
京都大学11月祭レポートvol.3【KaiRA編part.3】

紅葉の時期の京都で最高学府の知性に圧倒される
紅葉シーズン真っ只中ということで、11月23日の京都は観光客で埋め尽くされていた。

「eスポーツ×生成AI技術イノベーション研究会」の技術協力をしてくださっている「京都大学人工知能研究会KaiRA(以下、KaiRA)」が、11月祭でAIデモの体験会を開催しているということで、京都大学へ。
京都大学といえば、リベラルな学風で知られる日本最高峰の最難関大学である。
日本で一番ノーベル賞受賞者を輩出する知の殿堂で、学生によるAIデモを体験してきた。

part.1では「手書き文字認識AI」を、part.2では「忖度オセロAI」「歌詞からアーティスト判定AI」「フェイク画像判定AI」をご紹介。
今回は残りの二つのAIデモについてご紹介していきたい。
似てる芸能人判定AI
ユーザーの顔写真から、どの芸能人に似ているかを判定してくれるAI。
なかなか遊び心溢れるAIである。
早速私もAIに判定してもらうことにした。

こちらの、疲れた中年の画像で判定にかける。

分析の結果、偉人の名前が並ぶ結果に。
正直、とても気分が良かった。
大物芸能人に、あの伝説的長寿番組のMC、元日本の首相である。
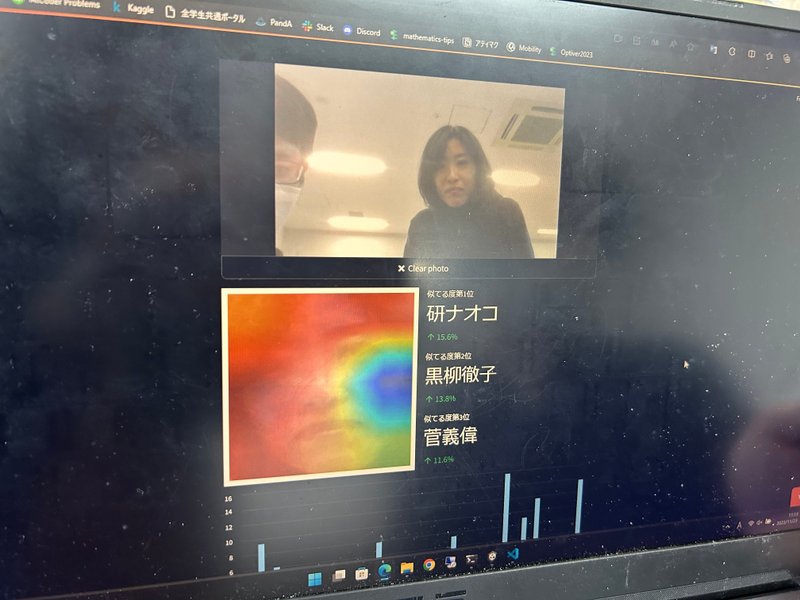

さらに、候補に挙がった芸能人がこちら。
お分かりいただけるだろうか。
数値が高く候補として判断材料にされていた芸能人に「ダルビッシュ有」「大坂なおみ」「王貞治」「羽生結弦」などの名前が挙げられている。
ひと時代を築いたスポーツ選手の顔の要素があるという判定。
一方、「小池百合子」「岸田文雄」といった政治家の顔の要素はほとんどないらしい。
今AI界隈で最も注目を集めるのは「画像認識」「画像生成」の分野。
「画像認識」では「犬ではなく猫と認識できる方法」など、「個別の顔が識別できる」技術開発が白熱している。
それほどハードルが高く、難易度の高い花形技術なのだ。
これだけの芸能人の顔情報を学習させ、判定できるAIを開発してしまうKaiRAメンバーの知力に脱帽。
今後の技術発展に、否応なしに希望を持ってしまった。
ただ、驚愕の写真写りの悪さで、サポートしてくれたKaiRA副会長の山下さんに超絶気を使わせてしまう事態を招いたので、次回に向け写真写りの猛練習はしておこうと思う。
Diffusion Model サンプリング
最後は、AIの「認識技術」を「可視化」したプログラム。
「Diffusion model」という「拡散モデル」の仕組みを可視化できるAIとなる。

