
With作品解説~Can AI understand novels?編②~

展示会『With』を開催しました
2023年9月にメディアアート集団「WONDEMENT」を立ち上げました。
↓下記noteで設立の細かい話をしています。
そして2024年3月23〜24日の2日間に渡ってWONDEMENTとして2回目の展示となる『With』を代官山のギャラリー「UPSTAIRS GALLERY」で開催しました。

本展示では4つの作品を展示し、自分が全体のプロデュースと2つの作品制作に携わっています。
今回はその『With』で展示し、自分が制作に携わった「Can AI understand novels?」の作品解説後編となります。
前回は作品ん構想やコンセプト、そして元となった作品の選定過程について紹介しました。
今回はそこから実際にAIを活用して制作していった過程を解説していきます。
要約させる
作品に使用する小説として宮沢賢治の「注文の多い料理店」を選びました。

これを要約していき、画像生成を行うのですが、本作品ではボリュームも鑑みて合計で10個のチャプターに要約し画像生成を行うことにしました。
そこで小説の文書を丸々コピーしChatGPTに読み込ませ、
"以下の文章を10個のチャプターに要約してください"という指示をします。
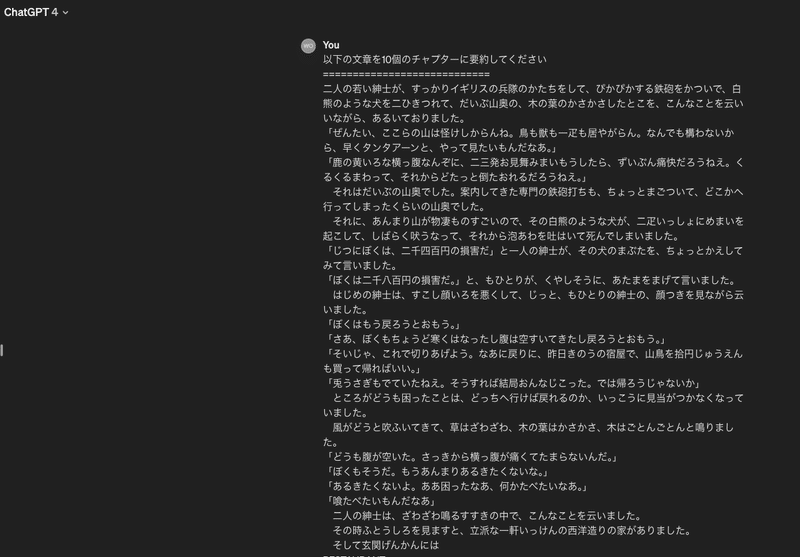
すると読み込ませた文書をベースに要約を行い、10個のチャプターに分解したうえでそれぞれのチャプターの要約文を出力します。

絵を生成する
要約が完了したら画像を生成していきます。
これも難しいことはなく"ChatGPTに"チャプター1の画像を出力して"
といった形で指示を与えて画像を生成させます。
ただここで1点問題が発生しました。
当初は"各チャプター事に画像を1枚ずつ生成して"
という風に10枚一気に生成させようとしたのですが、流石に重い処理だったのか数枚生成したところでエラーが起きてストップしてしまいました。
そのため各チャプター事に指示を出して順番に生成させていく手法を取っています。
しばらくすると下記のように指示で指定したチャプターに応じた内容の画像が生成されます。

