
画像生成AIによる漫画ネーム作成の試行~メンズエステセラピストの憂鬱~

こんにちは。
パインブックです。
今回は、画像生成AIで漫画原作のネームに挑戦した模様について書いていきます!
~その前にご案内~
次は、画像生成AIでWebtoonを作ってますのでこちらも是非ご覧ください↓
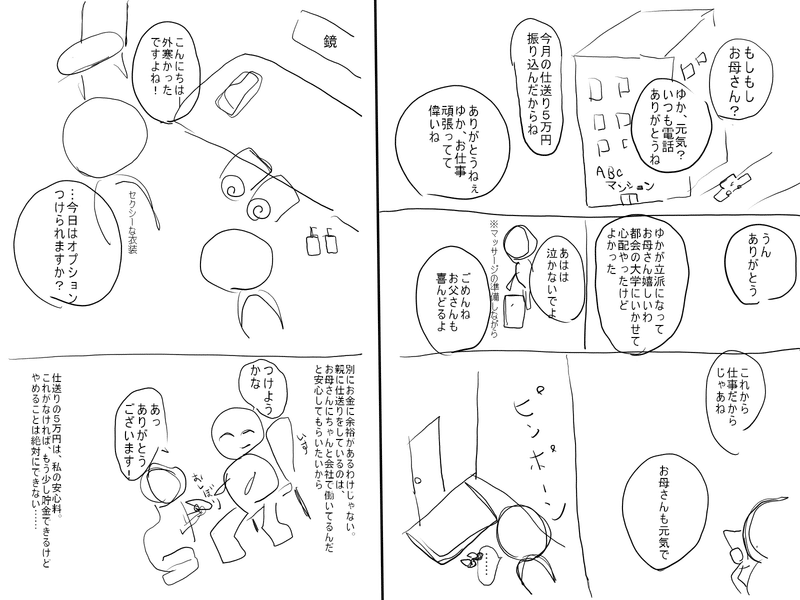
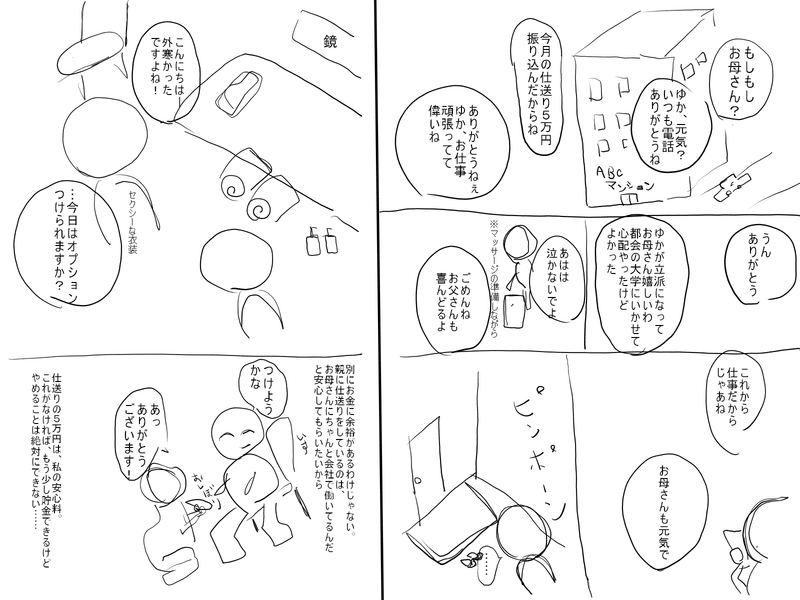
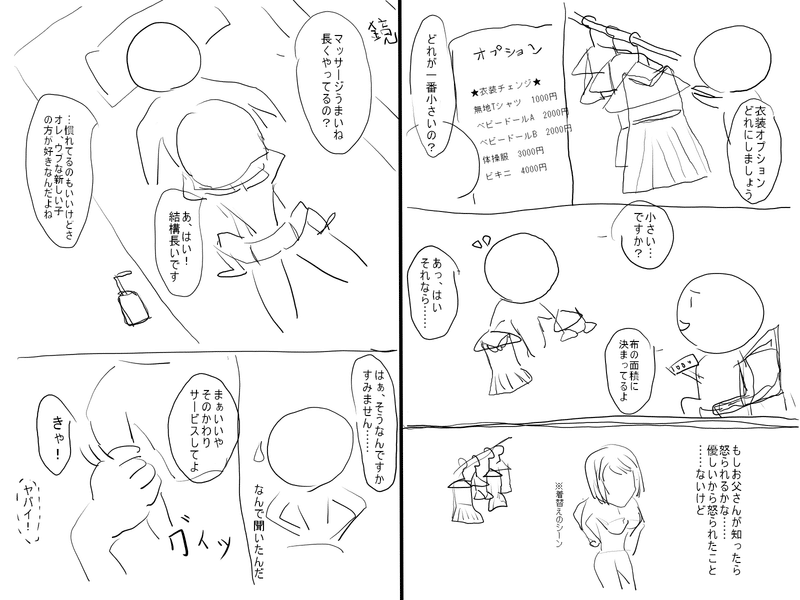
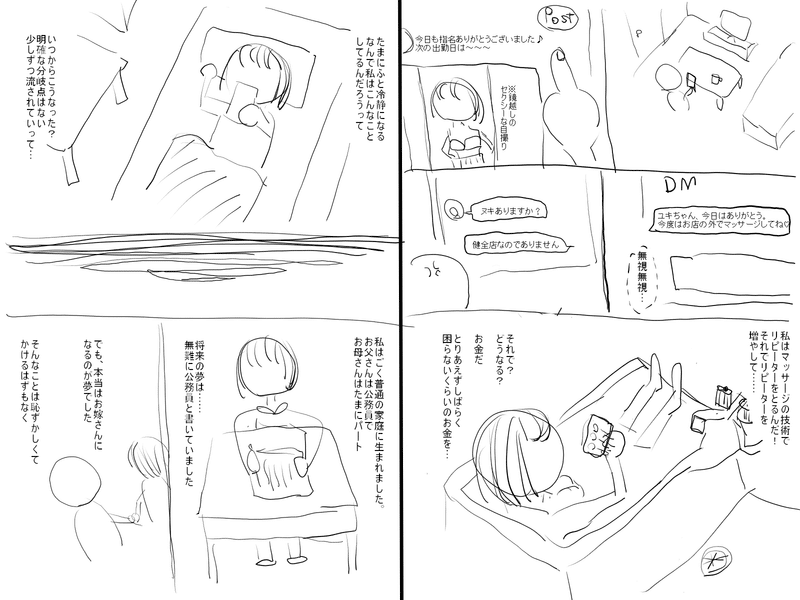
