
【初心者向け】SQLを書くときに使えるTips集

こんにちは。VoicyでPMをしているノムラです。
エンジニアメンバーが社内でSQL塾を開いてくれ、1日に1SQLを書いて理解を深めるということを数カ月したところ、自分にとって必要はデータを取得するのに必要なSQL知識をマスターすることができました。SQL塾を開催してくれたエンジニアメンバーには感謝しかないです…ありがたい。
そんなSQL初心者からちょこっとレベルアップしたものの、SQLを書くときはメモを見ながらです。そのメモを社内で共有したところ、割と好評だったので、社外の誰かに役に立つかもと思いnoteにも書いてみました。
自分がSQLを書くときにあったら便利だなと思ったTip集です。
少しでも役立つことがあると嬉しいです!
そして、もし間違いがある際はこっそり教えていただけると泣いて喜びます…。
前提
以下の環境が前提となります。
・データ元:BigQuery
・データ抽出:BigQuery または Metabase を使用
select文Tips
◆ テーブル1つから、条件にあったデータを取得する場合
・カラムをすべて取得する場合は、selectの後に「*」を指定する
・指定したカラムの重複行を削除したい場合、カラム名の前にdistinctを付ける
・テーブル名は「``」で囲む
・where句で抽出したいデータの条件を指定する
・カラムの値がstring型の場合は「''」で囲む(テーブル名の「``」とは違うので注意)
カラムの値が数値(integer型など)の場合は、「''」は不要
・order by で指定したカラムの降順、昇順を指定可能(指定しない場合は、デフォルトで昇順になる)
- 昇順:カラム名の後に「asc」を指定
- 降順:カラム名の後に「desc」を指定
select
distinct カラムA,
カラムB,
カラムC
from
`テーブル名`
where
カラムC = '○○'
order by
カラムB desc
;・where句で使用できる比較演算子

・where句でカラムの値がnullのもの、nullでないものを取得するときの書き方

・where句でカラム名をあいまいに指定してデータを抽出したい場合

・where句に幅のある値を指定したい場合

・where句に複数条件を指定する場合

◆ 集計したデータを取得したい場合
・group byで指定したカラムでグループ化する
・カラム名を新たに設定した場合、カラム名の後ろに「as 新しいカラム名」を設定する
・集計結果に条件を指定したい場合、having句で条件を指定する
select
カラムA,
count(カラムB) as cnt
from
`テーブル名`
where
カラムC = '○○'
group by
カラムA
having
cnt >= 1
order by
cnt desc
;・集計で使える関数は以下