そもそも「Diffusion model」とは、ノイズを取り除いていくことで画像を形作っていく生成AIの仕組みである。
画像生成AIで超人気の「Stable Diffusion」のシステムが、これに当たる。
あのクオリティの高い画像は、こうした理屈で生成されているというわけだ。

scikit-learn(サイキット・ラーン)とは、Pythonのオープンソース機械学習ライブラリのこと。
経験や学習から自動で改善を図ることができるコンピューターアルゴリズムが利用でき、分析内容を可視化できる。
データの処理や予測、対処モデルの評価ができるプログラムとなる。
先ほどの「顔認識」とはまた違った「AIプログラムの概念」を学ぶAIとなるが、こうした概念の理解がAIを学ぶ上で非常に大切な「基礎」となる。

グラフの青の点が「0」、オレンジの点が「1」に属するデータ。
分析にかけたいデータを1000個ほど用意し、セットするとどちらかの属性に分類される。
scikit-learnでは様々なグラフでの可視化が可能だが、こちらでは「make_moons」という半月型の形状で可視化する。
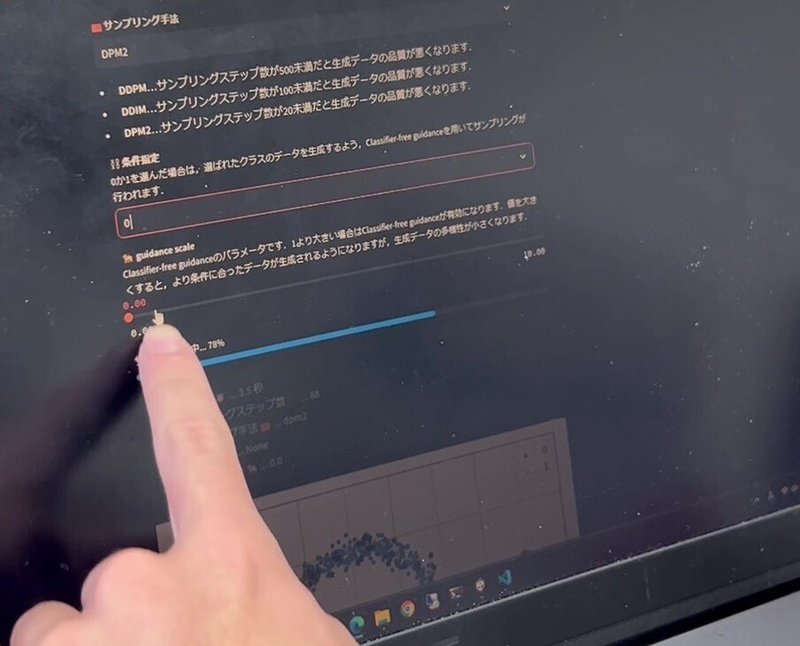
実際に「0(ゼロ)」のデータ量のスケールを調整してみる。
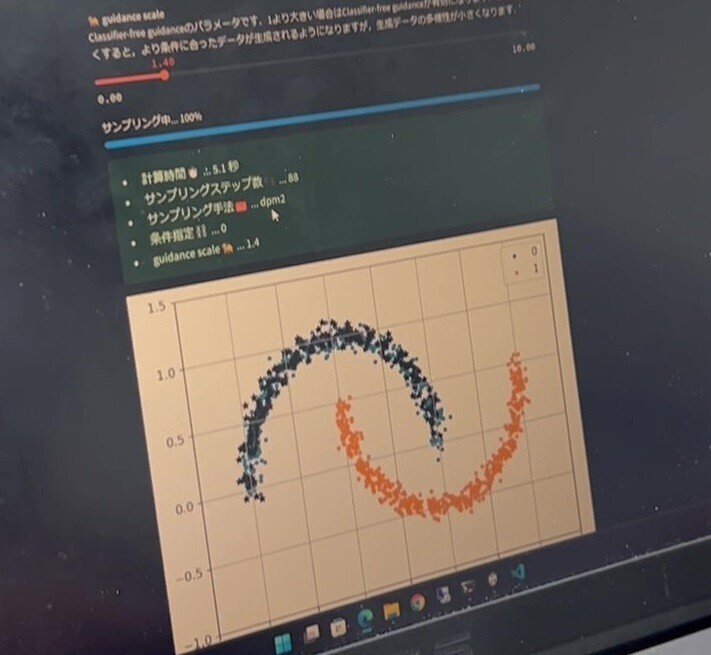
スケールを1に設定すると、青の点の上に黒の点が。
これがサンプリングされた結果である。
理想的な「0要素」の生成ができた証拠でもある。
ここで重要になってくるのが、「生成AIにどれだけの量のデータを学習させるか」ということである。
山下さん曰く、数が多すぎても良い生成物はできない。
「データの質」が影響してくるからだ。

