ひょうたん島~ニューラルネットワークによる非線形な応答局面の簡単な例

1.はじめに
私たちの周りには、何らかの関係がありそうだがその関係が一言では言い表せない事柄が多く存在しています。例えば、
・中古住宅の評価額
(住宅の築年数、広さ、日当たり、駅からの距離、周辺の環境、区画整理の進み具合)
・ローン返済の可能性
(年齢、年収、家族構成、健康状態、職種、過去のカード使用履歴)
・スポーツジムの解約率
(性別、年齢、年収、過去一年間の利用頻度、平日中心か休日中心か、体力測定結果、体脂肪率)
などです。直感的に関係がありそうだな、という項目が並んでいます。
ただし、どのくらいの強さで影響するのかどうかや、トレードオフとなる項目、例えば年齢と年収などの項目が増えていくと人間の頭だけで理解するには限界があります。(長年の経験でピタッと言い当てる職人ワザをお持ちの人もいるとは思いますが。)
ここで紹介するニューラルネットワークという分析手法は、そのような複雑な問題を解決することを得意としています。「ノウハウを学習し、職人ワザに磨きをかける」という何とも人間に近いことを行います。
今回は、ニューラルネットワークの入門として簡単で分かり易い例をご紹介します。ニューラルネットワークはどのようなものなのか?を感覚で理解できることを目的に進んでいきましょう。
2.分析に入る前に、データを確認しておきましょう。
表1.がニューラルネットワークでの分析に利用するデータです。

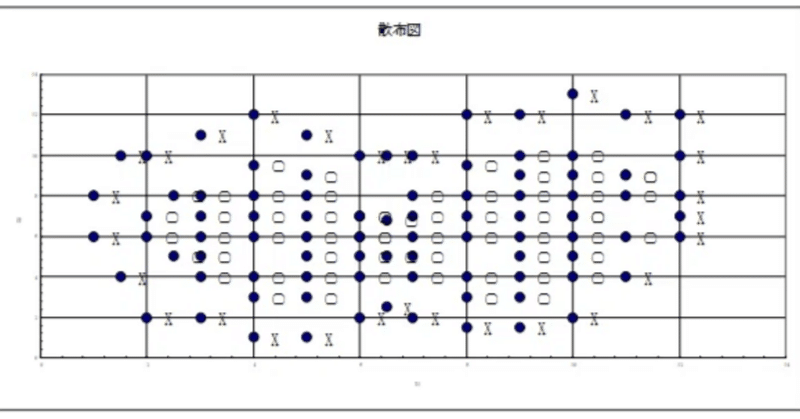
これをラベル付き散布図で表したものが図1です。
いかがでしょうか?これを「ひょうたん島データ」と呼んでいる意味がお分かりになりましたか?データ数は92個あります。
Groupは属している領域を示しています。図1.1を「ひょうたん島」に例えると、陸地にGroup○が、それ以外の外周(海)にGroup×が属しています。
X1,X2は結果に影響を与えるデータで、「要因データ」です。(対してGroupのデータは「実測値データ」です。)仮に新しいX1,X2のデータが追加された場合でも、どちらに属することが分かれば、結果(予測値データ)を得ることが可能となるのです。
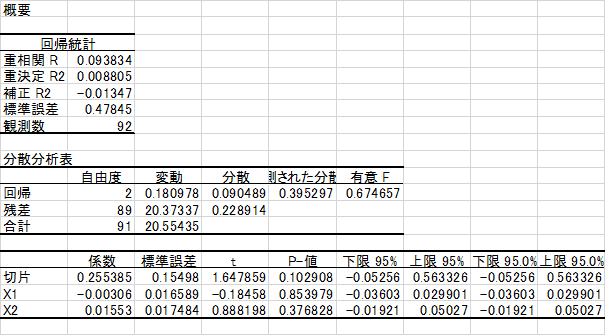
さて、このデータの特徴は非線形データであることです。非線形データとは、散布図を描いたときに、まっすぐな直線状にならないデータのことをいいます。回帰分析の場合、線形データの時に威力を発揮しますので、ひょうたん島データのような非線形データの場合、精度が悪くなります。(回帰分析の解説は省略しますが、興味のある方は、精度の良さを表す「重相関係数(重相関R)」をご確認下さい。Excelでメニュー「ツール」-「分析ツール」-「回帰分析」を選択します。入力Y範囲にGroupのデータ部分(○を0、×を1にデータ変換が必要)、入力範囲にX1,X2のデータ部分を指定して分析結果を確認してみて下さい。重相関Rの値が1に近いほど、精度が良いと言えるのですが、非常に低いことが分かります。表1.2が回帰分析結果となります。)
早速、『ニューラルワークス Predict』を利用して、ニューラルネットワークで分析をしてみましょう。
3.ニューラルワークス Predictを利用してニューラルネットワークモデルを作成する
ニューラルワークス PredictはExcelのアドオンソフトです。インストールが済みましたら、ひょうたん島データが入っているExcelファイルを通常と同じように起動して下さい。
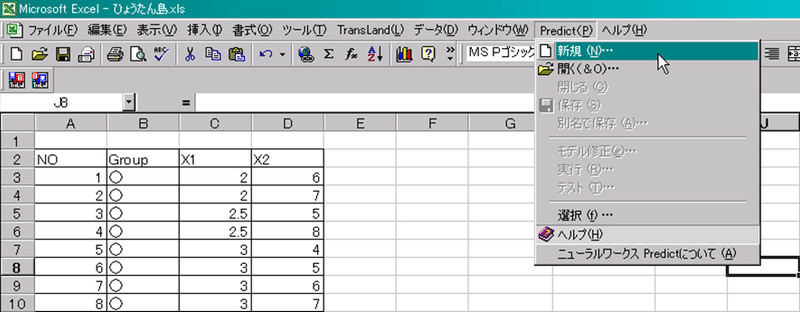
インストールが成功していれば、メニュー「Predict」が追加されているはずです。手順にそって操作を始めましょう。
まず、モデルの新規作成を行います。メニュー・「Predict」-「新規」を選択します。
次にダイアログが表示されます。このダイアログを使用して分析データについてのすべての設定を行います。

