
2020-07-15 Data Engineering Study #1 #DataEngineeringStudy

2020/07/15 に開催された Data Engineering Study #1 「DWH・BIツールのこれまでとこれから」 のイベントレポートです。
●イベント概要
本イベントは、Infra Study Meetup を運営する Forkwell と、分析基盤向けデータ統合SaaS「trocco」の開発・運営を行う primeNumber による共催イベントです。データ分析に精通した講師をお招きし、データ分析基盤の「これまで」と「これから」を学ぶことを趣旨として開催いたします。
プログラム第1回「モダンなDWH/BIツールの選び方と、実際の運用事例」
分析基盤において、必須の構成要素であるDWHとBIツール(可視化・ダッシュボードツール)。昨今では多くのツールが存在し、これから分析基盤を作る方にとっては最も悩ましい選択を強いられるでしょう。
このセッションでは水先案内人にゆずたそ氏をお招きし、データ分析基盤の全体像を説明して頂いた上で、DWH/BIツールの位置づけを確認します。
その後、実際にDWH・BIツールを最大限活用されている2社に、選定の理由・運用してみてのリアルな声を発表いただきます。
■Data Platform Guide - 事業を成長させるデータ基盤を作るには
ゆずたそさん

・今日の発表内容
SoftwareDesign 2020年7月号に準拠
●データ基盤人材は年々増えている
・ニーズが増えている
・実際にこういう事やっているよという人も増えてきた
・注目度の上がっている分野
●最初の落とし穴
・どうやって基盤を作ればよいかわからない
・つくったのに全然使われない
●苦い思い出
・いろいろ考えて最強のダッシュボードを作った
1週間で全然見られなくなった
・最初に描いた基盤は使われない
●本日のゴール
・使われるデータ基盤の勘所を学ぶ
●Why
・データ基盤をなんのために作るのか
顧客のため
現場のため
経営のため
・現場→経営→顧客に価値を提供していく
・事例:営業活動の指標を変えたらどうなるかの分析
契約をとったらインセンティブ
→ 契約後に3ヶ月後に解約されなかったら
・営業、解約のデータをBigQueryに統合
DataPortalで分析
・データ活用をドライブする基盤
複数データソース、複数ユースケースを繋ぐ
1:1なら直接参照で済む
複数だと基盤が必要
・データはどんどん複雑になっていく
部署ごとに売上がずれる
消費税、解約、返金
チームで数値が変わってくると
横断での意思決定は難しい
●What:手軽にデータを参照できるツール
とりあえずデータを集めましたではNG
ModelとViewを分ける
適切なViewは部署や役割によって異なる
・データを統合するというのと合わせて
どうしたら使いやすいかを考える
・その人にとって何がベストか
試さないとわからない
現場と向き合うのが重要
●What:安全にデータを受け渡せるシステム
・データの階層を分ける
データレイク
加工せずに1つのシステムに集約したもの
加工方法を間違ったときに
加工前のデータが残ってないと直せない
データウェアハウス
複数データを統合・蓄積して、分析向けに整理したもの
データマート
特定の利用者向けに分離したもの
・開発プロセスは挟み撃ち
処理の流れと違ってくる
事業やシステムの全データをコピーする
ダッシュボードやレポートと対になる
どうまとめるかが決まる
・BigQueryの命名規則で管理
enokilog__datalake__mysql.users
●What:安心してデータを扱えるプロセス
・部署や用途ごとに暗黙的に期待されている品質を洗い出す
毎朝見るのであれば、朝までにレポートを出力しておく必要がある
明確に話されないけれど存在する期待
・インシデント対応の仕組み化
優先順位
深夜休日でも対応
案件を止めて対応
案件と調整
対応手順
再実行
代替データ案内
関係者にレポート
・オペレーションを型化する
不安感が減る
利用者からすると安心感がある
・品質を計測する
結果をモニタリングして改善、悪化を止める
・定期的に見直す
定期のミーティングに改善を含めてしまう
●How:データの取得元となる対象
・webサービスの場合
ユーザー
画面
アクセス解析ツール
サーバーサイドアプリ
アプリケーションログ
