
衛星画像からゴルフ場有無を判定する

概要
SIGNATEの【SOTA】産業技術総合研究所 衛星画像分析コンテストにて公開されている衛星画像データを使用して、各画像にゴルフ場が含まれているかどうかを判別するモデルを作ってみます。
使用データ
・衛星名:Landsat-8衛星
・エリア:日本国内全域及び海外7エリア
・大きさ:32px × 32px × 7チャネル
・分解能:1pxあたり30m
・枚数:学習用が296,182枚、評価用が428,697枚
各チャネルの可視化
1つの衛星画像に含まれているチャネルは全部で7つ
バンド 波長 [µm]
1 0.43–0.45(沿岸エアロゾル)
2 0.45–0.51(可視光「青」)
3 0.53–0.59(可視光「緑」)
4 0.64–0.67(可視光「赤」)
5 0.85–0.88(近赤外)
6 1.57–1.65(短波赤外線1)
7 2.11–2.29(短波赤外線2)
from skimage import io
from matplotlib import pyplot as plt
image = io.imread(画像ファイルのパス)
fig, (ax0, ax1, ax2, ax3, ax4, ax5, ax6) = plt.subplots(nrows=1,ncols=7,figsize=(10, 3))
ax0.imshow(image[:,:,0])
ax0.set_title('1')
ax0.axis('off')
ax1.imshow(image[:,:,1])
ax1.set_title('B')
ax1.axis('off')
ax2.imshow(image[:,:,2])
ax2.set_title('G')
ax2.axis('off')
ax3.imshow(image[:,:,3])
ax3.set_title('R')
ax3.axis('off')
ax4.imshow(image[:,:,4])
ax4.set_title('5')
ax4.axis('off')
ax5.imshow(image[:,:,5])
ax5.set_title('6')
ax5.axis('off')
ax6.imshow(image[:,:,6])
ax6.set_title('7')
ax6.axis('off')
fig.tight_layout()
2値(ゴルフ場有無)画像分類モデルの構築アプローチ
PreResnetモデルを採用する。これは高さ=32px, 幅=32pxのCIFAR-100をデータセットとして作成した学習済みモデルである。
preresnet.pyをインポートして、モデルの入出力層を再定義してみる。
import preresnet
import torch.nn as nn
# 層の深さを20に指定
net = preresnet.preresnet(depth=20)
# モデルの入力層の再定義
net.conv1 = nn.Conv2d(7, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
# モデルの出力層の再定義
net.fc = nn.Linear(in_features=64, out_features=2, bias=True)基本的な画像分類タスクの進め方としてまずは転移学習から始める、が一般的かもしれませんが、今回の入力画像はRGBに加えた7チャンネルの衛星画像で、解くべきタスクも特殊なので、ゼロからパラメータを学習するアプローチが良いはず。
最後に評価指標であるが、正解ラベルの分布を見ると5対95と偏ってしまっているので、IoU = TP / (FN + TP + FP)を採用することとした。
衛星画像の前処理設計
・正規化
・水平フリップ(水平方向に画像反転を行う)
・垂直フリップ(垂直方向に画像反転を行う)
・回転(90度、180度、270度)
※データのラベルそのものを変更してしまう恐れのあるズーム処理や元の形状に変えてしまうような回転処理(画像の中に値の存在しない空の部分の生成)は行わない。
import random
import numpy as np
from scipy import ndimage
class Normalize():
def __call__(self, image):
max = 30000; min = 5000 # 画像のピクセル値の分布を見て決める
image_normalized = np.clip(image, min, max)
image_normalized = (image_normalized - min) / (max - min)
return image_normalized
class HorizontalFlip():
def __call__(self, image):
p = random.random()
if p < 0.5:
image_transformed = np.fliplr(image).copy()
return image_transformed
else:
return image
class VerticalFlip():
def __call__(self, image):
p = random.random()
if p < 0.5:
image_transformed = np.flipud(image).copy()
return image_transformed
else:
return image
class Rotate():
def __call__(self, image):
p = random.random()
if p < 0.25:
return image
elif p < 0.5:
image_transformed = ndimage.rotate(image, 90)
return image_transformed
elif p < 0.75:
image_transformed = ndimage.rotate(image, 180)
return image_transformed
else:
image_transformed = ndimage.rotate(image, 270)
return image_transformedData Augmentationの処理は学習時にのみに適用するので、transforms.Compose()と組み合わせるとこんな感じ。
from torchvision import transforms
class ImageTransform():
def __init__(self):
self.data_transform = {
'train': transforms.Compose([
Normalize(),
HorizontalFlip(),
VerticalFlip(),
Rotate(),
transforms.ToTensor(),
]),
'val': transforms.Compose([
Normalize(),
transforms.ToTensor(),
])
}
def __call__(self, image, phase='train'):
return self.data_transform[phase](image)Datasetの作成
Datasetクラスの実装には、
1. __init__:初期化を行う。
2. __len__:1エポックあたりに使用するデータ数を返す。
3. __getitem__:データの読み込み、前処理を行った上で、入力画像と正解ラベルのセットを返す。
が必要
import torch.utils.data as data
from sklearn.model_selection import train_test_split
# image_file_list:学習させる画像ファイル, image_label_list:対応する正解ラベル
x_train, x_val, y_train, y_val = train_test_split(image_file_list, image_label_list, test_size=0.4, stratify=image_label_list, random_state=42)