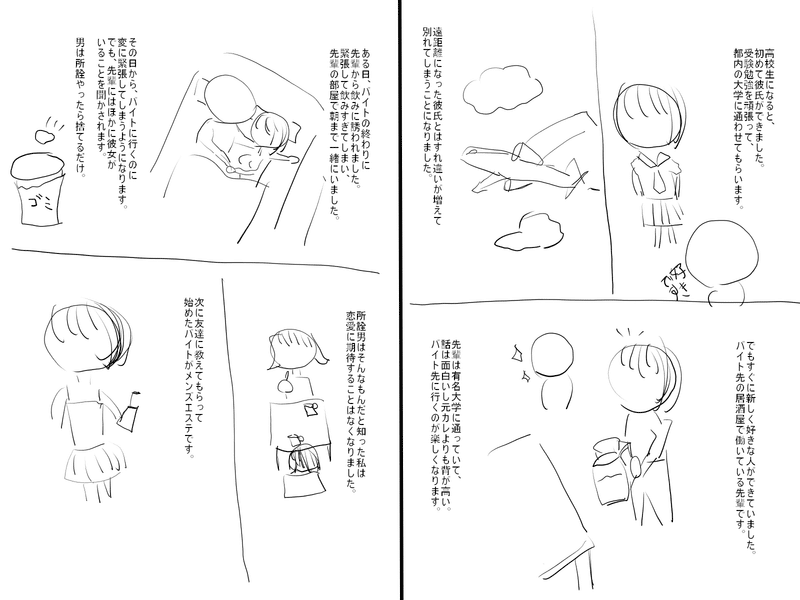
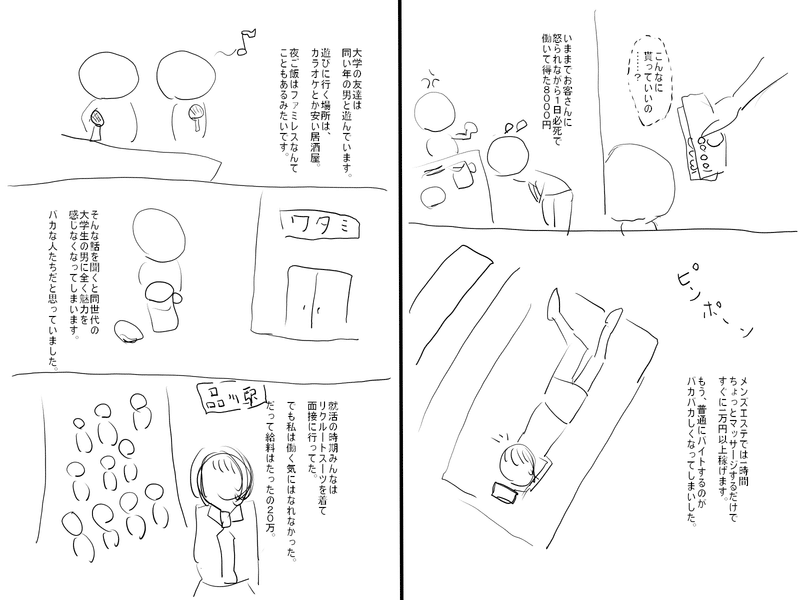
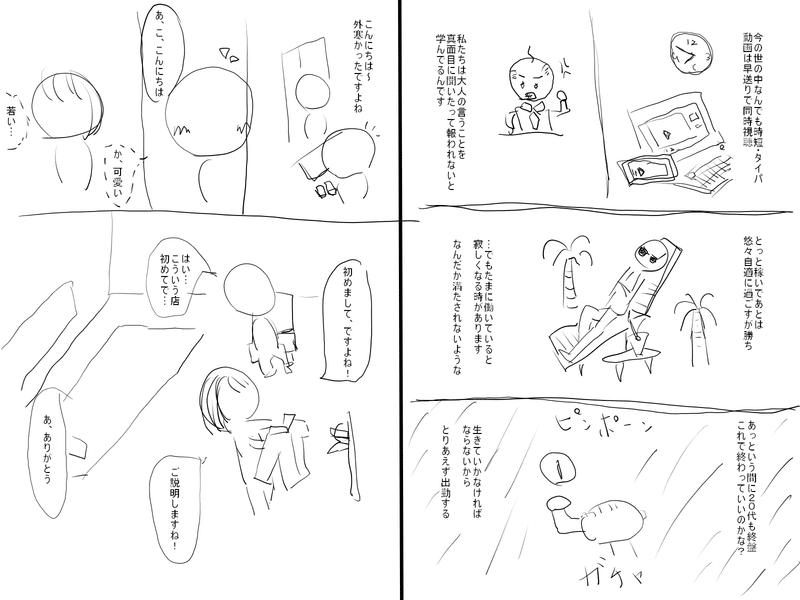
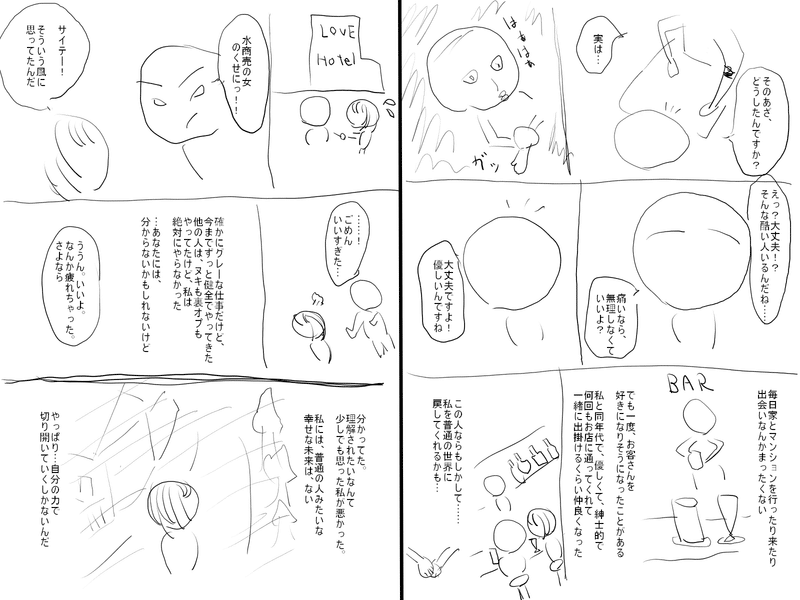
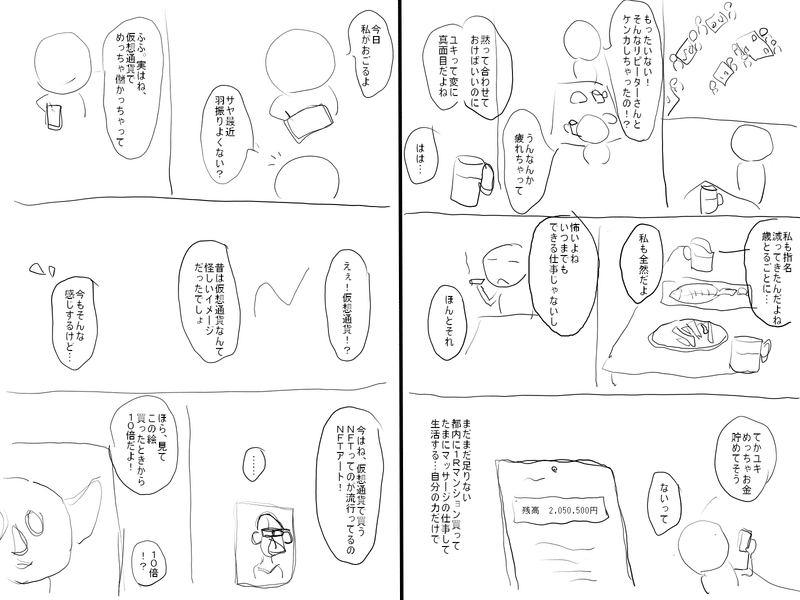
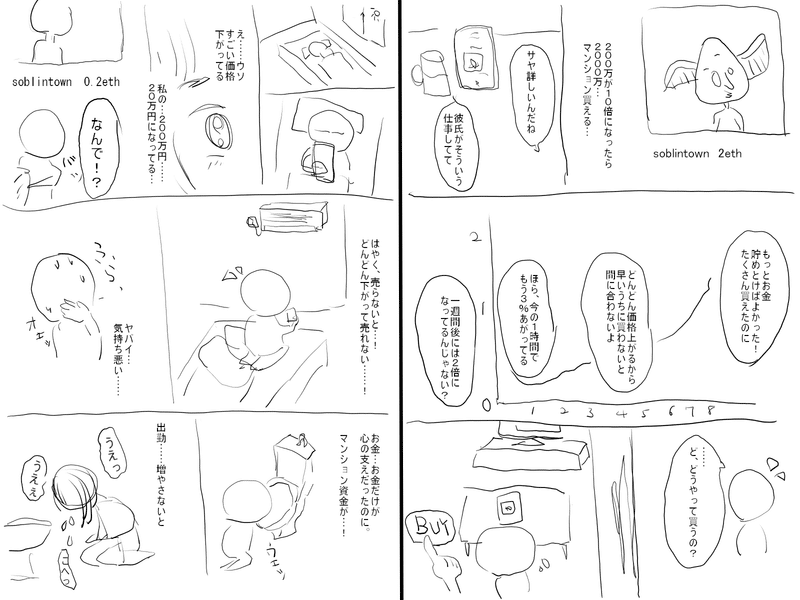
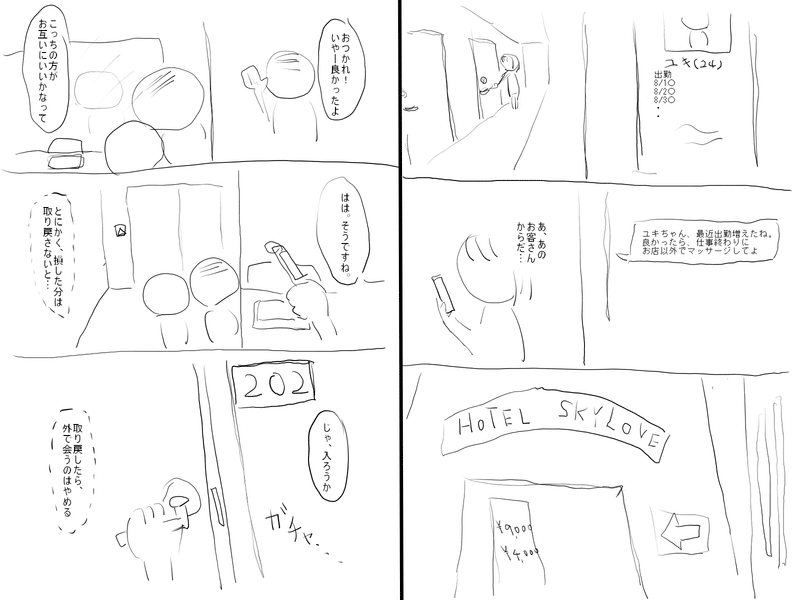