データストア
webサーバログ
・注意:元データの品質に注意しよう
元のデータがないと分析では利用できない
・注意:元データの仕様を管理しよう
DBのテーブルやカラムに一言コメントがあるだけでも分析は楽になる
・注意:手入力のデータにも目を向けよう
手入力するデータにも向き合う必要がある
●How:データを集約するテクノロジー
・技術要素
ETL、DWH、ワークフローエンジン、BIツール
・BIツール
データの分析や可視化
選定の観点
予算がある / 無料 / 使い慣れたツール
構築の有無
・DWH
大量データの保存や集計
選定の観点
処理規模
クラウド / オンプレ
サポート有無
・ETL
データの抽出・変換・格納
選定の観点
定期バッチ / ストリーミング
クラウド / オンプレ
コード / 画面
・ワークフローエンジン
処理の流れを管理
選定の観点
コード / GUI / その他
どれも癖があるので手に馴染むものを
●事例
・スタートアップ、大手、メガベンチャーの事例を書いてます
・時間がないので興味がある人はスライド読んでください
●おわりに
・利用者に寄り添って最適なテクノロジーを活用していく
・この領域は総合格闘技
エンジニアリングの面白さや難しさが詰まってます
●QA
・BigQueryのview運用とBIツールへの知見の蓄積で
2重管理になってしまうのはどうすれば?
2つのフェーズに分ける
アナリストがBIツール上で試行錯誤
ロジックをデータウェアハウス側に取り込む
スピードと品質のバランスが取れる
・ゼロからDWHやBIを作り始める上で
まず何から始めればよいでしょうか?
目的の整理
データを入れたあと、結局これをどうする?になりがち
上司などと目的を整理すると
使われるもの価値があるものがつくれる
■スポンサーセッション primeNumber
■ZOZOTOWNの事業を支えるBigQueryの話
塩崎 健弘さん
●ZOZO
・ZOZOTOWN
・WEAR
・MS マルチサイズ
身長と体重を入力すると
理想のサイズが見つかる
・ZOZOMAT
スマホで足の3Dサイズを計測
ピッタリのサイズを
●データ基盤
・構成
基幹の複数SQLServer
→ 中間DB SQLServer
→ BigQuery
→ PowerBI, Lookerなど
・基幹の複数DB → 中間DB
ETL: bcp
SQL Serverのバルクコピーツール
ワークフローエンジン: Digdag
TreasureDataのOSS
インフラ: オンプレ
・中間DB → BigQuery
ETL: Embulk
ワークフローエンジン: Digdag
インフラ: AWS
移行前がRedshiftだったので
・BI
PowerBI
Looker
ガバナンスで利用
・AIもやってます
検索結果のパーソナライズ
おすすめ順の並べ替え
類似アイテム検索
Cloud Composer + GKE
●Amazon Redshift から Google BigQuery に移行
・日次レポート、月次レポートなら使えていた
・ZOZO研究所発足
Try&Errorのサイクルが早い
・BigQueryなら
インデックスを事前にはらなくても力技で回せる
●オンプレDWH vs クラウドDWH
・Redshiftの前から使っていた
メルマガなどに利用
・クラウドだと圧倒的に運用が楽
・一回買うと冗長構成などでコストは掛かる
●BIツールの使い分け
・Power BI
オフィシャルなBI
・Looker
データガバナンス
・Redash
SQLを書けるエンジニアチーム
グラフ化したいがBIチームに依頼すると長いのでつなぎ
・Google Sheets
根強い人気
●Looker導入
・SQLでデータ集計処理を記述していたことの問題点
WHERE句のみを切り出して再利用できない
カラムの扱いが違う
など
・LookML
WHERE句のコピペ防止
○○_idに名前をつける
Gitでバージョン管理
・ETLバッチとLooker連携
ETLの完了をPubSubにpublish
・tech blogに書いてます
●懺悔
・Redshift時代
S3→Redshiftは知っている
中間DBの存在は知っている
基幹DBは秘境
・取りやすかったS3からデータを取得していた
無加工だと思ったら、一部加工されていた
・ゆずたそさんのブログそのまま書いてあった
●ここが辛いよBigQuery
・コスト
