
三麻順位予想計算機の開発者からの見解

概要
三麻順位予想計算機(以下予測機) https://sanma-calculator.glitch.me/ の開発者のぽこです。2年前に作った予測機に関して、内部モデルの特徴や弱点、過去の開発模様や今後のアップデート予定などについて説明したいと思います。
予測機v1.xの歴史
v1.1
2022年の夏、高校を卒業して暇になったために思いつきでcritter氏の四麻順位予想計算機(現在は非公開)をパクって参考にして、三人麻雀版の予測機を作成しました。
計算手法は、モデル訓練方法等の細部を除き、四麻順位予想計算機と同じく多クラスロジスティック回帰ベースを用いました。局ごとに持ち点差から推定順位を返す回帰線を作り、その結果をそのまま表示する形式です。
三麻の持ち点データに関しては存在しなかったので、みーにんさんのメモを参考に三鳳21万半荘(2014~2022のほぼ全て)の牌譜をダウンロードして自分で抽出しました。この処理環境を作るのに1ヶ月ぐらいかかった…


その後見様見真似で単純なロジスティック回帰の機械学習プログラムを書き、データを入れて訓練したプロトタイプ版をv1.1として公開しました。



v1.2
公開直後、仲のいい三鳳民から一部予測がおかしいとの報告を受けました。僅差のオーラスにおいては暫定着順が高いほうが相当有利なゲームですが、その特徴が反映されていないということでした。

確かに暫定着順は大事っぽいので採用
そのため、オーラスのみ暫定着順で6つのモデルに分岐し(3人の着順の組み合わせは6通りであるため)、その上で各暫定順位組み合わせにおいて回帰モデルの訓練をしました。
予測機モデルの定量的な評価方法は確立していないものの、この修正に一定の効果はあったと(主観的にではあるものの)判断したため、これをv1.2として公開しました。

