
【3分で体験】機械学習の始め方 -サンプルデータの取り込みと検証-

概要
この記事の目的 :機械学習を体験してみたい人にサンプルデータを取り込んで画像の内容を機械に予測させる方法を紹介する
この記事の対象読者:機械学習を行なってみたいが何から始めれば良いかわからない人
事前に必要な知識 :なし
---
体験すること:
犬・猫それぞれ3枚ずつの画像を取り込み機械に学習をさせます。その後、任意の画像を読み込ませ、犬か猫かを予測します。
※犬猫画像はAI生成したものを使用しています
やり方
以下の手順で機械学習体験が完了します。
1.以下のURLをクリック(Googleのプログラムアプリ(無料)に飛びます)
※クリック後、Googleアカウントを所有している場合はログイン。所有していなければ作成する
https://colab.research.google.com/
2.上部タブ「ファイル」→「ノートブックの新規作成」の順にクリック
※ポップアップが表示された場合も無視して「ファイル」ボタンを2回クリックすればOK(1回目のクリックでポップアップが消えます)

3.以下のファイルをダウンロードし、中の画像をcolabにアップロードする
手順:→ファイルダウンロード
→colabのメニューからGoogledrive連携(画像参照)
→Mydriveフォルダ内に「犬」「猫」フォルダを作成
→ダウンロードしたファイル「dog1~3」「cat1~3」を
それぞれのフォルダにアップロード(ドラッグ&ドロップ)
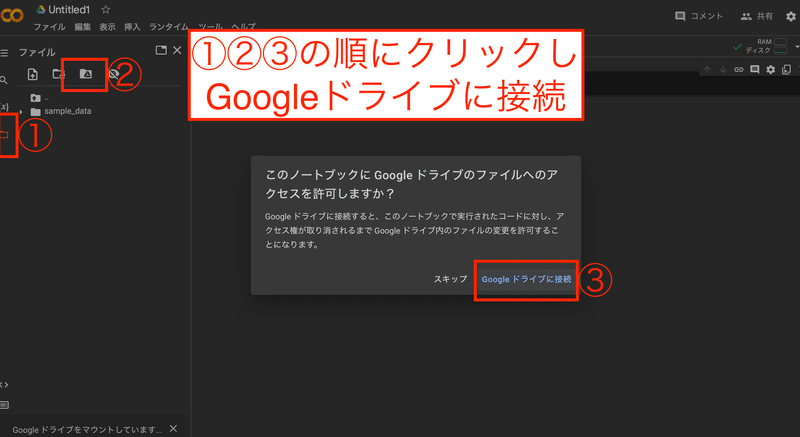



4.再生ボタン▶️の右にある①ブラックボックスに下のコードを全文コピペし、②再生ボタン▶️をクリック(10秒~30秒程度待ちます)

# コピペ用コード
# 必要なライブラリをダウンロードする
import io
import os
import keras
import numpy as np
from google.colab import files
from keras.preprocessing import image
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
from PIL import Image
from sklearn.model_selection import train_test_split
# 学習対象の画像ファイルが置いてある場所の設定をする
base_dir = '/content/drive/MyDrive'
dog_dir = os.path.join(base_dir, '犬')
cat_dir = os.path.join(base_dir, '猫')
# 画像データを読み込む
def load_images(directory, label):
images = []
labels = []
for filename in os.listdir(directory):
if filename.endswith(".png"):
img = image.load_img(os.path.join(directory, filename), target_size=(150, 150))
img = image.img_to_array(img)
img /= 255.0
images.append(img)
labels.append(label)
return images, labels
# 犬猫画像にラベルを設定する
dog_images, dog_labels = load_images(dog_dir, 0)
cat_images, cat_labels = load_images(cat_dir, 1)
# xとyの箱を作り、画像データのラベルを設定する
X = dog_images + cat_images
y = dog_labels + cat_labels
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 各データの形式(文字か?数字か?など)を設定する
X_train = np.array(X_train)
y_train = np.array(y_train)
X_test = np.array(X_test)
y_test = np.array(y_test)
# モデルを定義する
model = Sequential([
Conv2D(32, (3, 3), activation='relu', input_shape=(150, 150, 3)),
MaxPooling2D(2, 2),
Conv2D(64, (3, 3), activation='relu'),
MaxPooling2D(2, 2),
Conv2D(128, (3, 3), activation='relu'),
MaxPooling2D(2, 2),
Flatten(),
Dense(128, activation='relu'),
Dense(1, activation='sigmoid')
])
# 画像のデータを分解し人が読める言語→機械が読める言語に変換
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# 画像を機械に学習させる
model.fit(X_train, y_train, epochs=10, batch_size=16, validation_data=(X_test, y_test))
# ファイルをアップロード
uploaded = files.upload()
# アップロードされた画像のサイズを変更して保存
for filename in uploaded.keys():
img_path = filename
img = Image.open(io.BytesIO(uploaded[filename]))
img = img.resize((150, 150))
img.save(img_path)
# リサイズし保存した画像を読み込む
img = image.load_img(img_path, target_size=(150, 150))
img = image.img_to_array(img)
img /= 255.0
img = img.reshape((1,) + img.shape)
# 予測を行う
prediction = model.predict(img)
# 結果を表示
if prediction[0][0] < 0.5:
print("犬です")
else:
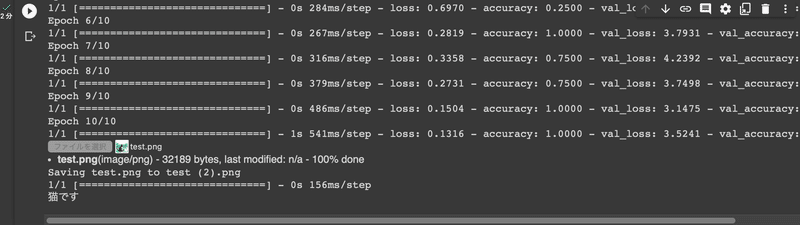
print("猫です")5.下部に表示された「ファイルを選択」ボタンをクリックし、3.でダウンロードした「test.png」を選択しアップロード