スケールを6に設定した場合のグラフ。
偏りが出てしまっている。

理論上ではスケールは「1」が理想とのこと。
ディープラーニングの世界では、クオリティの高い「適量」データが必要とされる。
ChatGPTなどの生成AIでよく言われている話だが、何回もラリーを繰り返していると、質の悪い生成物になってしまうことがある。
学習させる情報、プロンプトに質の悪いものが混ざってしまっていると、生成物に影響が出てしまうのだ。
生成AIユーザーであれば、一度は経験したことのある事象ではないだろうか。
こうした「AIって本当に頭がいいの?」という素朴な疑問が、実は学習させるデータによる影響ということを、この「Diffusion Model サンプリング」では理解することができる。
KaiRA副会長が語る、生成AIの展望
今回、KaiRA副会長の山下さんに手取り足取り、AIの体験デモをサポートしていただいた。
そこで彼が語った、生成AIの未来。
「画像認識の分野では、もう少ししたら精度の高い情報抽出のものが出てくるかもしれません。」
今最も熱帯びている「画像認識」の分野ということもあり、精度も日進月歩の速さで向上しているのだという。
この流れに乗って、そう遠くない将来、生成AIにかけるだけで簡単に欲しいデータ抽出ができる未来が見えているというのだ。
一方で、「情報処理」に関してはまだまだ時間がかかるという見解だった。
山下さんによると「データ分析に関しては、人間がやった方が良い」とのことで、「仮説を人間が立て、その仮説が正しいかどうかを判断するためにAIを使うことは可能」と話してくれた。
私がeスポーツの戦術構築にAIを活用したい理由の一つに、「対戦チームの戦術傾向分析」を行いたいという狙いがある。
マップ上で特定のチームの動きやクセを数値化したり、マークしている相手チームの選手の動きのクセなどをAIによってデータ化できないか?という何とも無謀な妄想。
これを山下さんにぶつけてみたところ、意外にも「こんな手段が使えるかも」といくつか方法論を提示してくれた。
データ分析の中でも「セグメンテーション」という「領域抽出」技術を使うことで、マップ上での情報抽出は可能ではないかという。
さらに、世界的AIコンペティションの「kaggle」でも「バスケコンペ」や「アメフトコンペ」といって、「どちらのチームが勝つかAIを使って予想する」というテーマも展開されているのだという。
こうしたプログラミングを参考にすれば、使える要素が見えてくるかもしれない、とのこと。
当研究会設立当初は、これほどAIが奥深く、人間の知性に対し新たな価値を叩きつけるほどの存在だとは認識できていなかった。
「eスポーツ大会の運営業務効率化」などとカッコつけてみたものの、尻つぼみで終わってしまうかもしれないという恐怖心を常に抱いていたが、KaiRAとの出会いで未来が開けた。
AIによって、確実に作業工程を削減できる。
今回の京都大学11月祭は、そう確信できる体験にもなった。
この場を借りて、KaiRAの皆さんには心よりお礼を申し上げたい。
そして、12月に予定しているKaiRAによる「画像認識技術」をテーマにした討論会。
こちら、今開催日時を絶賛調整中である。
12/2から変更する可能性があるが、決定し次第告知させていただくので、もうしばらくお待ちいただければ幸いである。
京都大学11月祭では、まだまだ魅力的な展示があった。
足を棒にして体験しまくってきたので、順次レポートにまとめてお伝えしていく。
vol.4へ続く
この記事が気に入ったらサポートをしてみませんか?