ニューラルネットワークモデルの汎化性 vs 過学習

データには極端な値があるのと同様に、データモデリングの仕事も極端です。 ‘クリーン’な問題と’非常に雑音のある’問題があります(以下に説明します)。
何百万ものレコードのデータセットもあれば、50レコードのものもあります。
5個のデータフィールドのものもあれば、500個のものもあります。
ターゲットが1つのものも、20のものもあります。
そしてデータフィールドが歪んだ分布のものや一様分布のものあります。
理想的なアプリケーションとは、それがもし仮に存在するとして、それは’クリーンな’データで数フィールド、1出力、数千のデータレコードで可能なデータ範囲を対称的に分布しているものでしょう。
しかし、いったい誰がそのような簡単な仕事をしたことを覚えているでしょうか?
●クリーンな問題:すべての入力ケースがあって、測定誤差がない数学の関数のモデル
●雑音の多い問題:予測に有効かどうか分からない入力値と雑音の多いS&P500の終値のモデル
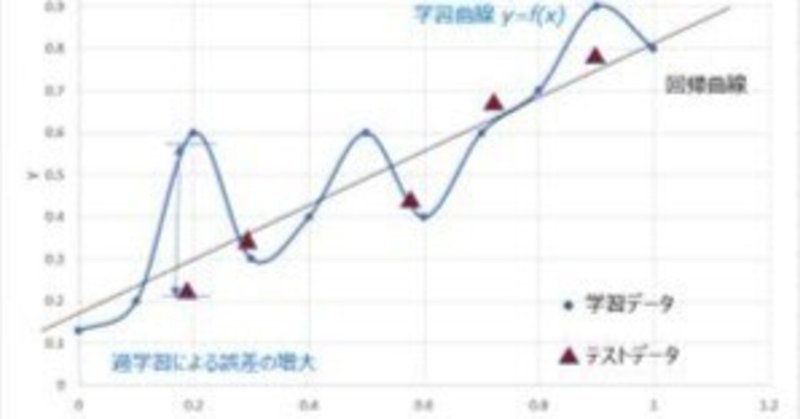
上記性質が、時間、努力、そして解析の結果に影響を与えます。モデリングの困難さは、モデルの新しいデータへの汎化性能と関係があります。
いくつかのアプリケーションでは汎化が容易です。モデルの学習に関して2つの互いに排他的なテーマがあります。
一つは、モデルはデータを可能な限りよく学習することが必要であり、可能性のあるもっとも高い性能測度(R相関のような)が望まれます。
他方、過度の学習はモデルの汎化性という点では有害です。
モデルがデータ中の汎用的なパターンの学習から離れ、学習データ中にのみ存在する特別な関係を記憶し始めるやいなや、そのモデルは良いものから悪いものへ変わっていきます。
したがって、良い汎化を行うためにはモデルの学習能力の制限が必要です。
もし学習を制限しすぎてしまったらどうなるでしょうか?
また、それを知る方法はあるのでしょうか?
ひとつの方法は、モデル構築プロジェクトの初めでは、モデルの汎化性についての問題は全て忘れて、意識的にモデルを過学習させることです! 最大の性能を見るため、利用できる全てのデータを使いましょう。
これは、技術に明るくない人は意識せずに行なってしまいますが、分かった上で行うのはメリットがあります。
それらのモデルからの性能指標は上限の性能値を与えることになり、汎化性の観点からは、開発中にその値には到達することはできないことがわかります。
以上の議論のポイントは、汎化性のもとでモデルの学習能力の限界に関心が移る前に、モデル学習に関する極限を最初に知ることが重要であるということです。
そうでなければ、性能を低く制限しすぎてしまうかもしれません。
これは、ニューラルワークス Predictではその優れた機能を未使用にすることで実現できます。
「すべて悪く」それらの設定を使用するには、
●クリーンデータ(ノイズ設定)
●包括的なデータ変換
●変数選択なし
●徹底的なネットワーク検索
●詳細パラメータボタン、データセットタブ
○学習セット=すべて2次セットから
○テストセット=すべて2次セットから
○OK
●そしてモデルを学習!
Professional II/PLUSユーザも、同一の学習とテストセットを使用し、隠れ層ノードを十分多く使用し、Run/SaveBest の代わりにRun/Learnを使用して、数百万レコードを学習させることで、この「良くない手段」を行うことができます。
たとえば、過学習でR=0.9であることが分かった場合でも、学習データセットでの評価はR=0.7の評価を得る見込みもないでしょう。
※弊社では、データ分析プロジェクトにまつわる様々なご相談に、過去20年以上に渡るプロジェクト経験に基づき、ご支援しています。社内セミナーの企画等、お気軽にご相談いただければ幸いです。
製品カタログ
この記事が気に入ったらサポートをしてみませんか?