
『Pythonによるはじめての機械学習プログラミング』ー現場で必要な基礎知識がわかる【40ページ】

こんにちは!
@tatsushimです。
共著で書かせていただいた、先月4/23に発売の『Pythonによるはじめての機械学習プログラミング[現場で必要な基礎知識がわかる]』(表紙がジェンガなので、「ジェンガ本」と呼ばれたりしています)の一部を無料公開しようと思います。(※無料公開期間は終了し、現在は有料noteになりました)
※ 編集の方には了承いただいております
※ noteに転記した関係で一部書籍版とは微妙に編集されている箇所もあります
※ 一定期間経ちましたら有料noteにする予定です → 有料化しました
なぜ公開をするのか?
公開する3.1章と3.2章は私が執筆した箇所で、書籍では約40ページ分の内容になります。
「Pythonで機械学習にふれて、できることを体感してもらうこと」がメインの内容となっており、コンセプトを伝えて多くの方にこの本を手にとってもらいたいと考え、公開するに至りました。
・機械学習はどんな課題を解決することが得意なのか?
・そのためにはどんなステップがあるのか?
・それぞれのステップでどのような知識が必要なのか?
といった全体像を解説しておりますので、ぜひご覧になっていただけますと幸いです!
読んでいただいた方々の声
実際に本を読んでいただいた方々からの書評をご紹介します。
BASE株式会社 CTO えふしんさん
全部を読んだからと言って、決して本書一冊でプロになれるわけじゃないよ、でも、実戦で必要なことはしっかり書いてあるよということを学ぶことができるだろう。そして、この先に進みたければという人に読むべき書籍や論文のポインタが示してある。等身大で誇張も矮小もせず機械学習の入り口について語っている良書だと思う。
サークルアラウンド株式会社 CEO 佐藤さん
とりあえずこれまで「機械学習難しそうだしよくわからない言葉いっぱい出てきそうだからなぁ」と敬遠していたシステム開発者だったらこの"ジェンガ本"は一度目を通してみて損がない一冊だと思います。弊社トレーニングで機械学習コース作るときは教材にしたいです。
そもそもどんな本なのかは前回のエントリーにまとめさせていただきましたので、良かったらそちらもご覧になってみてください!
以下、本文になります。なお、本文のサンプルコードはGitHubで公開しております。
3章 scikit-learnではじめる機械学習
3.1 機械学習に取り組むための準備
3.1.1 機械学習とは
Googleをはじめとする、多くのテクノロジーカンパニーは機械学習を使用している、ということを耳にしたことのある方は多いでしょう。では、機械学習とはどのようなものなのでしょうか? 機械学習とはその名が表す通り、コンピュータ(機械)がデータから学習した結果、そこから規則など(数学的モデル)を見つけ出すことです(図3.1)。
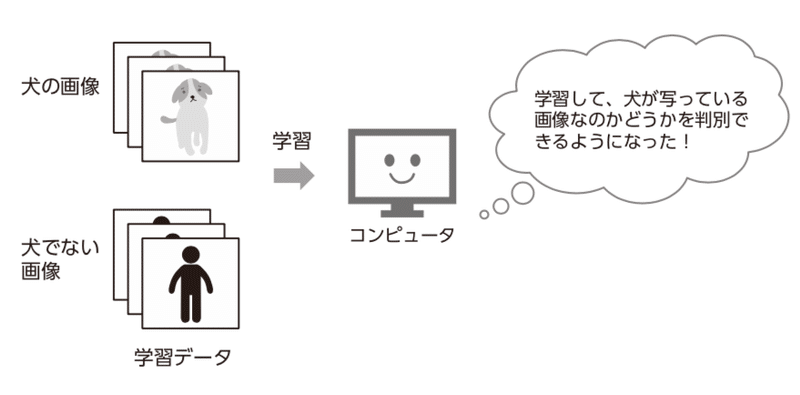
図3.1 機械学習の概念図
3.1.2 機械学習を使うメリット
機械が見つけ出した規則を用いることで、新たなデータに対して予測や分類ができます。機械学習を使うメリットには次が挙げられます。
● 人間が目視で発見することが難しい数学的モデルの発見・構築(図3.2)
● 単純なルールで決めた方法よりも、高精度な予測や分類の実現(図3.3)
● 上記を利用した予測や分類の自動化によるコスト削減
機械学習の具体的な事例として、図3.2、図3.3のような事例が挙げられます。
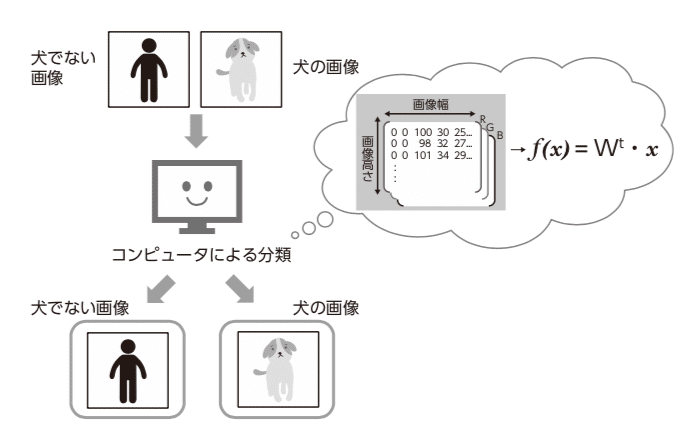
図3.2 人間が目視で発見することが難しい数学モデルの発見の例
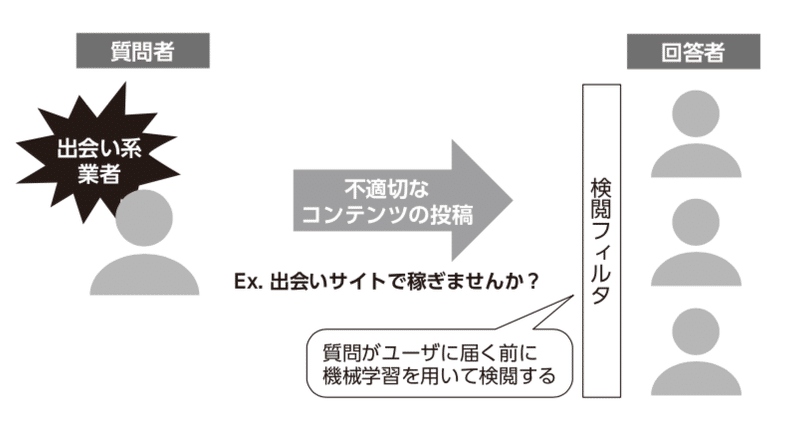
図3.3 Q&Aサイトにおいて単語のみの単純なルールで決めた方法よりも、機械学習を使って高精度な分類をしている例
機械学習は人間では処理できない量のデータを短時間で処理し、現実社会における、情報のレコメンドや分類といった課題に利用されています。
3.1.3 機械学習を使うデメリット
ここから先は
¥ 400
この記事が気に入ったらサポートをしてみませんか?