v1.3
さらなる精度向上を目指そうとしましたが、私が機械学習に疎いこともあり有効なアルゴリズムを生み出すことができず、同年9月に渡米し大学に入って忙しくなり、開発資料と処理プログラムを一部喪失して萎えたので放置してました()
ただ、後述するv2モデルが行き詰まったら現行版に修正を加えたv1.3を繋ぎとして公開するかもしれません。v1モデルも改良余地は多くあるので…
現行モデルの弱点
モデルの不自然な出力の解釈について、一部界隈で説明を求める声が上がっていたので可能な範囲で説明してみようと思います。私自身機械学習の初学者なので、専門の方がいらっしゃれば是非ご指導ください。
離散値問題
第一に、現行のv1.xのベースである回帰モデルは離散値を取る麻雀と相性が非常に悪いです。
例えば点数と勝率にこんな関係があったときに
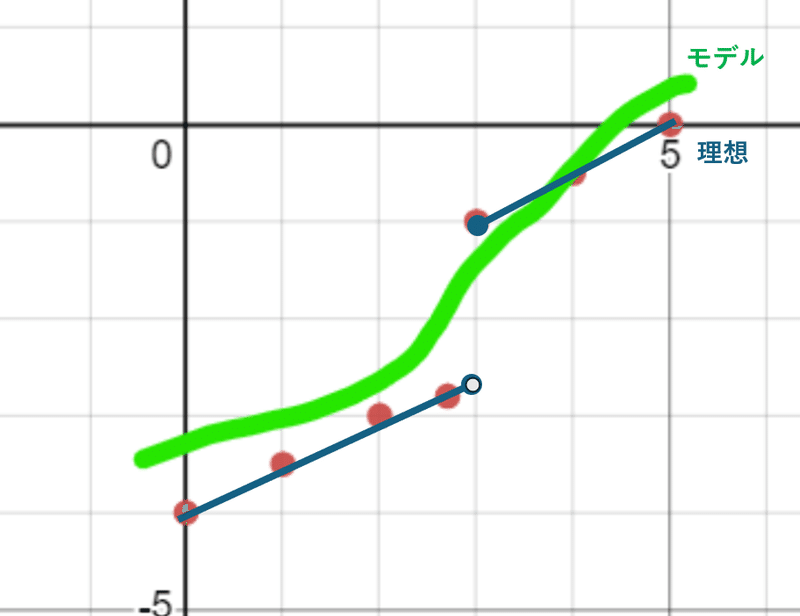
回帰モデルは(例えば)こんな感じで解釈します。本当はx=2.0~2.1の間は微差な一方で2.9~3.0で大きな差が生まれるはずなのに、モデルの反応が鈍いのでこの特徴をうまく捉えられていません。
これが例えばオーラスの8000点差と8100点差の間で生じるのです。このため「満貫横耐えるのになんか期待順位悪くないか?」といったことが発生していると考えられます。
(余談:多層全結合ニューラルネットワークも一瞬試してみましたが、エッジをはっきりさせようとすると過学習のせいか精度が微妙だったので、分散の大きいデータでは無理かなと思いました。ハイパラチューニングをちゃんとやってないので、そのせいかもしれませんが…)
一方で、この現象は残り局数が多ければ終局までの和了点数の組み合わせが無数に増えるため、離散性の問題はほぼ解消されます。つまりゲームが進行するにつれ一般的には推定精度が上昇するものの、トビ寸がいる状況やオーラス付近では性能が悪化する可能性が高いということです。組み合わせ数や本場の影響により南1局あたりまでは問題にならなさそうだと思っていますが、このあたりの定量的な評価は今後の課題とします。
飛び、返し点の問題
局ごとに持ち点差から推定順位を返す回帰線を作り、
このモデルは点数差のみを元に推定をしており、持ち点の情報は取り入れていません。そのため、「飛びに近い」「オーラスあがっても40000点を超えにくい」といった情報が抜け落ちています。これに関しては入力に持ち点を追加すれば解決する可能性があるので、比較対象としてモデルを作るかもしれません。(現行v1モデルの改良余地の一例)
データ数の問題
モデルの訓練にあたってデータが全く足りていない可能性があります。
持ち点データは21万半荘あると前述しましたが、オーラスまでたどり着くのは15万半荘程度です。一方で取りうる持ち点の組み合わせが膨大なため、多少の偏ったデータに出力が左右されているかもしれません。本当は1000万欲しいんです…
この問題は高性能な三麻AIが高速対戦で牌譜を量産してくれるまでどうにもなりません。ちなみにAIの実力向上には高精度な期待順位予測モデル(これ)が必須です。
v2.xの開発予定
こういった事情を踏まえた上で、一定の精度が確保されている序盤のモデルは残し、オーラスのベースモデルを一新してみようというのが開発中のバージョン2の趣旨です。具体的には勾配ブースティング決定木を使ってみる予定です。(初めて使うので試行錯誤になりますが…)
このモデルの長所は入力の大小で分類をしていくという点です。しきい値は訓練によって決定することになりますが、うまくいけば点数差3000(テンパイノーテン)、5200、8000(横移動)、素点12000(親満/跳満で飛び)といった麻雀に特徴的な数字がしきい値に現れると思われます。
現状の課題はこれを細かく分類しすぎると確実にデータ不足で運に左右されたゴミモデルが生まれることと、環境が違い過ぎて現状のWebページに搭載できない(上の係数ベタ打ちを見てもらえればわかるかと思うが、決定木ではこれが使えない)ためフロントエンドの再開発が必要なことと、時間と腕がないことです。なんとかします…
おわりに
多忙な大学生なのでこれから多くの時間が取れないかもしれませんし、機械学習の有識者でもないので現行モデルを超える成果を出すことは約束できませんが、これから改良に取り組んで行こうと思っています。
これまでも、そしてこれからもだいぶ時間を投資するので、満足できるレベルの成果が出たら何らかの付加価値を付けて有料で公開することになると思います。ご理解の程よろしくお願いします。
付加価値案としてはスプレッドシートと連携して自動計算に組み込めるAPIとか牌譜リンクを読み込んで分岐点における諸数値を自動的に弾き出す機能等でしょうか。現行版は最低限の機能しか用意していませんが、課金価値のある高機能で使いやすいインターフェースを設けられればいいなと思っています。
また、活動を支援して頂ける方がいらっしゃれば有料部分の購入をして頂けると頂けると嬉しいです(有料部分は0文字です)。この金額以外のご支援は最下部の「サポート」からお願いします。
これらの収入は研究費に充てさせていただきます。
最後に、いつも意見をくださる三麻打ちの皆様、ありがとうございます。あと拡散して頂けると嬉しいです。
ここから先は
¥ 500
この記事が気に入ったらサポートをしてみませんか?