内部結合と外部結合
◆ 2つのテーブルを結合してデータを取得する場合
・内部結合:それぞれのテーブルの指定したカラムの値が一致するものだけを結合
・外部結合:内部結合のようにそれぞれのテーブルの指定したカラムの値が一致するものを結合するのに加え、基準にしたテーブルにしか存在しないデータも取得
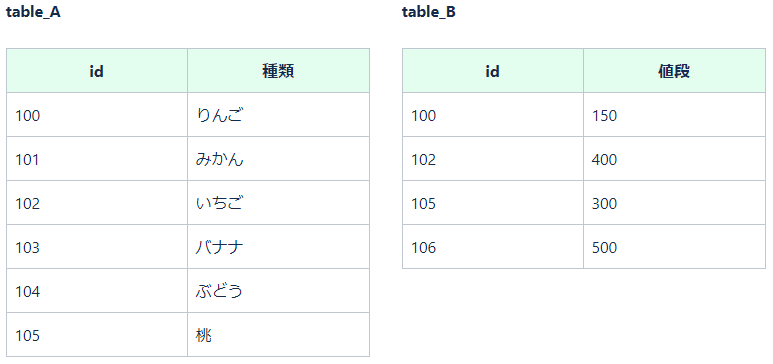
・内部結合:table_Aとtable_Bを結合した場合(joinと書いた場合、inner joinを表す)
select
a.id,
a.種類,
b.値段
from
`table_A` as a
join `table_B` as b
on a.id = b.id
;
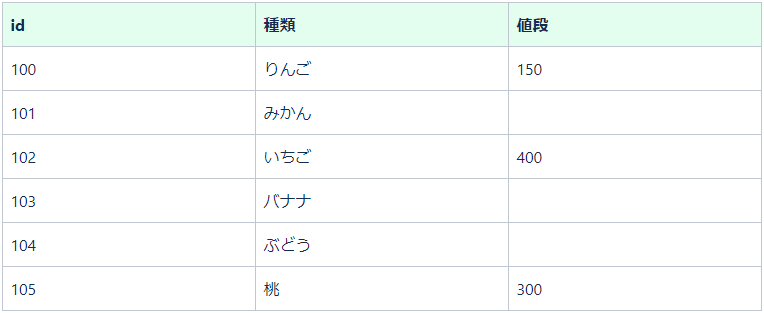
・外部結合:table_Aとtable_Bを結合した場合
- left outer join:左側のテーブルにあるカラムを基準に結合する(左側のデータは全て抽出される)
- right outer join:右側のテーブルにあるカラムを基準に結合する(右側のデータは全て抽出される)
select
a.id,
a.種類,
b.値段
from
`table_A` as a
left outer join `table_B` as b
on a.id = b.id
;
with句
・with句で記述したselect文で抽出したデータを、1つのテーブルとして扱うことができる
・with句の後ろで記述するselect文のfrom句に指定したり、結合するテーブルに指定することができる(結合しなくても単体のテーブルとして使用可能)