「モデルのタイプ」で分析手法を選択します。ここは「データを分類する」を選択して下さい。 今回のひょうたん島データは「陸地 or 海」=「○ or ×」の判別になります。「分類をする」という意味で「データを分類する」が適切である、というのが理由です。
次へボタンのクリック以降、ダイアログに従って、以下どの項目にどのデータを設定すればいいのかを見ていきます。
■「モデル名」を入力する
■「モデル・タイプ」は「図3-1 新しいモデルの指定」で指定されたタイプが表示される
■「モデル名をワークシートに適用」をチェックするとエクセルのワークシート名がモデル名になります。
■「モデル名をワークブックに適用」をチェックするとエクセルのブック名がモデル名になります。
■「フィールド名」をコメントの通り指定する(ここではワークシートの見出しとなる$B$1を指定する)。
■「最初の入力データ」に一番目の入力データ範囲を入力します。(直接セル範囲を入力してもドラッグで範囲指定をしても可能です。通常のExcelと全く同じ操作になります。)ここでは、要因データ「2,6」(C3:D3)を指定することになります。
■「最初の入力データ」に二番目の入力データ範囲を入力します。上記で入力したすぐ下にある「2,7」(C4:D4)が対象です。
■「入力データの範囲」にすべての入力データ範囲を入力します。要因データX1,X2のすべてのデータ範囲(C3:D94)が対象です。
■「最初の目的変数」に一番目の出力データ範囲を入力します。実測値データである「○」(B3)が対象です。
■「雑音のレベル」で雑音のレベルを選択します。ここではデフォルトの「一般的な雑音データ」を選びます(株式市場問題などでは「ひどい雑音データ」、数式から作成されたデータでは「クリーンなデータ」を選びます)。
■「データの変換レベル」でデフォルトの「一般的なデータ変換」を選択します。
「変数選択のレベル」を指定します。ここではデフォルトの「包括的な変数選択」を選択します。
■「最適化のレベル」を指定します。ここではデフォルトの「包括的なネットワーク検索」を選択します。

