データサイエンスを体感する - 01.クラスター分析

こんにちは、もうすぐ春ですね。毎年桜が咲くと、目黒川近辺を深夜にうろついて怪しまれて職質されそうになる、データアナリスト/データサイエンティストMARUです。(目黒川のお花見は中目黒より池尻大橋がすいてていいですよ!)
さて「データサイエンスを体感する」と題した、データ分析未経験/初心者の皆さま向けの体験企画の第1弾は「クラスター分析」です。なぜ第1弾がクラスター分析かといえば、割とわかりやすくウケがいいからですね。新卒研修などにもってこい。
※事前に「00.Colaboratoryでのコード実行:初心者向けガイド」を目を通して準備してくださいね。
クラスター分析とは
クラスター分析は顧客セグメンテーションや行動パターンの理解に役立ちます。類似した特性や行動を持つ顧客グループを特定し、それぞれに適したマーケティング戦略を展開することが可能です。
デジタルマーケティングにおいて one to one マーケティングは理想ですが、実際には一人ひとりに合わせたコミュニケーションを取るのは難しいですよね。そんな時、クラスター分析を使って似た特徴の人たちをグループ分けし、グループごとに発信内容をカスタマイズする方法があります。これにより、効率的なメルマガやアプリ配信などが可能になります。
ここでは「マーケティングオートメーションで顧客の住所データを分析して顧客セグメントを作り、メールコンテンツを出し分けする」シチュエーションであると仮定しましょうか。各コード(黒い部分)を Google Colaboratory の「コード」にコピー&ペーストで順番に実行すれば結果が出るようになっています。
0. 必要なライブラリのインポート
データサイエンスや機械学習のプロジェクトを始める際には、まず必要なツール(ライブラリ)を準備します。Pythonでは、これらのライブラリを「インポート」という方法でプログラムに取り込みます。今回使用するライブラリは以下の通りです:
`matplotlib.pyplot`:グラフやチャートを描画するためのライブラリです。データの可視化に役立ちます。
`pandas`:データを扱いやすくするためのライブラリで、表形式のデータ操作を簡単にします。
`sklearn.datasets`の`make_blobs`:テスト用のデータセットを生成するために使用します。
`sklearn.cluster`の`KMeans`:K-meansクラスタリングを実行するためのライブラリです。
# ライブラリのインポート
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import pandas as pd1. テストデータの生成
クラスタリングの概念を学ぶために、まずは実験用のデータセットを用意します。`make_blobs`関数を使って、2次元空間に分布するデータポイントの集まりを生成します。このデータは、例えば顧客の住所の位置情報を模したものだと考えることができます。
# テストデータの生成
X, _ = make_blobs(n_samples=200, centers=4, cluster_std=1.5, random_state=42)2. データの確認
生成したデータを理解するために、データの内容を確認しましょう。`pandas`のデータフレームを使って、データの最初の数行を表示します。これにより、データの形式や分布の概要を把握できます。
# データの確認
df = pd.DataFrame(X, columns=['X Coordinate', 'Y Coordinate'])
print("生成されたテストデータの先頭5行:")
print(df.head())下記のような結果が返ってきます。今回はこのデータは各顧客の住所についてX座標とY座標が登録されているデータである、と仮定してくださいね。

3. K-meansクラスタリングの適用
生成したテストデータに対して、K-meansクラスタリングを適用します。K-meansは、データを予め定義されたクラスタ数に分けるアルゴリズムです。ここでは、4つのクラスターに分けてみましょう。
# K-meansクラスタリングの適用
kmeans = KMeans(n_clusters=4, random_state=42)
kmeans.fit(X)
labels = kmeans.predict(X)4. クラスタリング結果の可視化
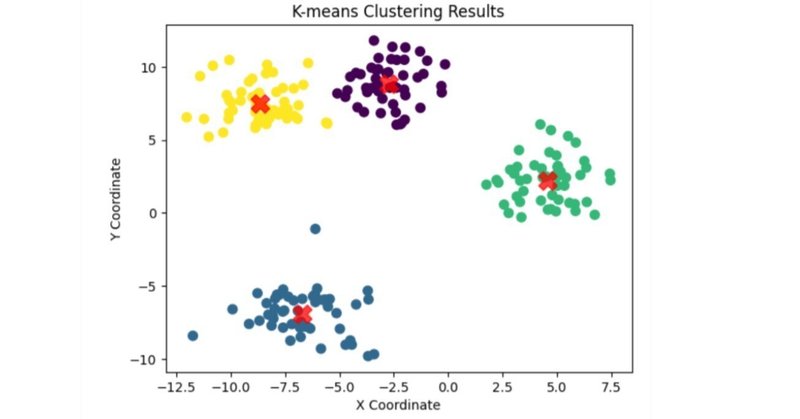
最後に、クラスタリングの結果を可視化してみましょう。異なるクラスターを異なる色で表示し、クラスターの中心を赤いマークで示します。これにより、どのようにデータがグループ化されたかを直感的に理解することができます。
# クラスタリング結果の可視化
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis', s=50)
centers = kmeans.cluster_centers_
plt.scatter(centers[:, 0], centers[:, 1], c='red', marker='X', s=200, alpha=0.75)
plt.title('K-means Clustering Results')
plt.xlabel('X Coordinate')
plt.ylabel('Y Coordinate')
plt.show()
下記のような散布図が描画されると思います。4つのかたまり(クラスター)それぞれが「似ているグループ」になります。1つ1つの点が各顧客にあたります。ここでは「顧客が住所の近さの観点で4つにグループ分けされている」のですが、実際の分析現場では、どういうグループ分けがされているのかは分析者が各クラスターの特徴を確認しながら解釈を行います(※今回ここの詳細は省略)
例えば「渋谷付近の顧客」「新宿付近の顧客」「池袋付近の顧客」「銀座付近の顧客」に分かれているのだな、というように。であれば、各エリアごとのカラーを出したメルマガを企画して出し分けしよう・・など、実際の施策に活用するわけです。

上記は4つのクラスターに分かれていますが、先の「3. K-meansクラスタリングの適用」で n_clusters=3 にすれば3つのクラスターに、n_clusters=5 にすれば5つのクラスターに分けることができます。試してみてください。いくつのクラスターに分けることが適切かは、マーケティング担当者など他チームと会話しながら、最終的には分析担当がリードして決定することが多いですね。
説明の簡単のために少し極端かつ簡易的な例ですが、クラスター分析がどういうものか体感いただければ幸いです。それではまた!
この記事が気に入ったらサポートをしてみませんか?