Q学習の式を理解する

こんにちは!
ぷもんです。
前回、強化学習に必要な「Qテーブル」と「離散値で表す関数」をつくるには?
というnoteで
「Qテーブル」と「離散値で表す関数」をつくりました。
今回はこれらを使ってQ関数を実装しようと考えていました。
でも、こちらの理解すべきコードを見たとき
def get_action(state, action, observation, reward):
next_state = digitize_state(observation)
next_action = np.argmax(q_table[next_state])
alpha = 0.2
gamma = 0.99
q_table[state, action] = (1 - alpha) * q_table[state, action] +\
alpha * (reward + gamma * q_table[next_state, next_action])
return next_action, next_state
for episode in range(num_episodes):
observation = env.reset()
state = digitize_state(observation)
action = np.argmax(q_table[state])
episode_reward = 0
for t in range(max_number_of_steps):
env.render()
observation, reward, done, info = env.step(action)
action, state = get_action(state, action, observation, reward)
episode_reward += rewardここから先、具体的に理解するためには
さらに深く強化学習のQ学習という手法を理解しないと進めそうにない
と気づきました。
なので、今回は難しそうだと思って後回しにしていた
Q学習について学んでいきます。
・Q学習ってなんや?
Q学習とは
各状態sで最適な行動aを与える関数を求める代わりに
各状態sで各行動aでこの先どの程度の報酬がトータルでもらえるのかを求めて
報酬が最大になるものを求めることで
各状態で最適な関数を求めようとする方法です。
ある時tのある状態sである行動aを取った時の価値をQ値として
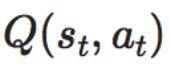
という風に書きます。
・Q学習の2つの式は同じ意味!!
そして、Q学習を理解する上で避けては通れないのがこの式です。
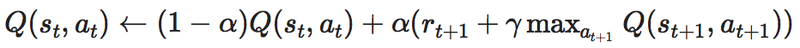
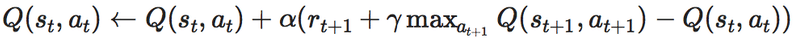
僕もこの式が難しそうで
やりたくなかったのでQ学習の具体的な理解を避けていたのですが
今回はこの式を理解します。
そもそも、上の2式は変形すると同じ式になることがわかります。
つまり、書いている内容は同じなので今回は僕が理解しやすいと感じた
次の式を中心に書いていきます。
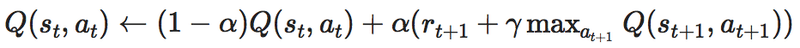
・Q値と報酬Rは別物
1つ目のややこしいポイントが
Q値と報酬Rは別物だということです。
Q値とは(状態行動価値)
報酬Rとはその時点で貰える報酬(即時報酬)
を表していてQ値は価値でRは報酬なので別物です。
Q値は将来も含めてのトータルの価値で
報酬Rは目の前の短期的な報酬みたいなイメージです。
【3目並べで学ぶ強化学習】Q-LearningとDQNを徹底解説 (1/2)
というサイトで書かれていたテトリスの例が分かり易かったです。
テトリスはブロックを消していくゲームなので
1行ずつ消していって「その時点でもらえる即時報酬R」を稼ぐのもいいですが
溜めておいてまとめて消すと最終的にもらえる得点
「状態行動価値のQ値」は高くなります。
こんなイメージでQ値と報酬Rの違いを認識するといいのではないでしょうか?
Q値と報酬Rがわかると
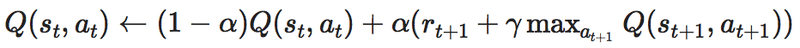
の式のQとrがQ値と報酬Rを指しているのがわかると思います。
ちなみに、MAX{Q(s_{t+1}, a_{t+1})}は
次の時間t+1から先にもらえる報酬合計の最大値のことです。
あとわからないのは
学習率αと割引率γです。
・学習率αってなんや?
学習率αは更新の大きさを決定します。
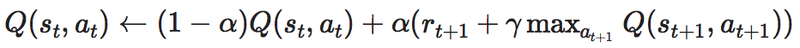
の式を見ると右辺の第一項はsとaについているのがtで
第二項はsとaについているのがt+1になっているのがわかります。
つまり第一項は現在のことを表していて
第二項は現在から一つ進んだ未来のことを表しているということがわかります。
学習率αはこの現在の値と未来の値を
合わせて1になる1− αとαの割合で配分してどれくらい更新するかを決定します。
学習率αについては
強化学習入門 ~これから強化学習を学びたい人のための基礎知識~
の説明が分かり易かったです。
・割引率γってなんや?
続いて割引率γについてです。
割引率γについては
CartPoleでQ学習(Q-learning)を実装・解説【Phythonで強化学習:第1回】
の説明が分かり易かったです。
例えばt=99で、a_99の行動をとり、t=100で成功したとすると
t=99での行動a_99はきっと良かったので
Q(s_99, a_99)には報酬を格納します。
さらに、t=99だけでなく、t=98での行動や状態もきっと良かったと思われます。
t=99での1回の行動で成功したとは思えません。
つまりQ(s_98, a_98)にも報酬を与えたいところです。
さらにt=98だけでなく、t=97以前にも...
でも、最後に成功させたのは
t=99なので
t=98やt=97がt=99と同じ報酬だと不公平な感じになります。
そこで出てくるのが割引率γです。
γは1より小さい値で、未来(t=99)での報酬がt=97までつながるときに
報酬を割り引いて与えます。
t=97の場合、報酬がγ^2だけ小さくなり公平になります。
・つまりQ学習の式がいいたいのは...
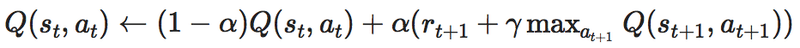
この式が言いたいことは、何回も試行錯誤をやってみて
今の状態のQ値と
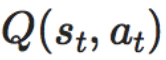
実際に行動してみて時刻t+1でもらった報酬r_{t+1}と
そのさきにもらえるであろう報酬の最大値であるMAX{Q(s_{t+1}, a_{t+1})}に
割引率γを掛けた値の和
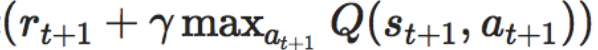
を学習率αで調整しながら足すのを繰り返して
理想の状態に近づけて行こうぜ!
という意味なのかなと思いました。
理解できたような不十分なような
ビミョーな感じですが
コードの理解は進めれそうな気がするので
これで良しとします。
機械学習やってみたいけど何から手をつけていいかわからない
わかりやすく機械学習触ってみることのできるチュートリアル的なものが欲しい方向けにプログラミング素人の僕が動かしてみることができたものを紹介します↓
プログラミングがわからないからこそ、初めての人が躓くところを丁寧に解説していると思います。
全ていくつかのnoteがまとまったマガジンになっていますが無料です。のぞいてみてください!
自分の手で作って、動いている感じがないとモチベーションが続かないという方におすすめです!
このnoteいいなと少しだけ思っていただけた方はスキをいただけるとモチベーションに繋がります!
Twitterなどで共有していただけると喜んでRTさせていただきます!
参考にしたサイトはこちらです!
最後まで読んでいただきありがとうございました。
ぷもんでした!
noteを日々投稿してます! もしいいなと思ってもらえたら サポートしてもらえるとありがたいです。 VRやパソコンの設備投資に使わせていただきます。 ご意見、質問等ありましたらコメントください。 #ぷもん でつぶやいてもらえると励みになります。 一緒に頑張りましょう!