
「空気を読む」地点検索(1:地点検索システムとウェブ検索システムの違い)

こんにちは、サファイアです。ナビタイムジャパンで全文検索エンジンの研究開発を担当しています。
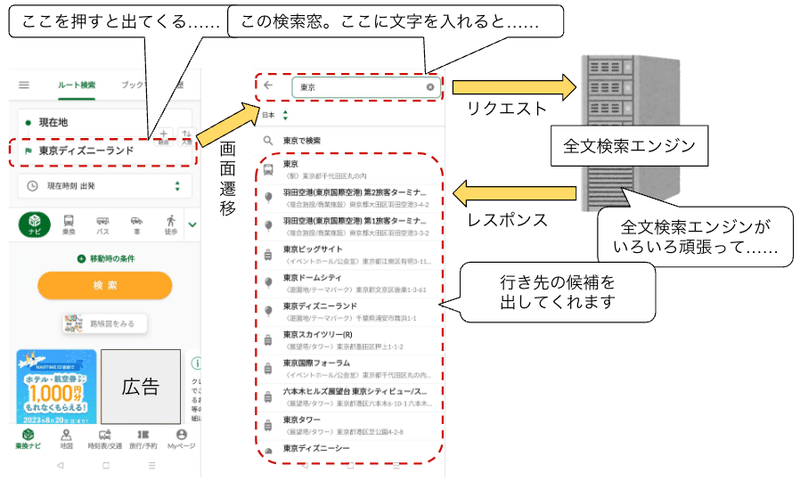
みなさんは『NAVITIME』のアプリなどを開いた際に、アプリの検索窓に現在地や目的地などをテキスト入力しますよね。そして、そうしたテキスト入力をしたら、みなさん当然、「ちゃんと自分が意図した地点がアプリにどこのことを指しているのか伝わること」を期待すると思います。
この「ユーザーから現在地や目的地などを示すテキスト入力を受け取った際に、無数の地点の中から、ユーザーがどの地点のことを指しているのかを当てに行く」という「地点検索システム」を、ナビタイムジャパンでは「全文検索エンジン」を用いて実現しています。
今回のお話と対象読者
さて、この「アプリの検索窓にテキストを入力すると、無数の候補の中から検索エンジンがユーザーにピッタリのものを返してくれる」というシステムには、地点検索システム以外にも様々なものがあります。
その中でも代表的だと言えるのが、おそらくウェブ検索システムでしょう。ご存知の通り、様々なポータルサイトのトップページ上にある検索窓にテキストを入力して検索ボタンを押すと、各サイトが収集した無数のウェブページの中から、ユーザーが求めているであろうと予測されたウェブページのリストがユーザーに返却されます。これを実現しているシステムを、ここではウェブ検索システムと呼ぶことにします。
今回は「ナビタイムジャパンが提供する地点検索システム」がどのようなものであるのかについて、一般的なウェブ検索システムと比較する形でご紹介できればと思います。
なお、今回のお話を踏まえて、次回はユーザーが使っていて快適に感じられるような「空気を読む」地点検索システムを作るために、ナビタイムジャパンがどのような施策を打ってきたのかについて触れる予定です。
検索対象の違い
一般的なウェブ検索システムと地点検索システムで、まず異なってくるのは「検索対象」でしょう。ウェブ検索システムでは検索対象がウェブページであるのに対して、地点検索システムでは地点に関する情報(=「地点情報」)が検索対象となっています。
この検索対象の違いが、ウェブ検索システムと地点検索システムの間にある他の様々な違いの元となります。
データ量の違い
ウェブページと地点情報との間には、様々な違いがあります。まず異なるのが、扱うデータの量です。あらゆる人々が情報を手軽にインターネット上に発信できるようになり、その発信手段もテキスト主体のものから画像や動画主体のものへと変わってきました。
それに伴って、ウェブページ全体のデータ量も極めて膨大なものとなっています。例えば、Googleによれば、Googleが扱うウェブページの数は数千億にもなり、それらのページを扱うために作ったインデックスのデータサイズは十億ギガバイトを優に超えるとのことです。
Google 検索インデックスには数千億のページが含まれ、そのサイズは 100,000,000 ギガバイトを優に超えます。Google のインデックスには、本の巻末にある索引と同じように、各ウェブページに含まれているすべての語が 1 つずつ追加されています。つまり、インデックスにウェブページが登録されると、そのページに含まれるすべての語がインデックスに追加されるということです。
一方で、地点検索においては、例えばナビタイムジャパンが扱っているデータでいえば、数百ギガバイト程度のサイズでおさまります。この差は何に由来するのでしょうか?
検索システムに対するユーザーの期待の違い
この問いに答えるためには、地点検索システムに対するユーザーの期待とウェブ検索システムに対するユーザーの期待との違いを理解する必要があります。
まず、ウェブページに対する期待としては、ひとまずは「インターネット上のウェブページとして、どのような情報が発信されているかを知りたい」というものがあるでしょう。この期待に答えるためには、最新のウェブページに関する情報を取得するのが良さそうです。実際、先のページで、Googleは下記のように述べています。
ウェブやその他のコンテンツは絶えず変化しているため、クロール処理は常時実行されて最新情報を維持しています。過去に見たコンテンツが変更されそうな頻度を学習し、必要に応じて再度アクセスします。また、そのページまたは情報へのリンクが新たに出現したときには、新しいコンテンツも検出します。
これは、ウェブページに関する情報を取得するための手法として、真っ当なものであるように思えます。
一方で、ナビタイムジャパンが提供する地点検索についていえば、ユーザーの期待はこれとは少し異なってきます。
というのも、ナビタイムジャパンでは「ユーザーは地点検索を行った後で、実際に目的地に向かって移動する」ということが前提とされているためです。もし、ここで目的地として地点検索システムが提示した情報が現実の状況から乖離していたとすれば、どうでしょうか。例えば、目的地として出てきた「Aホテル」という場所に向かって移動したとして、いざ現地に着いてみれば「Aホテル」などという場所はなかった……などの事態が起きてしまうとどうなるのか、ということです。これは大惨事です。このような事態はできる限り避けたいものです。
データソースの違い
そのために、ナビタイムジャパンでは他社から地点に関するデータを購入したり、独自に地点に関する情報を収集・精査することなどを通じて、地点情報を整備しています。
つまり、一般的にウェブ検索システムでは「ウェブページそのもの」がデータソースとなるのに対し、ナビタイムジャパンが提供している地点検索システムでは、「地点そのもの」をデータソースとすることはできない以上、「実在することが確からしいと判断された地点に関する情報」をデータソースとしているのです。
まとめ
まとめると、ウェブ検索システムと地点検索システムでは、下記のような違いがあるのでした。
検索対象の違い:
ウェブページ/地点に関する情報データ量の違い:
ウェブ検索システムの方が地点検索システムよりも扱うデータ量が多くなる傾向が示唆されたユーザーの期待の違い:
期待した情報が載っていること/その地点に行けることデータソースの違い:
ウェブページそのもの/実在することが確からしいと判断された地点に関する情報
次回は、今回お話ししたことを前提として、「空気を読む」地点検索システムを作るために、私たちが打ってきた施策についてお話ししていく予定です。