噂を聞きつけた人が触り始めて
気軽な SELECT * で数千円が溶けた
検知して、違反者講習へ
・セキュリティ
IAMで設定できる最小粒度はデータセット
権限境界とGCPのプロジェクトを合わせておくと幸せ
・コスト予測
Flat-rate pricing
でコンピューティングコストが固定になる
●リアルタイム系データ基盤紹介(構築中)
・更新タイムスタンプで差分反映
更新ルールが統一されていなくて諦めた
・Change Trackingで変更があった主キーをpubsubへ
HAにしたので、pubsubには必ず2つ入る
・Dataflowで重複排除
行の値からハッシュ計算
・差分データをBigQueryにStreaming Insert
Dynamic Destination
・読み出し口
差分情報だけのPubSub Subscription
BigQuery
●QA
・今注目しているサービスや技術は?
AutoML、BQ omni
・データエンジニアリング自体に避けている時間の割合は?
他のシステムも見ている
マーケティング系とデータ分析は相性が良いので一緒に
避けている時間は半分もない
チーム 4人
半分はデータではないもの
リアルタイム系データ基盤に一人がフルコミット
・BIツールはどう使い分けるべき?
データ基盤としてはたくさんのBIにつながるものに
アドホックとダッシュボードは自然と別れていく印象
■スポンサーセッション Forkwell
■freeeのデータ基盤におけるDWH/BIの運用事例紹介
中山 裕介さん
●freee
・スモールビジネスを世界の主役に
・昨年末に上場
・7つのメインプロダクト
はじめる
開業フリー、会社設立フリー
運営する
フリーカード、会計フリー
育てる
マイナンバー管理フリー、人事労務フリー
納税する
申告フリー
●データ基盤紹介
・特徴
様々なユーザー
データサイエンティスト、MLエンジニア
PM、サポートなど
KPIの分析などにも利用
多様なデータソース
プロダクトのデータ以外にも必要に応じて
他社のクラウドサービスを利用することにも積極的
セキュリティ大事
センシティブなデータが多い
セキュリティレベルに応じて、マスキングやカラムを落としている
・現状のデータ基盤の全容
データソース
RDS/Aurora, S3
外部SaaS
データ抽出・加工・取り込み
S3: Data Lake
EC2, Lambda, ECS, Batch, Glue
Digdag
DWH
Athena
Redshift
BI
redash
●運用事例紹介
・内製のBIツールを開発していたが
処理が終わらないのでredashを採用
・Redshiftの運用
データ
カラム落とし
文字列データは取り込まない
ホワイトリスト形式で絞り込み
問い合わせで個人情報を入れてしまうこともある
マスキング
クラスター3台を使い分け
primary
毎朝snapshot作成
replica-1
replica-2
redash用
良いところ
ノード単位の起動時間課金
ちょっと集計クエリを回す分には良い
S3との相性が良い
苦労しているところ
キャパシティプランニング
気づいたらディスクフル
テーブルのチューニングが必要
DISTSTYLE / DISTKEY / SORTKEYなどの指定
再分散が起こるとクエリが重い
・Redashの運用
データソースは都度追加
サクッと出せるので便利
EC2にDockerで稼働
Mackerelで監視
全社員に開放
エンジニアから企画までSQLをゴリゴリ書いている
使う人が気を使ってくれて爆弾クエリはない
良いところ
インスタンス費用だけ
有償版で500名だといくら掛かるか
定期的にKPI集計用クエリを回す分には十分
Spreadsheetへの集計結果も連携可能
苦労しているところ
SQL書く前提のツール
普及に限界
営業の人
スケジュール実行のクエリが同時多発で実行されQueueがつまる
●こういう方におすすめ
・Redshift
予算決定に確実な金額が必要
全社的にAWSを使っている
・Redash
無料で使ってみたい
サクッと簡単な可視化
SQLを書くことが苦でない
metabaseも良いです
●今後
・Redshiftの新しいインスタンスタイプ
・データカタログ整備
・ETL周りの処理のリファクタ
●QA
・日々進歩している製品、サービスの情報キャッチアップの方法や
選定眼の鍛え方は?