ここまでで、必要な分析データの範囲設定が完了しました。もし、この後の実行時や結果出力の際に「おかしいぞ?」ということが出てきたら、もう一度この部分の設定に立ち返って確認してみてください。
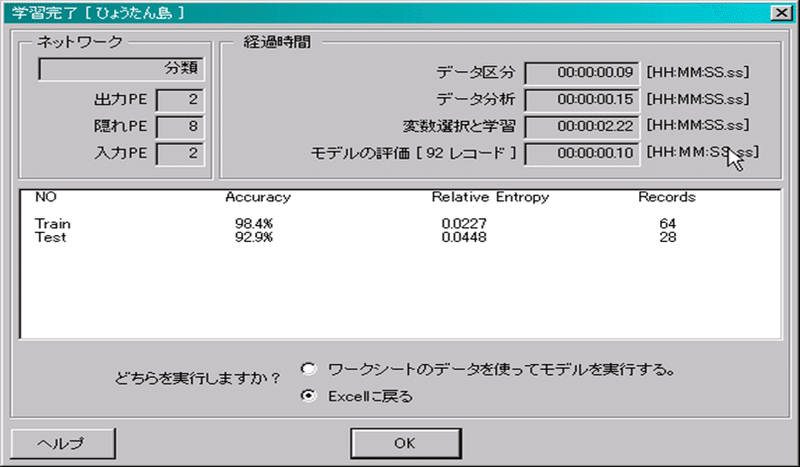
分析データの設定、分析手法を選択したところで、モデル作成を行ってみます。ボタン「学習」を押下してください。結果ダイアログが表示されます。
4. 作成したモデルを使って予測する
実測値と作成したモデルからの予測値、違いはどのくらいあるでしょうか?
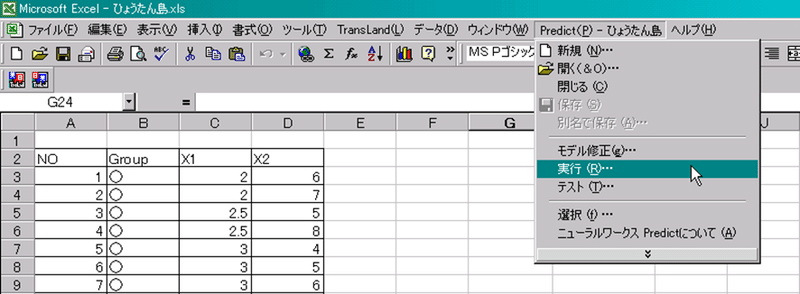
「Predict」メニュー-「実行」を選択します。
「モデルを実行」ダイアログの設定を行います。

■「入力データの範囲」を入力します。ここではすべてのデータ(C3:D94)に関して予測値を出してみましょう。
■「モデル出力の範囲」には予測値の出力開始セルを入力します。今回は(E3)を入力します。入力後、「実行」ボタンをクリックして下さい。

予測値が表示されましたか?結果を確認しましょう。NO.15は実測値と異なる結果になっていますね。このまま目視だけで確認していくと時間がかかりますし、何より正確さに欠けます。ニューラルワークス Predictのテスト機能を利用して結果を分かりやすく集計してみましょう。
5. テスト結果の出力
作成したモデルでテストを行い、結果を出力してみます。
「Predict」メニュー-「テスト」を選択するとダイアログが表示されます。
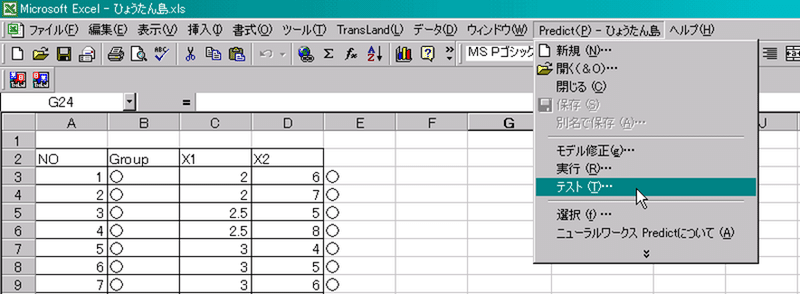

■「結果の出力位置(ここでは$F$2)」を指定する。
■「入力データの範囲」、「学習セット」、「テスト・セット」を選択します。すべての入力データを利用してテストを行い、全体の70%のデータでTrainingし、残り30%のデータでテストを行います。
6. テスト結果の確認
テスト結果が図1.12です。「All」の行を確認してみましょう。「Accuracy:0.9782609、Relative Entropy:0.01429072、Total:92」です。正判別率が0.9782609( = 約98%)、あてはまりの悪さが0.01429072、使用データ数が92です。Relative Entropyの示す「あてはまりの悪さ」は、0に近づくほど入力データに関してそのモデルである度合いが高い、という意味になります。
「Train」で「Accuracy:1」になっています。データ数が64と少ないとは言え、正判別率が100%になっています。「テスト」の内容も傾向はほぼ同じになっています。

