HR TEAM ASSIGNER

概要
近年、早期離職の増加が、日本国内で目立つようになってきました。
本プログラムは、早期離職防止のための、組織内の人員配置の配属先制限付きのチーム内の相性合計値が最良となるチームを自動で切り出すpythonプログラムです。
要求
・最適な人員アサインがされないことによる早期離職を防止をしたい。
要件
・制約条件を満たしつつ、チームの相性の合計が最適な人員アサインを行う。
具体的には、各チームに割り当てたい各役職の構成が要求されているときに、各チーム内の相性値の合計を最大化し、かつ、構成どおりのチームを出来る限り多く、人員から切り出す。
あなたがもし、200円でこのプログラムをご購入いただき、実用的ソリューションへ組み込み/運用できれば、組織のチーム創出や人員配置に苦しんでいる/苦しまされている方々を救えるかもしれません。
人材派遣会社(リクルートさん)や日本の省庁からベンチャー企業、個人事業主まで、色んな方々に使っていただければ、この上ない幸いです。
✨近日、JOBアサイン機能を付与した
「HR JOB ASSIGNER 」も今年中に公開予定です。乞うご期待!✨
ユースケース
雇用創出・物流・建築・農業・工業・車・製造・鉄鋼・医療・産業・サービス・国防・治安維持などなど、組織がいるところすべて。
まだいない理想的な人員を大量投入したときの、理想的なチームの切り出しシミュレーション 例:理想的人員を募集する雇用創出の根拠作成
各分野の開発チームの切り出し 例:システム開発の新ームの編成
各分野の即席チームの切り出し 例:救急医療チームの編成
各分野の作業チームの切り出し 例:物流倉庫内の動員チームの編成
学校の生徒の組み分け
治安維持を考慮した住民の再配置(100万人レベルの場合、TBオーダーのメモリのサーバーが必要となります。)
人員⇒マシンやものやインフラへ置き換え、相性や利害へ置き換えて、最適なセットを創出する。
等々。
入力データ
1.人員.csv

2.人員相性行列.csv
前提として、人同士の相性値が、何らかのシステムやルールによって数値化できる仕組みがある場所なら導入できます。

説明
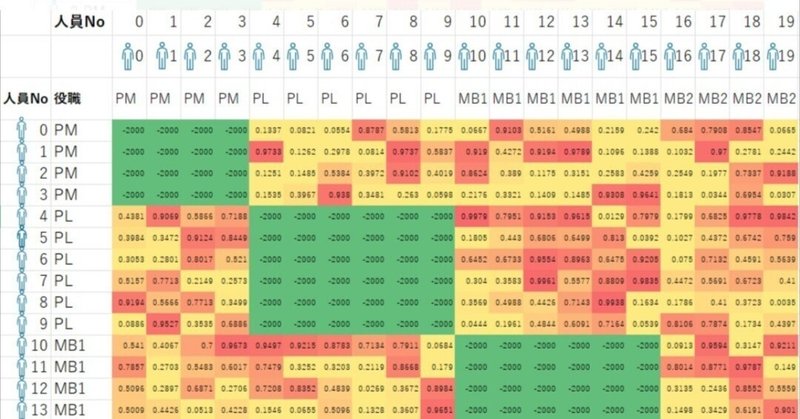
人員相性行列.csvは、以下のように設定しております。
グラフ理論でいう距離行列のような、相性行列を入力とします。そのため、セルの値は「相性値」と呼称します。
役職が同じ人員の相性値にはペナルティを課す。(人員数x-100)
役職が違う人員の相性値は、何らかの計算システムで算出されたスコアそのものが入る。(正であるほど相性が良い⇔負であるほど相性が悪い)
これにより、各チームの役職は一意(unique)で相性の良い人員が自動抽出されます。
なぜこのような形になっているか と言いますと、 既存のアルゴリズム(SAやディリクレ勾配法など)では、「各チームの各役職と人員の役職が一致していること」という制約にしてしまうと、
相性の良い制約を満たす解にほぼヒットしなくなるからです。
※欠点としては 1チームに複数の同じ役職(例:MB) がいる場合に人員.CSVでの割当で、MB1さんに割り当てられた人たちは、互いに相性値が良い(近い)にもかかわらず、同じチームに入れないという点がありまだ改善の余地があるので、解決策を現在考え中です。

出力データ
1.人員_クラスタアサイン_SA.csv

2.人員_クラスタアサイン_ランダム.csv

1.のSA解と2.のランダム解を比べれば、明らかに役職の制約を満たした解をSAが満たしていることがわかりますね。
アルゴリズム
数理最適化の世界では、「二次割り当て問題」と言われるNP困難問題かつ役職の制約付きとなっている亜種であり、これも、おそらくNP困難な問題に属すると思われます。
NP困難な問題は、一般的な総あたり法では、数億年~宇宙が始まってから終わるまでかかるといわれております。
https://www.msi.co.jp/solution/nuopt/docs/examples/html/02-15-00.html
この問題は、現代ではイジング型量子コンピュータ(Google,NEC,D-Wave等)を用いて解くと最適解へ到達できる、とされています。
最適化アルゴリズムの評価値=スコアを「エッジ総和最大化」とし、問題設定の段階で相性距離行列に、以下のようなペナルティを設定し、1チーム内に同じ役職がなるべく違う役職が割り当たるように、仕向けます。
if 同一役職である場合
ペナルティを課す。(-1000)
elif 違う役職である場合
個人同士の相性距離。正の値。大きな正の値ほど良い相性を表します。
Score=相性距離行列の選択されたノードについてのエッジ総和
大きな正の値ほど良い相性を表します。負の値は何らかのペナルティに抵触している可能性があります。
計算結果
{'initial_temp': 100, 'cooling_rate': 0.95, 'iteration': 200000}
Cluster 1 Simulated Annealing Score: 5.563667758390648
Cluster 1 Simulated Annealing Selection: 人員id 役職 アサイン済み
78 78 MB1 True
17 17 PM True
99 99 MB2 True
20 20 PL True