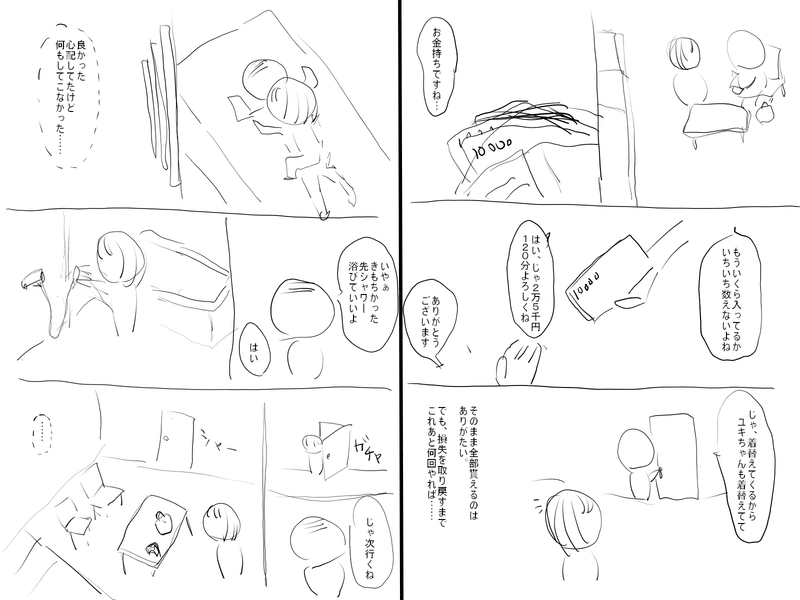
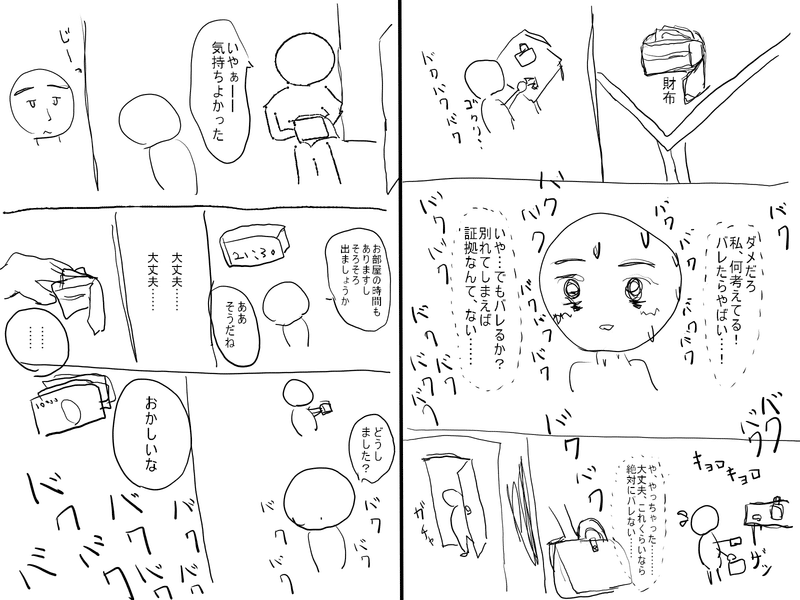
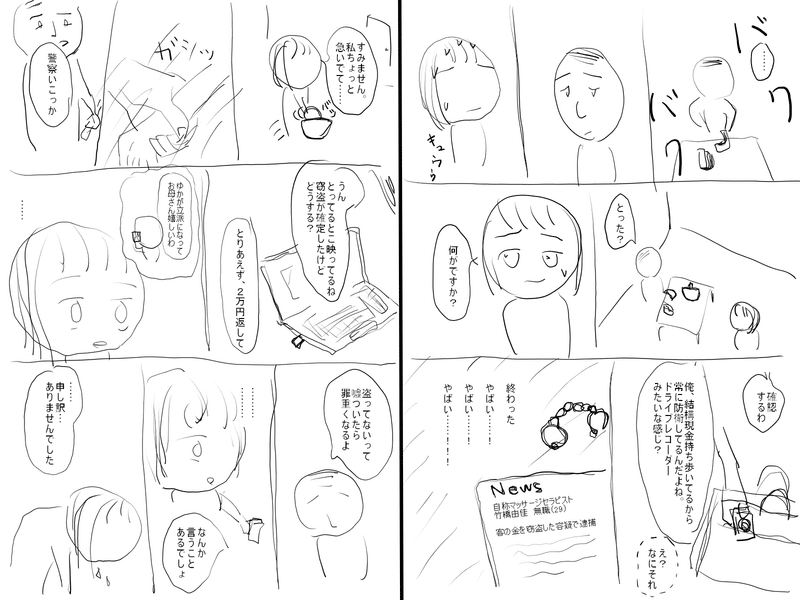
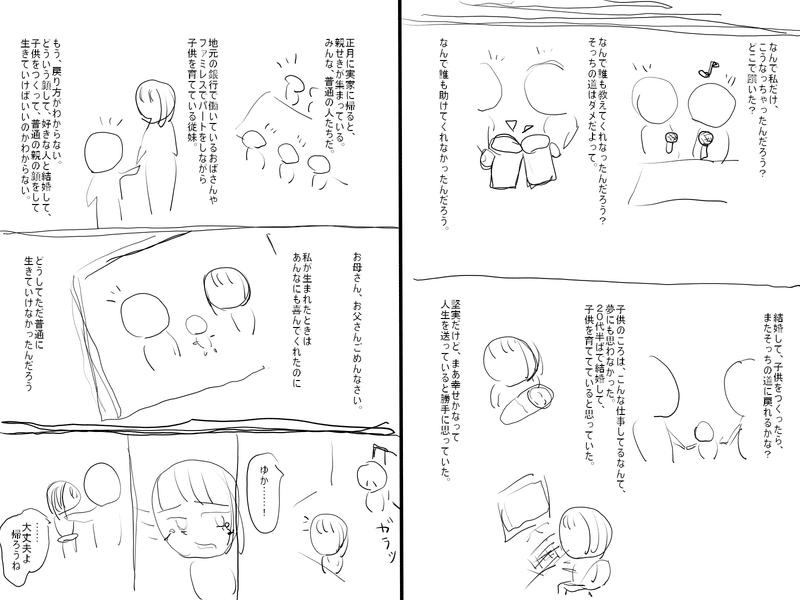
まず最初に、できたネームについてはこんな感じです↓



私はほぼ漫画のネームを書いた経験がなく、雰囲気で作ってます。
上記ネーム作成にあたりペンほとんどは使ってません。
順序。
今回AIネームを作った順序としては