7. 新しいデータが追加されたら?~散布図で確認~
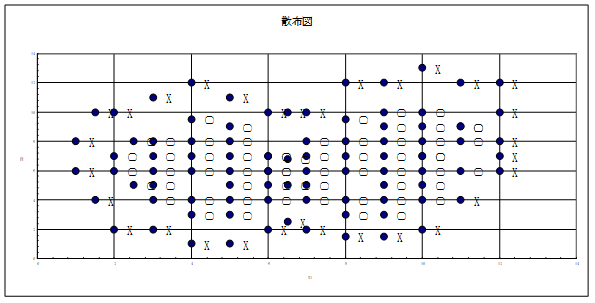
ここまで既存のデータ(実測値)との比較を行ってきました。今のところ精度は良いと言えます。ここでは既存の92個のデータに新しいデータが追加された場合を考えてみます。
新しいデータの追加
93個目のデータ:X1=20,X2=15、
94個目のデータ:X1=6,X2=4.5
理解しやすくするために散布図に追加します。(図12)

散布図に描くことは非常に有効な手段です。一目瞭然です。
93個目の追加データは、ひょうたん島の外側ですのでGroupは×が予測値となります。
94個目の追加データは、ひょうたん島の内側ですのでGroupは○が予測値となります。
8. 新規データの追加を反映させる~NeuralWorks Predictで確認~
では、NeuralWorks Predictを使って予測値を出してみましょう。92個のデータに2個の追加データを加えます。

「Predict」メニュー-「実行」を選択します。
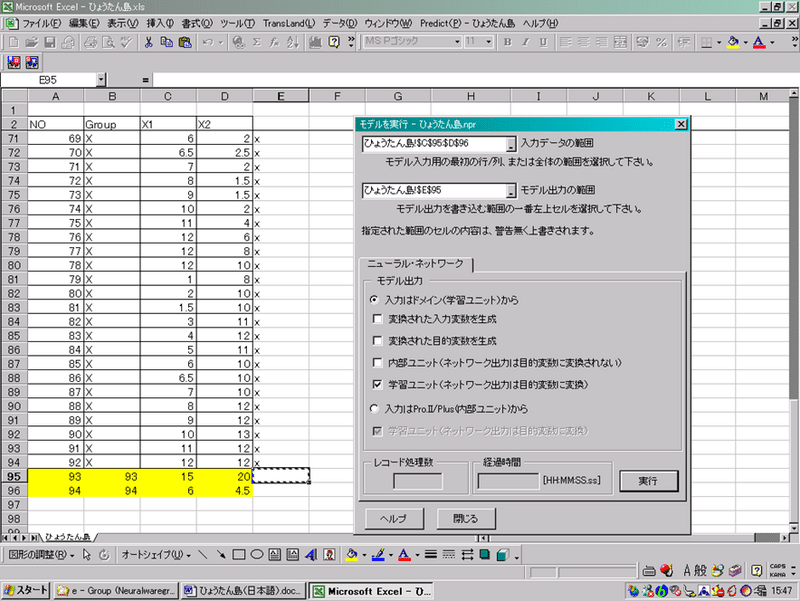
■「入力データの範囲」にすべての入力データ範囲(C3:D96)を入力します。既存データの予測値算出ではC3:D94でしたので、追加データ分まで範囲を広げたことになります。
■「モデル出力の範囲」には予測値の出力開始セルを入力します。今回は前回と同様(E3)を入力します。設定後、「実行」ボタンを押下して下さい。
新しいデータに対しての予測値が表示されましたか?結果を確認しましょう。散布図で確認した通りの予測値になっていますね。期待通りの結果が得られました。

今回は前述で作成したモデルで予測が可能でした。
しかし、現実の世界では要因が変化し続け、別の要因が追加されることもあります。『ニューラルワークス Predict』ではフレキシブルに対応し、新しいモデルを作成することが可能になっています。
『ニューラルワークス Predict』はニューラルネットワークの分析手法を手軽に取り入れ、様々な場面で汎用的に利用できるツールであると言えるでしょう。
弊社では、データ分析プロジェクトにまつわる様々なご相談に、過去20年以上に渡るプロジェクト経験に基づき、ご支援しています。
社内セミナーの企画等、お気軽にご相談いただければ幸いです。
この記事が気に入ったらサポートをしてみませんか?