要約させたからそのまま画像を生成出来るという点はChatGPTの様なマルチモーダルAIだからそこ出来る芸当です。
ちなみに下記画像は生成過程で試行錯誤した中で生成されたボツ画像ですが、画像を開いて右上にある"iマーク"を押すと生成される時に使用されたプロンプトを見ることが出来ます。
足りない部分を補う
これで10個に要約されたチャプター毎の画像を生成することが出来ました。
しかし現状では色々な課題を抱えています。
例えば
解像度的に印刷に耐えられない
最終的にはA4で印刷をするので、密度を350dpiと仮定すると4093×2894ピクセルが必要となり全く解像度が足りません。
そこで印刷に必要が解像度にするために目伸ばし作業が必要となります。
目伸ばしの方法は様々ありますが、今回はAIをテーマとした作品ということでAdobeのAI機能を使って作業しました。
細かく説明すると長くなってしまうので、詳細は別のnoteとして解説する予定です!
比率が合わない
A4の比率は1:√2(1.41)です。
生成された画像は正方形なのでA4の比率に合わせるとなると縦又は横に絵を拡張する必要があります。
そこで今回はPhotoshopの「コンテンツに応じた塗りつぶし」を利用しました。
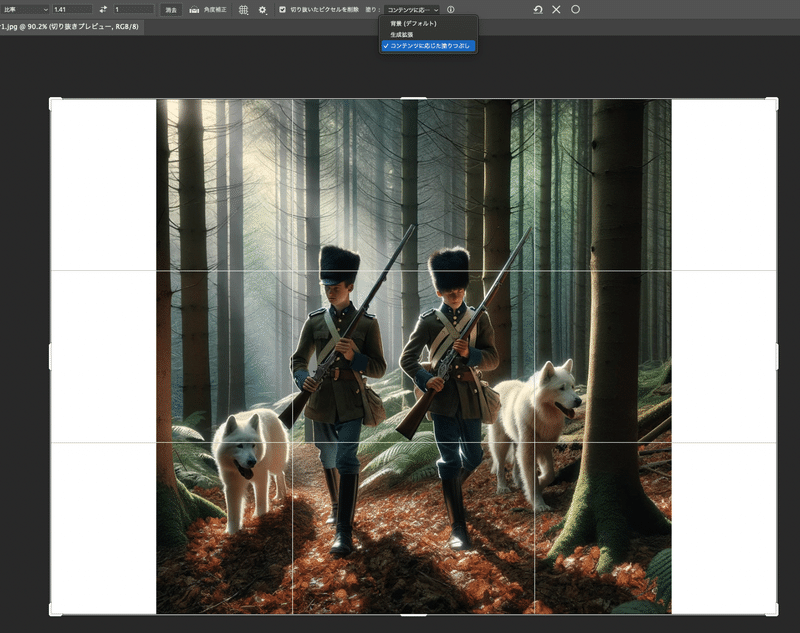
やり方としては切り抜きツールで比率を任意のものに設定し、最終的に出力したい形に広げたら上部にあるプルダウンから「コンテンツに応じた塗りつぶし」を設定して実行します。


上がChatGPT(DALL・E 3)で生成した画像、下がそれをPhotoshopの"コンテンツに応じた塗りつぶし"で拡張した画像です。
テイストの違いやつなぎ目の違和感などはなく自然に拡張されていることが分かります。
この処理を他の画像にも行い、10枚の画像を作成していきました。
冊子を作る
元となった小説を選定する条件として
「多くの人が知っていてストーリーをイメージ出来る作品であること」
ということを決めていました。
AIが誰が見てもなんの作品か分かる絵を出力してくれれば良いですが、
実験的な作品ということもあってその確証はないため、正解を知った時にしっかりと内容をイメージ出来るものである必要があると考えたからです。
そしてどんな作品をテーマとしていたのかを説明したい、生成したプロンプトなどをまとめた冊子を作成し、作品を観賞する際に一緒に見てもらえるようにしました。


画像毎にプロンプトと要約された文章を掲載し、作品を見ながらその制作過程などを理解できる様にしています。
結果
本作品は作品タイトルにもあるように
「AIが人の書いた小説を他人に説明出来るほどに理解出来るのか」
という実験的な要素も含んでいます。
実際に会場に来ていただいた方々は生成された画像を見て元の小説の内容を理解することが出来たのかどうかが重要ですが、結果としては
理解できない
というのが今回の結果だったと思います。
文章を丸ごとインポートしているので、要約された文書やそこから起こしたプロンプトは正確性を保つことが出来ていました。
しかし今回分かったのは
AIは前後の話やストーリー全体の設定を読み取ってくれない
ということです。
生成された画像の前後関係までは考慮できないため、画像の中に登場している人物に統一性がなかったりしていて全体を一つの物語として人が認識出来るレベルには出来ていませんでした。
最後に
ここまで2回に分けて2nd展示『With』で展示した
「Can AI understand novels?」について解説してきました。
WONDEMENTとしては初めて生成AIを作品制作の主軸に活用した作品ということもあり、制作過程も自分にとっては実験的な要素を含んだ制作となりました。
生成AIは現在のトレンドであるとともに、クリエイティブに大きな影響を及ぼし始めている存在です。
そのため、それを用いてどういった事が出来るのか検証し、作品と形で様々な人に触れてもらえる機会を創出することがWONDEMENTのビジョンである「誰が表現できる世界を作る」の達成に近づく取り組みだと思います。
次回の作品解説は少し脱線して本作品で行った「目伸ばし」について取り上げる予定です。
それではまた!
この記事が気に入ったらサポートをしてみませんか?