①まず文章で読み切りの漫画原作を書く。
文章は5000字くらいで、シナリオ形式です。
②その文章の原作のセリフを、32ページに割り振る。
③32ページ分のセリフの吹き出しだけをページに載せていく。
④板タブでなんとなくの棒人間と構図のネームを書く。
(↓のような感じです。下手です)
⑤4で作ったネームをもとにイメージに合うキャラクターとポーズを画像生成AI、Stable Diffusionでバーッと大量に出力してみる。
⑥キャラのイメージが決まったら、線画に特化したLoRA、Lineartを使ってモノクロ漫画の線画にしていく。
⑦背景は実際の写真や、GoogleMAPのスクショを線画加工する。
(ネームなのでイメージのために用いるものです)
⑧素材をもとにAIネームを作成する。
画像を線画化するLoRAがすごい。
今回、初めてまともに画像生成AIのStable Diffusionを触りました。
画像生成AIが流行ったMidjourneyが出たすぐのころは、Discordでちょっと触っていたのですが、生成にすごい時間がかかるし、プロンプト(呪文)を書くのがかなり大変で、全然自分の思うものが出力できませんでした。
この頃に実際に画像生成AIで漫画を作られていたのがRootportさんの「サイバーパンク桃太郎」ですね。
Amazonによると発売自体は2023年3月ですから、まだほんの半年前です。そこから画像生成AIはかなり進化してますよね。(実際に作成されていたのはもっと前ですが)
それからずっと触ってなくて、NovelAIが出て二次元の可愛い絵が簡単に出せるようになったくらいは把握していたのですが、そこからLoRAというのが出てきているのは全然知りませんでした。
Stable DiffusionのLoraとは、「Low-Rank Adaptation」の略で、低コストでAIの追加学習を行い、好みの画像を簡単に出力できるようにするツールです。
このLoRAという仕組みにより、モノクロ漫画のような線画の絵が簡単に出力できるようになっていたんです。

私もあんまり詳しくないんですが、
画像生成AIで絵を生成する際、例えばテキスト(プロンプト、呪文)を書いて生成する場合は、
テキスト→モデル(NovelAIとか)→LoRA(Anime Lineartとか)→生成
という流れになっていて、LineartLoRAの前段階のモデルを設定する際に、モノクロ漫画風のモデルを設定することもできるんですよね。
でも、色々試してみたんですが、モデルの段階でモノクロ漫画風のモデルを使うと、生成された画像が残念なものになっちゃう確率が高いんです。
たぶん、教師データの質が微妙なんですかね?
