
Photo by
shinobuwada
第2回:陸遜・法正をAI画像判定「過学習解消に向けて」

AIを手軽に導入出来る「MatrixFlow」を使いディープラーニングを実施。機械学習の実装体験/個人の振り返り用としてnoteに記す。
目的:陸遜と法正の画像を分類したい

課題:過学習を解消
「過学習(過適合)」とは、学習(訓練)データにあまりに適合しすぎて、学習(訓練)データでは正解率が高いのに学習(訓練)データとは異なるデータ(例えば、評価データ)では正解率が低くなってしまう、つまり、学習(訓練)データだけに最適化されてしまって汎用性がない状態に陥ることです。 https://ai-kenkyujo.com/2020/01/16/kagakushu/
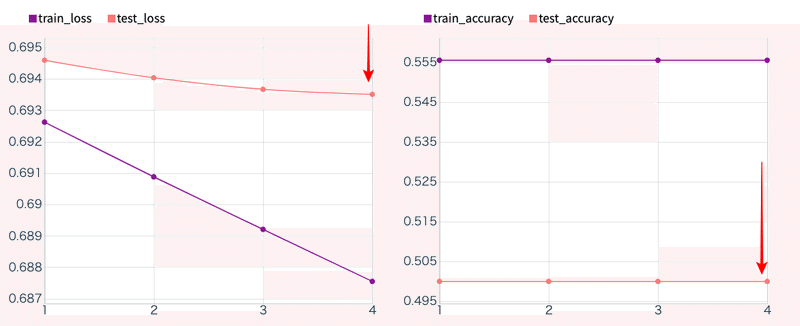
第1回のディープラーニングの解析結果

学習回数:4
機械学習:10秒
使用データ:20枚
正答率:50%
対策:
①学習データを増やす
20枚 ⇛ 80枚 (4倍に増強)

②正規化する
データを一定のルールに基づいて変換し、利用しやすくする操作
正規化する理由
もし特定の変数に大きな値が入っている場合、そのまま学習に使うと、その変数に引き寄せされてしまう。各関数の分散を揃えていくことにより、どの変数に対しても平等に取り扱うことができる
正規化の代表的な方法:データの標準化
入力データの変数を平均0、分散1になるように変換する操作
データの標準化をすることにより入力するデータの各変数は平等に取り扱うことができるが、ディープラーニングは層を重ねているため、入力データ以外の各層においても同様のことが出来ないか → バッチ正規化
バッチ正規化
各層への入力を正当化することで、学習を安定化し、過学習を起こしにくくする操作のこと
補足:各層で伝わってきたデータをその層で、また正規化を行う。バッチ正規化を使うことにより学習が向上し、過学習を起こしにくくなる
MatrixFlowでの標準化方法