{'initial_temp': 100, 'cooling_rate': 0.95, 'iteration': 200000}
Cluster 2 Simulated Annealing Score: 5.422022279670642
Cluster 2 Simulated Annealing Selection: 人員id 役職 アサイン済み
11 11 PM True
60 60 MB1 True
95 95 MB2 True
45 45 PL True
{'initial_temp': 100, 'cooling_rate': 0.95, 'iteration': 200000}
Cluster 3 Simulated Annealing Score: 5.424611522996566
Cluster 3 Simulated Annealing Selection: 人員id 役職 アサイン済み
70 70 MB1 True
44 44 PL True
19 19 PM True
84 84 MB2 True
{'initial_temp': 100, 'cooling_rate': 0.95, 'iteration': 200000}
Cluster 4 Simulated Annealing Score: 5.338944058762109
Cluster 4 Simulated Annealing Selection: 人員id 役職 アサイン済み
4 4 PM True
33 33 PL True
62 62 MB1 True
85 85 MB2 True
{'initial_temp': 100, 'cooling_rate': 0.95, 'iteration': 200000}
Cluster 5 Simulated Annealing Score: 5.471135955889191
Cluster 5 Simulated Annealing Selection: 人員id 役職 アサイン済み
10 10 PM True
80 80 MB2 True
24 24 PL True
65 65 MB1 True
{'initial_temp': 100, 'cooling_rate': 0.95, 'iteration': 200000}
Cluster 6 Simulated Annealing Score: 5.393305497334894
Cluster 6 Simulated Annealing Selection: 人員id 役職 アサイン済み
18 18 PM True
91 91 MB2 True
71 71 MB1 True
22 22 PL True
Score Comparison:
Simulated Annealing: [5.563667758390648, 5.422022279670642, 5.424611522996566, 5.338944058762109, 5.471135955889191, 5.393305497334894]
Random Assignment: [-29999.23952444291, -19998.22752320065, -60000.0, -19998.04775278287, -9996.614772588986, -9998.284317403832]
Optimized: []比較結果
Score Comparison:
Simulated Annealing: [4.231840655270422, 3.726339601834629, 3.2427952788967866, 3.149744029032717, 3.3057065394925704, 2.2641232260119115]
DirichletGrad: [-9998.220012648215, -9997.781165353577, -19997.91703565801, -9996.62305674835, -19998.096588601205, -9997.577018177139]
Random Assignment: [-29999.558065759495, -9998.375883067849, -9997.625588490211, -29998.697058050686, -9996.442878464926, -9997.539106905071]Scoreは大きな正の値ほど良い相性を表しますので、
シミュレーテッドアニーリング(Simulated Annealing)のスコア群が、正なのに対し、Dirichlet勾配法やランダムアサインはすべて負の値にになっており、SAが圧勝していることがわかりますね。
SAなので、もし仮に、合計人数/チーム人数=非整数 のように割り切れない場合でも、できるだけ各チームの相性スコア合計がバランスよく良くなるような結果が出力されます。
※出力は、真の最良解の近似解となります。
Python
3.11.4で動作確認済み。
ライブラリ(初めに入れてください。)
pip install pandas
pip install matplotlib
pip install scipy無料版
・人員(役職構成割合あり)相性距離グラフのサンプルDataFrame生成部分
・ディリクレ分布のハイパーパラーメータαの勾配法による最適化
・ランダム割り当て
※ファイルの入出力機能なし。
hr_team_assign_test.py