なので、自分好みのモデルを使ってカラーの絵を生成した後に、LoRAでモノクロ化、線画化する方が良い絵を生成できると思います。
私の場合は、AnyLoRAをというモデルをよく使っていました。
ただ、Anime LineartのLoRAを使ったからすぐにキレイなモノクロの絵が生成できるかというとそんな簡単でもなく、全然変な風に絵が変わっちゃったりします。
どの程度の数値でLoRA反映させるかなど、結構な試行錯誤が必要でした。
思い通りの絵を生成するimg2imgがすごい。
LoRAの他に驚いたのは、img2img(image to image)ですね。
今までは、テキスト(プロンプト、呪文)を書いて絵を生成していたのですが、イメージ画像をもとに+プロンプトで絵を生成できるようになっていました。
だから、生成したいキャラのポーズや構図のラフを書いて読み込ませたり、実際の人間の写真を読み込ませたりして、絵を生成することができます。
テキストで絵を生成してから、気になるところをペンで直して、それをもとにimg2imgでもう一度画像生成なんてこともできます。

上画像の場合では、テキストで生成した絵では、女の子のスカートと袖部分が黒色でした。
ここを白色にしたいのですが、テキストで「スカート白、袖は白い」とかプロントを入力しても、なかなか思ったように生成してくれないんですよね。
なので、自分でスカートと袖を白くペンで塗っちゃって、その絵をimg2imgで画像生成します。
すると、思い通りスカートと袖部分が白色になってくれました。
このimg2imgのおかげで、今までよりもかなり効率的にイメージ通りの絵を生成できるようになったと思います。
他にも、コントロールネットという、棒人間を書けばその通りのポーズを出力してくれる機能などもあります。
あとは高画質化、背景削除といった便利ツールもあるんですが、私が特に驚いたのは上記のLoRAとimg2imgですね。
画像生成AIネームのデメリット。
画像生成AIでネームを作るうえでデメリットは、とりあえず以下が思いつきます。
・常に同じ髪型、顔、服装のキャラを生成するのが難しい。
img2imgがあるとはいえ、毎回同じ髪型・服装のキャラを安定して生成するのはかなり難しいです。なので、大量に生成しまくらないといけません。
ただ、ネームのレベルであれば、どれがどのキャラか分かればいいので必ずしも全く同じ服装じゃなくても良いかもしれません。
・ネームなんだから、自分で書いちゃった方が早くない?
そもそも漫画を完成させる前のラフがネームなんだから、わざわざ画像生成AIでキレイなキャラを作らなくてもいいんじゃないかということです。
現段階の画像生成AIでは、完成版の漫画を作るのは流石に厳しいけれども、ネームならいけるんじゃないかということで今回AIネームを作りました。
でも、そもそもネームなんだから、ラフな手書きでいいのでは?ということですw
画像生成AIだとなんだかんだ結構時間がかかります。
・キャラの個性、表情が出せない。
やっぱり画像生成AIでつくられるキャラは画一的になっちゃいます。
漫画特有のおおげさな表情も全然つくれません。
どうしても、構図とかポーズの表現が中心になっちゃいますね。

上画像は私の手書きネームの1シーンですが、こんな下手な絵でも表情の表現という点では、画像生成AIに勝っているかもしれません。
・人によっては作業的で楽しくない。
漫画を書きたいと考える方は、もともと絵が好きな方が多いんじゃないでしょうか。私は特にそういうわけではないので当てはまらないのですが、ネームを書くのに楽しさを感じる人もいると思います。
それが画像生成AIネームだと、作業感がすごくて創造的行動をしている感じがしなく、退屈になるかもしれません。
まとめと感想。
画像生成AIでネームを作るのは、上記のようにメリットデメリットがあるんですが、私のように絵が下手すぎる人間にとっては、他人にネームを見てもらう最初のとっかかりになり得るかもと思いました。
手書きのネームだと、「お前漫画舐めてんのか!」と怒られそうなレベルですが、AIで頑張ってキレイ目な絵を作れば、最初の拒否反応は軽減されそうです。
ただ現状のところ、完成版の漫画作成のために使うには難易度が高すぎ、ネームとして使うには時間がかかり手書きの方が表情等の細部を書きやすいという、中途半端な感じになっちゃうかなと思います。
ですがLoRAも現在進行形でどんどん進化しているので、上記のデメリットが軽減されればもっと使いやすくなっていくと思います。
ちなみに最近できたこちらのSeaArtというサービスなら、StableDiffusionの環境構築とかしないで、日本語ですぐ画像生成にトライできるので気軽にお試しください↓
https://www.seaart.ai/s/V6R0rm
それでは、今回はこんな感じで終わりたいと思います。
最後に、32ページ書いた読切ネームを載せますので、もし興味があれば読んでみて頂けると嬉しいです。
メンズエステのセラピストが窃盗で捕まる話です。


この記事が気に入ったらサポートをしてみませんか?