class SatelliteDataset(data.Dataset):
def __init__(self, image_name_list, label_list, transform=None, phase='train'):
self.image_name_list = image_name_list
self.label_list = label_list
self.transform = transform
self.phase = phase
def __len__(self):
return len(self.image_name_list)
def __getitem__(self, index):
image_path = self.image_name_list[index]
image = io.imread(f'./train/{image_path}')
image_transformed = self.transform(image, self.phase)
label = self.label_list[index]
return image_transformed, label
train_dataset = SatelliteDataset(image_name_list=x_train, label_list=y_train, transform=ImageTransform(), phase='train')
val_dataset = SatelliteDataset(image_name_list=x_val, label_list=y_val, transform=ImageTransform(), phase='val')DataLoaderの作成
DataLoaderはDatasetクラスの動作を管理するクラス。
インスタンス生成の際に
dataset : 使用するデータセットの指定
batch_size : バッチサイズの指定
shuffle : データをロードする順番のシャッフルの有無の指定
といった引数を設定
batch_size = 144
train_dataloader = data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
val_dataloader = data.DataLoader(dataset=val_dataset, batch_size=batch_size, shuffle=False)
dataloaders_dict = { 'train' : train_dataloader, 'val' : val_dataloader }モデルの学習
検証時のベストスコアを更新したときに、そのエポック時点のモデルパラメータを保存するようにコーディングした。
import torch
import torchvision
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as data
from torchvision import models, transforms
from tqdm import tqdm_notebook as tqdm
from sklearn.metrics import confusion_matrix
def train_model(net, epochs, dataloaders_dict, loss_fn, optimizer):
device = 'cuda' if torch.cuda.is_available() else 'cpu'
net.to(device)
best_iou = 0.0
loss_dict = {'train': [], 'val': []}
iou_dict = {'train': [], 'val': []}
for epoch in range(epochs):
print(f'Epoch: {epoch+1} / {epochs}')
print('--------------------------')
for phase in ['train', 'val']:
if phase == 'train':
net.train()
else:
net.eval()
epoch_loss = 0.0
pred_list = []
true_list = []
for images, labels in tqdm(dataloaders_dict[phase]):
images = images.float().to(device)
labels = labels.to(device)
optimizer.zero_grad()
with torch.set_grad_enabled(phase == 'train'):
outputs = net(images)
loss = loss_fn(outputs, labels)
_, preds = torch.max(outputs, 1)
if phase == 'train':
loss.backward()
optimizer.step()
epoch_loss += loss.item() * images.size(0)
preds = preds.to('cpu').numpy()
pred_list.extend(preds)
labels = labels.to('cpu').numpy()
true_list.extend(labels)
epoch_loss = epoch_loss / len(dataloaders_dict[phase].dataset)
tn, fp, fn, tp = confusion_matrix(true_list, pred_list).flatten()
epoch_iou = tp / (tp + fp + fn)
loss_dict[phase].append(epoch_loss)
iou_dict[phase].append(epoch_iou)
print(f'{phase} Loss: {epoch_loss:.4f} IoU: {epoch_iou:.4f}')
if (phase == 'val') and (epoch_iou > best_iou) and (epoch > 10):
best_iou = epoch_iou
param_name = f'./Epoch{epoch+1}_iou_{epoch_iou:.4f}.pth'
torch.save(net.state_dict(), param_name)
return loss_dict, iou_dict損失関数と最適化手法を設定して学習を実行してみる
net = preresnet.preresnet(depth=20)
net.conv1 = nn.Conv2d(7, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
net.fc = nn.Linear(in_features=64, out_features=2, bias=True)
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters())
epochs = 150
loss_dict, iou_dict = train_model(net=net, epochs=epochs, dataloaders_dict=dataloaders_dict, loss_fn=loss_fn, optimizer=optimizer)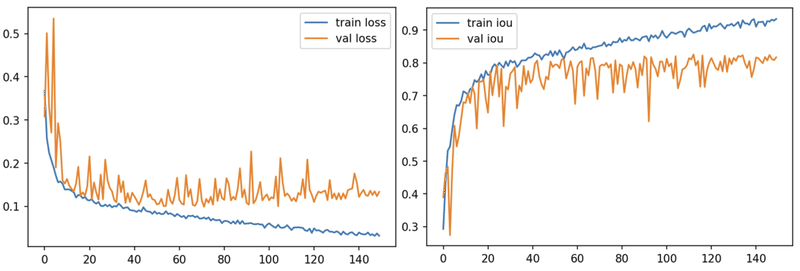
学習用の衛星画像を全て使っているわけではないので、途中から頭打ちになっているっぽいですね・・・
この記事が気に入ったらサポートをしてみませんか?