日付処理
◆ データとしての日付
・データの日付には以下の型がある(TIME型、YEAR型はいったん除く)
- DATE型:'YYYY-MM-DD' 形式
- DATETIME型:'YYYY-MM-DD HH:MM:SS'(範囲は '1000-01-01 00:00:00' から '9999-12-31 23:59:59')
- TIMESTAMP型:'YYYY-MM-DD HH:MM:SS'(範囲は'1970-01-01 00:00:01' UTC から '2038-01-19 03:14:07' UTC)
※ BigQueryに入っているデータは全てUTCのタイムゾーンデータとなっているため、日本時間基準でデータを参照したい場合は、タイムゾーンの設定変更が必要
◆ 良く使用する日付処理
【日付のフォーマット変換】
- TIMESTAMP型をDATE型に変換する(タイムゾーン設定は省略可能)
* DATE(timestamp型のカラム, 'Asia/Tokyo') :日本時間のYYYY-MM-DD
- TIMESTAMP型をString型に変換する(タイムゾーン設定は省略可能)
* FORMAT_TIMESTAMP('%Y-%m-%d', timestamp型のカラム, 'Asia/Tokyo') :日本時間のYYYY-MM-DD
→'%Y-%m-%d'の部分は色々な設定が可能
→詳細は こちらのページ 参照
* FORMAT_DATE('%Y-%m-%d', date型のカラム):YYYY-MM-DD
→'%Y-%m-%d'の部分は色々な設定が可能
→詳細は こちらのページ 参照
【日付の計算】
指定した間隔(日数)を追加:
- DATE_ADD(date型のカラム, INTERVAL XX date_part)
- date_partに指定可能な設定は以下
* DAY
* WEEK(7 DAY と同じ)
* MONTH
* QUARTER
* YEAR
指定した間隔(時間)を追加:
- TIMESTAMP_ADD(timestamp型のカラム, INTERVAL XX date_part)
- date_partに指定可能な設定は以下
* SECOND
* MINUTE
* HOUR(60 MINUTE と同じ)
* DAY(24 HOUR と同じ)
指定した間隔(日数)を引く:
- DATE_SUB(date型のカラム, INTERVAL XX date_part)
- date_partに指定可能な設定は以下
* DAY
* WEEK(7 DAY と同じ)
* MONTH
* QUARTER
* YEAR
指定した間隔(時間)を引く:
- TIMESTAMP_SUB(timestamp型のカラム, INTERVAL XX date_part)
- date_partに指定可能な設定は以下
* SECOND
* MINUTE
* HOUR(60 MINUTE と同じ)
* DAY(24 HOUR と同じ)
【日付の差分取得】
日付1と日付2の差分を取得:
- DATE_DIFF(date型のカラム1, date型のカラム2, date_part)
- date_partに指定可能な設定は以下
* DAY
* WEEK(この日付パーツは日曜日から始まる)
* WEEK(<WEEKDAY>)(この日付パートは WEEKDAY から始まり、WEEKDAY に各曜日を設定可能)
* MONTH
* QUARTER
* YEAR
- TIMESTAMP_DIFF(timestamp型のカラム1, timestamp型のカラム2, date_part)
- date_partに指定可能な設定は以下
* SECOND
* MINUTE
* HOUR(60 MINUTE と同じ)
* DAY(24 HOUR と同じ)
◆ テーブルサフィックスとしての日付
・データ量が多いログ系のテーブルは、日付ごとにテーブルが分かれている(日付のパーティショニングテーブル)
→1つのテーブルにしてしまうと、データ量が多く、select文などで処理をする際に重くなってしまうため(下記図参照)
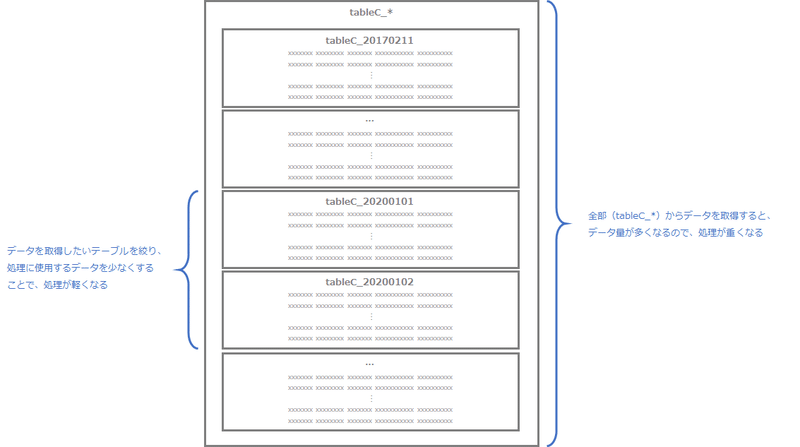
・日付ごとのテーブルになっているため、複数のテーブルを参照する際に工夫が必要
→その際に使用するのが、where句で使用できる「_TABLE_SUFFIX」
例:2020/09/01~2020/09/19のtableC_*データを取得したい場合
select
*
from
`tableC_*` as play
where
_TABLE_SUFFIX between '20200412' and '20200419'
;配列
・条件にあったデータの1行目と2行目を取得したい、などの場合に使用できる
・select句で「array_agg(distinct カラム名 order by カラム名)[SAFE_OFFSET(X)] newカラム名」と記載する
・[SAFE_OFFSET(X)]のXは「0」が1行目となる
・行として持っているデータを列に変換することができる
例:最初のデータの日付と次のデータ日付を取得し、差分を計算している
with table_d as (
select
column_a,
array_agg(distinct date_b order by date_b)[SAFE_OFFSET(0)] first_date,
array_agg(distinct date_b order by date_b)[SAFE_OFFSET(1)] second_date
from
`tableD`
group by column_a
)
select
TIMESTAMP_DIFF(second_date, first_date, DAY) as day,
count(column_a) as cnt
from
table_d
where
second_date is not null
group by day
order by day
;学びのための書籍代やITツール購入代に利用させていただきます。得たものはnoteで還元していければと思っています!