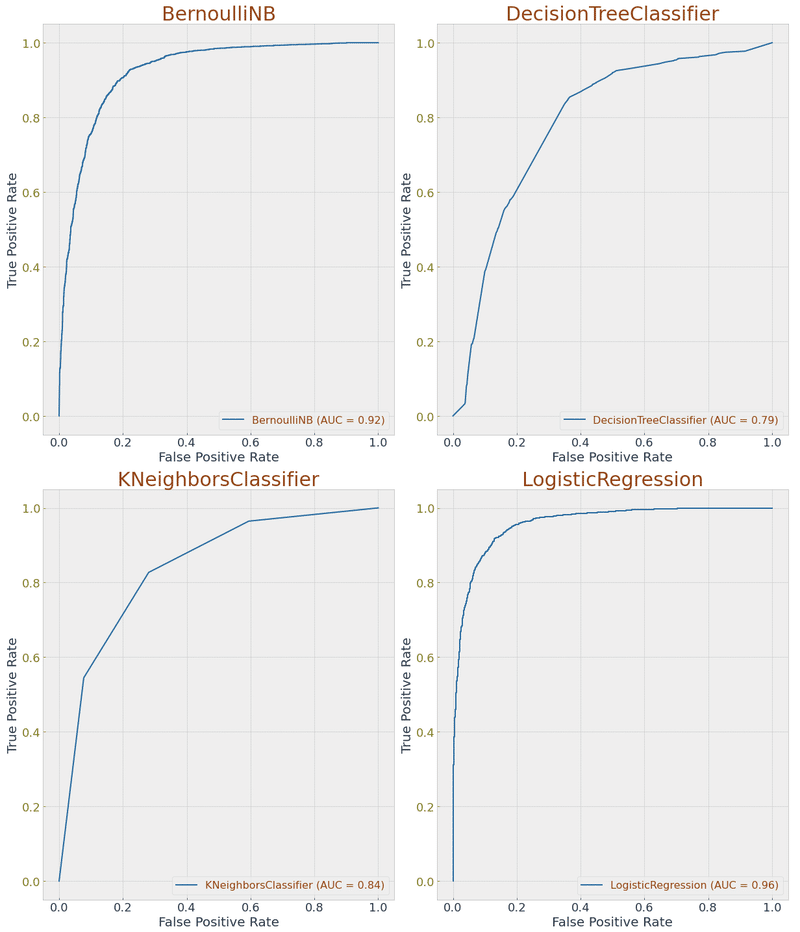
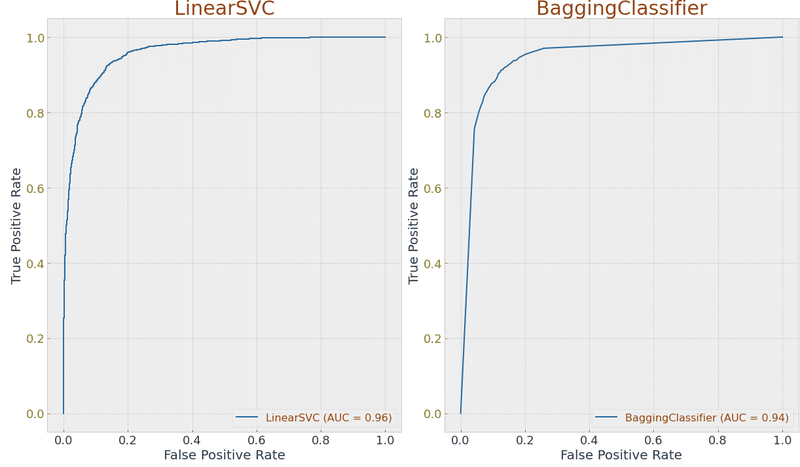
<考察>
良いモデルとは「偽陽性率が低い時点で既に真陽性率が高い数値がでること」であるというのが私の認識です。
それを踏まえて今回のROC曲線のグラフを見ていくと、ロジスティック回帰、サポートベクターマシンのモデルはなかなかに良好な結果が得られているのではないかと考えています。
バリデーションデータでも9割近い正解率となっていますので、その点は一致しているかと。
このモデルをよりよくするにはどうするかというのは、今の私では確信を持って言えることはないのですが、気になっている点をいくつか挙げます。
・レビュー内の顔文字の影響
→顔文字が使われているレビューもありそうです。
感情表現には顔文字は重要な情報だと思います。
・希少語の影響
→ごくわずかしか使用されない語(希少語)については、
除いてもよかったのかなーと思います。
・word2vecを使用した際にどうなるか
この辺りはAidemyのコースが修了した後に、じっくり腰を据えて取り組みたいですね。
私事ですが業務内容が変わってなかなか時間が取れないもので・・・・
おわりに
最後に忌憚ない意見と感想を述べたいと思います。
良かった点
・機械学習に必要な基礎知識が体系立ってまとめられている点。
悪かった点
・学習サポートの使いにくさ。
(私の場合は)学習サポートをほぼ使用しなかった。受講料にはその費用も含まれているので、そこはもったいなかったかなと。
オンラインで予約を取ってカウンセリングや質問ができるのだが、不明な所については自分で調べた方が早い。
あとはオンラインでも初対面の人と話をするのは疲れる。仕事から疲れて帰ってきて、わざわざオンラインの学習サポートを受けようと思わない。
カウンセリング側も慣れていない感じがあり、なんだかなぁ・・・という感想。
良いエンジニアが良い教師だとは限らないので、しょうがない所はある。
人に物を教えるのは難しいですよね。
・「発展的な内容なので、詳しく知りたい人はリンク先を見てくれ!」というのが多すぎる
こういうものは後からじっくり見るので、ブックマークがかなり増える。
仕方ない面もあるのだろうが、説明丸投げの箇所もあって違和感を感じた。
・動画での講義。
「他のようにテキストでまとめれば良くね?」と感じた。あの動画の講義は必要なんだろうか。
結局スライドの内容を話しているだけだから、顔出しする必要は全くない。なぜわざわざ動画にするのか理解に苦しむ。
人が動いていて邪魔な時もある。
こちらが求めているのは分かりやすい教材であって、動画にした方が分かりやすいなら動画にすべきだと思うが・・・・
最後に一つ。
この先、社会はどのように変わっていくかは誰にも分かりませんが、プログラミング的思考を学ぶことは決して損にはならない。
というのが学習全体を通した感想です。
もちろん自分の本業・副業に活かして、社会に貢献できるのが一番ですけどね。
以上、ここまでお読みいただきありがとうございました。
この記事が気に入ったらサポートをしてみませんか?