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.stats import dirichlet
from scipy.optimize import minimize
from itertools import combinations
from mpl_toolkits.mplot3d import Axes3D
# クラスタ数
n_cluster = 6
# 各クラスタの座席数
num_chairs = 4
# 人員の数と役職の割合を設定
num_people = 1000 # 実行可能なサイズに調整#課題:10以下でも実行できるようにする。
roles = {"PM": 0.2, "PL": 0.3, "MB1": 0.3, "MB2": 0.2}
# 人員idと役職のリストを生成
people = []
for role, proportion in roles.items():
count = int(num_people * proportion)
people.extend([(i, role) for i in range(len(people), len(people) + count)])
# df_human データフレームを作成
df_human = pd.DataFrame(people, columns=["人員id", "役職"])
df_human['アサイン済み'] = False # アサイン済みフラグを追加
# 役職を数値に変換する前の状態を保持
df_human_original = df_human.copy()
# 役職を数値に変換
role_to_num = {role: i for i, role in enumerate(roles.keys())}
df_human['役職'] = df_human['役職']#.map(role_to_num)
# df_graph データフレームを作成
def calculate_compatibility(role1, role2):
return -num_people*100 if role1 == role2 else np.random.uniform(0, 1.0)
compatibility_matrix = np.array([[calculate_compatibility(role1, role2)
for role1 in df_human['役職']]
for role2 in df_human['役職']])
df_graph = pd.DataFrame(compatibility_matrix)
# スコアの集計用
scores = {"Simulated Annealing": [], "Random Assignment": [], "Optimized": []}
# 相性スコアの二乗総和を計算する関数
def calculate_compatibility_score(people_indices):
score = 0
for pair in combinations(people_indices, 2):
score += compatibility_matrix[pair[0], pair[1]]
return score
# ランダム割り当ての実装
def random_assignment(available_indices):
actual_num_chairs = min(num_chairs, len(available_indices))
if actual_num_chairs == 0:
return [], 0
selected_indices = np.random.choice(available_indices, actual_num_chairs, replace=False)
score = calculate_compatibility_score(selected_indices)
return selected_indices, score
#ディリクレ分布勾配降下法
# 各クラスタに対して最適化を実行
for cluster in range(n_cluster):
# 未アサインの人員のみを対象にする
available_people = df_human[~df_human['アサイン済み']]
available_indices = available_people.index
# 利用可能な人員がいない場合はスキップ
if len(available_people) == 0:
continue
# 座席数が利用可能な人員数を超えないように調整
actual_num_chairs = min(num_chairs, len(available_indices))
# alphaを最適化する目的関数
def objective_function(alpha):
alpha_normalized = alpha / alpha.sum()
dirichlet_dist = dirichlet(alpha_normalized)
probabilities = dirichlet_dist.mean()
selected_indices = np.argsort(probabilities)[-actual_num_chairs:]