twitterで一次情報を拾ってます
選定時の事情や、組み合わせによる
・ダッシュボードをほか担当者に引き継ぐ際の注意点は?
目的の共有と独自項目の説明
Google Docにチョロっと書いたり
redashだとクエリにコメント入れたり
・未経験者がデータエンジニアになるための過程と学習方法は?
パスは2つ
社内の異動
データ基盤チームを立ち上げる
未経験を採用している企業に応募
学習方法
キャッチアップ
データ基盤を自分で作ってみる
・ゆずたそさん
異動や転職はなるほど
個人だと大量データを扱える環境が遠い
■感想
以前にDXの情報を整理したときに挙げた、DXプロジェクトの種類、データ活用のすべてで、データマネジメントとデータ基盤がベースになってくると考えています。
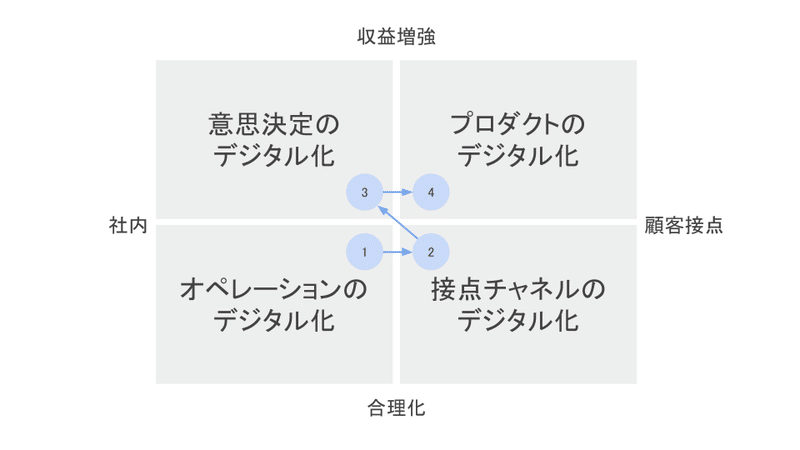
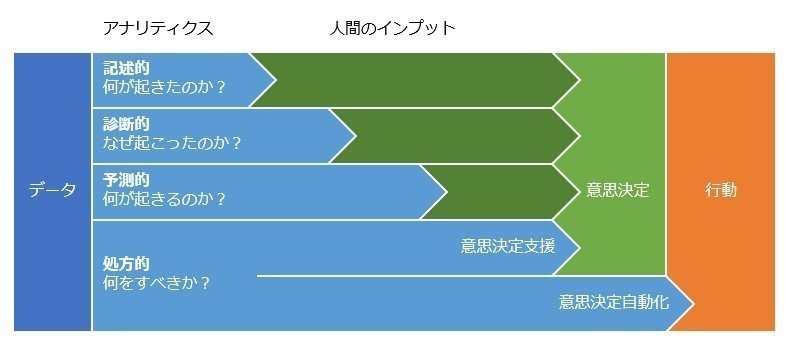
最前線を走っていただいている皆さんのおかげで、データ基盤がどうあるべきか、どう成長させるべきかの型が見えてきたのを感じました!
どうつくるかの部分もこれから、利用者を顧客と捉えて、顧客向けのシステム開発と同様に型が出来上がってくるのだろうな、と楽しみです。
登壇者の皆さん、運営の皆さん、ありがとうございました!
いつも応援していただいている皆さん支えられています。