データ入り口(画像)→標準化にチェック
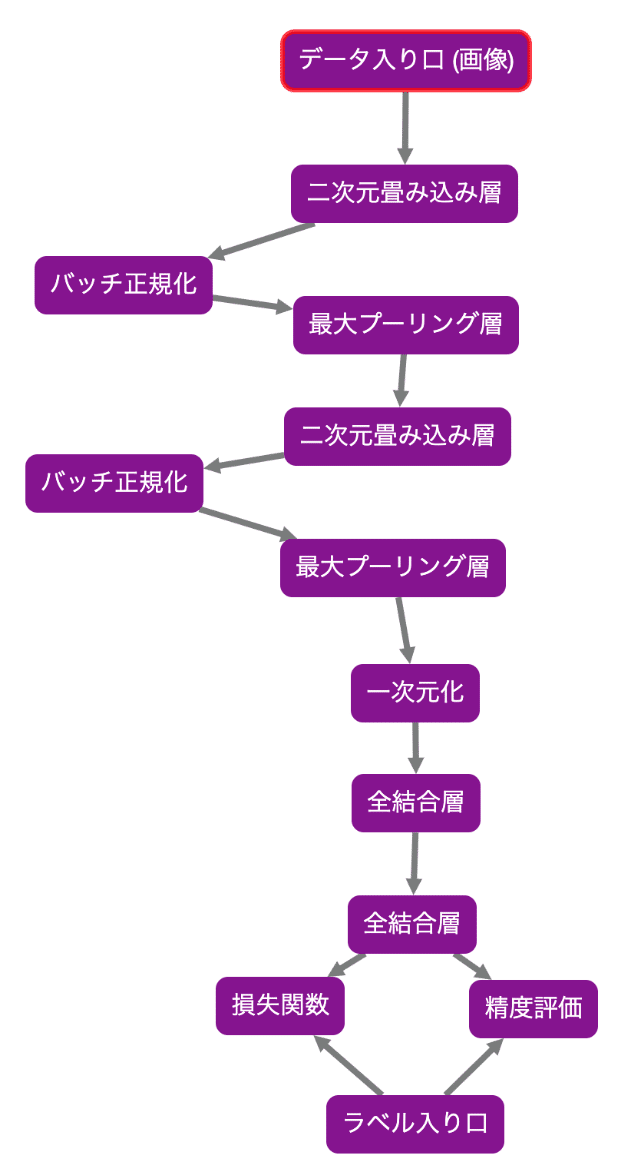
※ 「バッチ正規化」を「二次元畳み込み層」の真下に再設置(矢印に注意)
再度AIに学習をさせて精度の違いの確認
学習率:0.0001
バッチサイズ:64
エポック:15
学習回数:16
評価間隔(学習データ):1
評価間隔(テストデータ):1
学習結果:
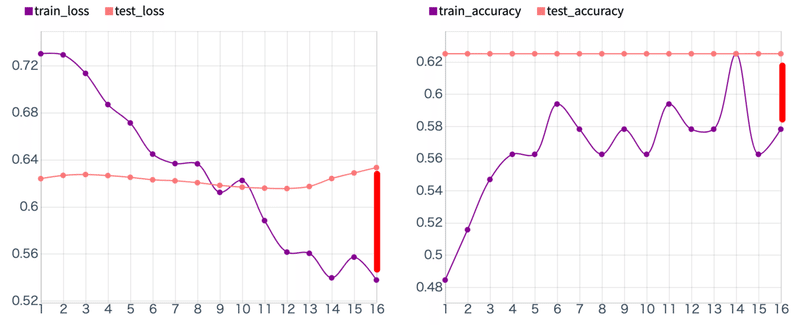
「test_loss と test_accuracy」の乖離や「train_accuracy と test_accuracy」の乖離が第1回目と比べると大幅に小さくなった
第1回 ディープラーニング解析結果との比較
推論結果
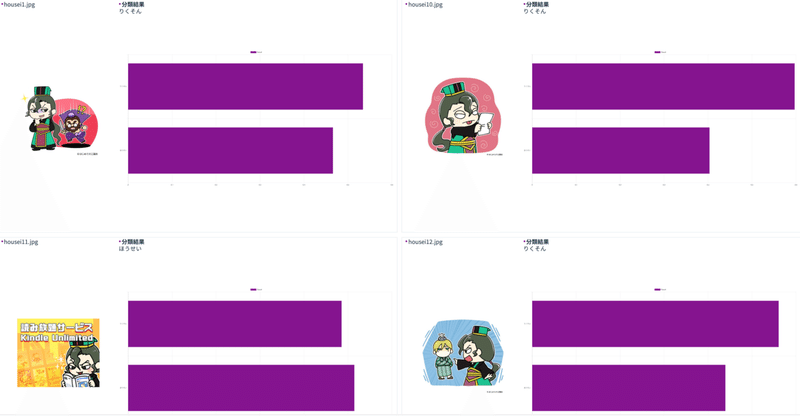
推論結果:80枚中48枚正解(train_accuracy:約60%)
学習回数:16
使用データ:80枚
正答率:60%
第1回目と比べると精度率が10%向上
第3回では、学習用データをさらに追加するため「データ拡張」を行い、精度向上をすることを目標とする。
参考:
この記事が気に入ったらサポートをしてみませんか?