return -calculate_compatibility_score(selected_indices)
# alphaの初期値
initial_alpha = np.random.rand(len(available_people)) + 1
# 勾配降下法による最適化
optimized_result = minimize(objective_function, initial_alpha, method='L-BFGS-B',
bounds=[(0.01, None) for _ in range(len(available_people))])
# 最適化されたalphaを使用してスコアを計算
optimized_alpha = optimized_result.x
optimized_alpha_normalized = optimized_alpha / optimized_alpha.sum()
dirichlet_dist = dirichlet(optimized_alpha_normalized)
probabilities = dirichlet_dist.mean()
selected_indices = np.argsort(probabilities)[-actual_num_chairs:]
optimized_score = calculate_compatibility_score(selected_indices)
scores["Optimized"].append(optimized_score)
# 選択された人員をアサイン済みにする
df_human.loc[available_indices[selected_indices], 'アサイン済み'] = True
selected_people = df_human.loc[available_indices[selected_indices]]
# 結果の出力
print(f"Cluster {cluster + 1} Optimized Score:", optimized_score)
print(f"Cluster {cluster + 1} Optimized Selection:", selected_people)
# ハイパーパラメータの探索範囲を定義
initial_temps = [100] # 初期温度の範囲
#initial_temps = [100,10000,100000] # 初期温度の範囲
cooling_rates = [0.95] # 冷却率の範囲
#cooling_rates = [0.85,0.9,0.95] # 冷却率の範囲
iterations = [200000] # イテレーション数の範囲
#iterations = [100000,200000,500000] # イテレーション数の範囲
best_score = -np.inf
best_params = {}
#乱択法 df_human['アサイン済み'] =False # アサイン済みフラグをリセット
# 各クラスタに対して最適化を実行
for cluster in range(n_cluster):
# 未アサインの人員のみを対象にする
available_people = df_human[~df_human['アサイン済み']]
available_indices = available_people.index
# ランダム割り当てを実行
random_solution, random_score = random_assignment(available_indices)
scores["Random Assignment"].append(random_score)
# 選択された人員をアサイン済みにする
df_human.loc[random_solution, 'アサイン済み'] = True
# スコアの比較結果を出力
print("Score Comparison:")
for method, score_list in scores.items():
print(f"{method}: {score_list}")
注意事項
※Out Of Memoryでの停止等いかなる不具合においても無保証であるため、計算可能な問題の規模は、事前にサンプルデータ生成コードを用いて、ご自身のPCやサーバーで限界値規模を商用ご利用前に、ご検証ください。
ライセンス
・MIT Licence
・商用として再配布していただいてもかまいません。
免責事項
本プログラムは無保証であり、使用したことによるいかなる不都合、不具合、損害が出た場合も、一切作者は責任を負いません。全て自己責任とご了承した上でご利用ください。
有料(グリッドサーチチューン済み+ファイル入出力機能あり)
自販機でジュースを買う感じでご購入いただける価格に設定いたしました。
組織単位で購入していただいても個人単位で購入していただいてもどちらでも構いません。(個人単位でご購入していただけると、わたしの励みになりますので、とてもうれしいです。)
※今回SAの対抗馬としてディリクレ分布のαを勾配降下法(Dirichlet Grad)も裏で発案し戦わせておりましたが、scoreがSAに惨敗したため、今回販売のコードには含んでおりません。(乱択よりはよいがSAよりはるかに劣る。)
ここから先は
¥ 200
この記事が気に入ったらサポートをしてみませんか?