6.結果が表示される <完了>
<機械学習および予測はこれで完了しました。以降の内容は解説と応用になります。不要な人はここで読み終えてください。>
1. はじめに
この記事では、PythonとGoogle Colaboratoryを使用して、サンプルデータを取り込んで画像の内容を機械に予測させる方法を紹介します。
まずは実際にプログラムを実行し機械学習を体験しました。
2. PythonとGoogle Colaboratoryの紹介
重複するため以前の記事を参照
3. 今回使用したコードの解説
今回使用したコードの解説を行います。
機械学習に役立つ各種ライブラリを使用し、学習用データを読み込んだ後、任意の画像をアップロードして猫か犬かを予測しています。
大部分は以下コード内にコメントを記載したので、いくつか抽出して別途解説を記載します。
# コピペ用コード
# 必要なライブラリをダウンロードする
import io # ファイルのインプット・アウトプットなどの機能
import os # OS(MacやWindows)との連携機能
import keras # 機械学習に関わるコードがシンプルになる機能
import numpy as np # 統計・計算がシンプルになる機能
from google.colab import files # google colabでファイルの操作ができる機能
from keras.preprocessing import image # 画像データの読み込みやサイズ変更機能
from keras.models import Sequential #予測の過程で使うフィルターに関する機能
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense #上記フィルター関連機能
from PIL import Image # 基本的な画像処理機能
from sklearn.model_selection import train_test_split # 学習用・テスト用にデータを分割する機能
# 学習対象の画像ファイルが置いてある場所の設定をする
base_dir = '/content/drive/MyDrive' # 犬猫フォルダのある場所を指定
dog_dir = os.path.join(base_dir, '犬') # 犬画像の場所を指定
cat_dir = os.path.join(base_dir, '猫') # 猫画像の場所を指定
# 画像データを読み込む
def load_images(directory, label): # 画像の場所を確認しラベルを設定
images = [] # 後ほど画像データを入れるための箱を作成
labels = [] # 後ほど画像データに対応するラベルを入れるための箱を作成
for filename in os.listdir(directory): # 画像の場所を繰り返し確認している
if filename.endswith(".png"): # .pngファイルがあるか確認
img = image.load_img(os.path.join(directory, filename), target_size=(150, 150)) # 画像ファイルを読み込みリサイズ
img = image.img_to_array(img) # 画像を扱いやすい形式に変換
img /= 255.0 # 画像データのpixcel値を適切な範囲内に設定
images.append(img) # 先ほど作成した箱に画像データを入れる
labels.append(label) # 先ほど作成した箱にラベルデータを入れる
return images, labels # 画像とラベルのデータをアウトプット
# 犬猫画像にラベルを設定する
dog_images, dog_labels = load_images(dog_dir, 0) # 犬なら0
cat_images, cat_labels = load_images(cat_dir, 1) # 猫なら1
# xとyの箱を作り、画像データのラベルを設定する
X = dog_images + cat_images # 犬猫画像をxに入れる
y = dog_labels + cat_labels # 犬猫画像のラベルをyに入れる
# 画像データを学習用とテスト用に分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 各データの形式(文字か?数字か?など)を設定する
X_train = np.array(X_train)
y_train = np.array(y_train)
X_test = np.array(X_test)
y_test = np.array(y_test)
# モデルを定義する
model = Sequential([
Conv2D(32, (3, 3), activation='relu', input_shape=(150, 150, 3)), # 画像の特徴抽出
MaxPooling2D(2, 2), # 画像の縮小
Conv2D(64, (3, 3), activation='relu'),
MaxPooling2D(2, 2),
Conv2D(128, (3, 3), activation='relu'),
MaxPooling2D(2, 2),
Flatten(), # 全画像を一面に圧縮
Dense(128, activation='relu'), # 次の行にまとめられた画像の特徴を渡す
Dense(1, activation='sigmoid') # 受け取った画像から犬と猫どちらの特徴に近いか出力
])
# 画像のデータを分解し人が読める言語→機械が読める言語に変換
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# 画像を機械に学習させる
model.fit(X_train, y_train, epochs=10, batch_size=16, validation_data=(X_test, y_test))
# ファイルをアップロード
uploaded = files.upload() # 予測したい画像のアップロードボタンを表示
# アップロードされた画像のサイズを変更して保存
for filename in uploaded.keys(): # ファイル名を取得
img_path = filename # アップロードされた画像の場所を指定
img = Image.open(io.BytesIO(uploaded[filename])) # 画像を開く
img = img.resize((150, 150)) # 画像を150x150ピクセルにリサイズ
img.save(img_path) # リサイズ後の画像を上書き保存
# リサイズし保存した画像を読み込む
img = image.load_img(img_path, target_size=(150, 150)) # 画像の読込およびサイズ変更
img = image.img_to_array(img) # 画像データを数値に変更
img /= 255.0 # 数値データの範囲を適切な値に設定
img = img.reshape((1,) + img.shape) # 画像や画像を入れている場所のサイズ・形を変更
# 予測を行う
prediction = model.predict(img) # predictionに予測結果を代入
# 結果を表示
if prediction[0][0] < 0.5: # predictionと値を比較
print("犬です") # 0寄りの場合(0~0.5)
else:
print("猫です") # 1寄りの場合(0.50...1~1)①kerasライブラリ(便利機能)
今回はKerasライブラリを使用しました。
・Keras Documentation(公式ドキュメント)
import keras
from keras.preprocessing import image
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Flatten, DenseKerasは機械学習をより簡単に行うためのライブラリです。コードと読み比べるとわかりますが、今回学習周辺の機能はほぼKerasを使用しています。
同様の機能を持ったライブラリとしてはPytorchがあります。どちらも基本機能に大きな違いはありませんので、どちらも触ってみて自分に合っている方を使うのが良いでしょう。
②フォルダ設定
学習用データはGoogleDriveに置いており、配置場所の間違い、記述の間違い、拡張子の違い、GoogleDriveとの連携ができていないなどがあるとうまく動きません。
もし誤りがあった場合、途中まで進んでも、画像データの分割部分でエラーになります(データが存在しないため学習用・テスト用のデータ分割が不可)。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)③データ形式設定
ここも注意したい点です。各データ用の箱(x_trainやy_trainなど)のデータ形式を適切に設定しないと、後のフェーズで中身が正常に読み込めずエラーになります。
# 各データの形式(文字か?数字か?など)を設定する
X_train = np.array(X_train)
y_train = np.array(y_train)
X_test = np.array(X_test)
y_test = np.array(y_test)trainのみ設定してtestの設定を忘れていた、ということもあり得るので必ず忘れずに行いたい部分です。
4. 今回の出力データの解説
今回は学習データが少なすぎるので、正確性には期待できません。実際に機械学習を行う際は(ものによりますが)1万点以上など、もっと多くのデータを使用することになると思います。
# 結果を表示
if prediction[0][0] < 0.5: # predictionと値を比較
print("犬です") # 0寄りの場合(0~0.5)
else:
print("猫です") # 1寄りの場合(0.50...1~1)また、最後に選択する予測対象ファイルは概ね60kb以下であれば別の画像でも問題ありません。
5. まとめ
本記事では、PythonとGoogle Colaboratoryを使用して機械学習と予測を行う方法を紹介しました。
次のステップとして、Keras以外のPytorchなどよく使われるライブラリを使ってみたり、より多くの学習ファイルを使用した予測なども試してみるのがおすすめです。
この記事が気に入ったらサポートをしてみませんか?